データマイニング(Data Mining) | Webクローラ | ScrapeStorm
摘要:データマイニングは、大規模なデータセットから貴重な情報を抽出するプロセスです。 統計、機械学習、人工知能、その他の技術的手法を使用して、データ内のパターン、ルール、傾向、または隠された知識を自動的に発見します。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データマイニングは、大規模なデータセットから貴重な情報を抽出するプロセスです。 統計、機械学習、人工知能、その他の技術的手法を使用して、データ内のパターン、ルール、傾向、または隠された知識を自動的に発見します。

適用シーン
データマイニングは、市場分析、リスク管理、医療診断、推奨システム、その他の分野を含めて広く使用されており、機関や企業がより多くの情報に基づいた意思決定を行うのに役立ちます。
メリット:データマイニングは、大規模なデータから有用な情報を抽出し、より正確な予測と意思決定を支援し、効率と競争力を向上させることができます。 また、潜在的な機会の発見、リスクの軽減、パーソナライズされたエクスペリエンスの向上にも役立ち、さまざまな分野の問題を解決する上で幅広い応用価値があります。
デメリット:データマイニングでは大量の個人データへのアクセスが必要となるため、プライバシーに関する懸念が生じる可能性があります。 さらに、データマイニングに依存する意思決定システムにはエラーが含まれる可能性があり、不正確な結果や決定につながる可能性があります。
図例
1. データマイニングの概念図。
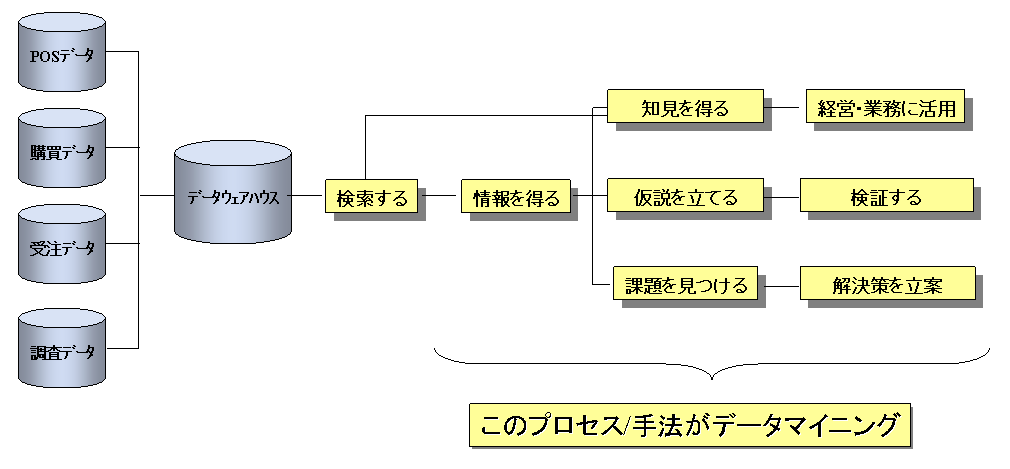
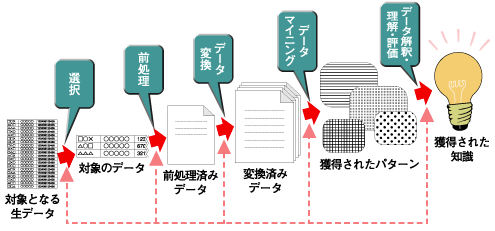
2. データマイニングの流れ。
関連記事
参考リンク
https://www.office-nbi.com/reference/analysis/dataminig/