【フローチャートモード】コンポーネント「データ抽出」の使い方 | Webクローラ | ScrapeStorm
摘要:本文では、「データ抽出」ボタンの機能と運用が紹介します。プライミング必要なし、使いやすいです。 ScrapeStorm無料ダウンロード
「行動コンポーネントとは」チュートリアルでは、ScrapeStormフローチャートモードのさまざまな行動コンポーネントの機能と使用法を紹介しました。 本文では、主に行動コンポーネントの「データ抽出」コンポーネントを紹介します。
「データ抽出」コンポーネントは、Webページからデータを抽出するために使用されます。 このコンポーネントは、単独で使用することも、「ループ」コンポーネントまたは「判断」コンポーネントと組み合わせて使用することもできます。 単独で使用する場合、単一ページのデータを抽出するのに適しています。 一緒に使用すると、すべてのページのデータを抽出するのに適しています。
このコンポーネントの設定には、フィールドリストと抽出範囲が含まれます。 具体的な設定は次のとおりです。
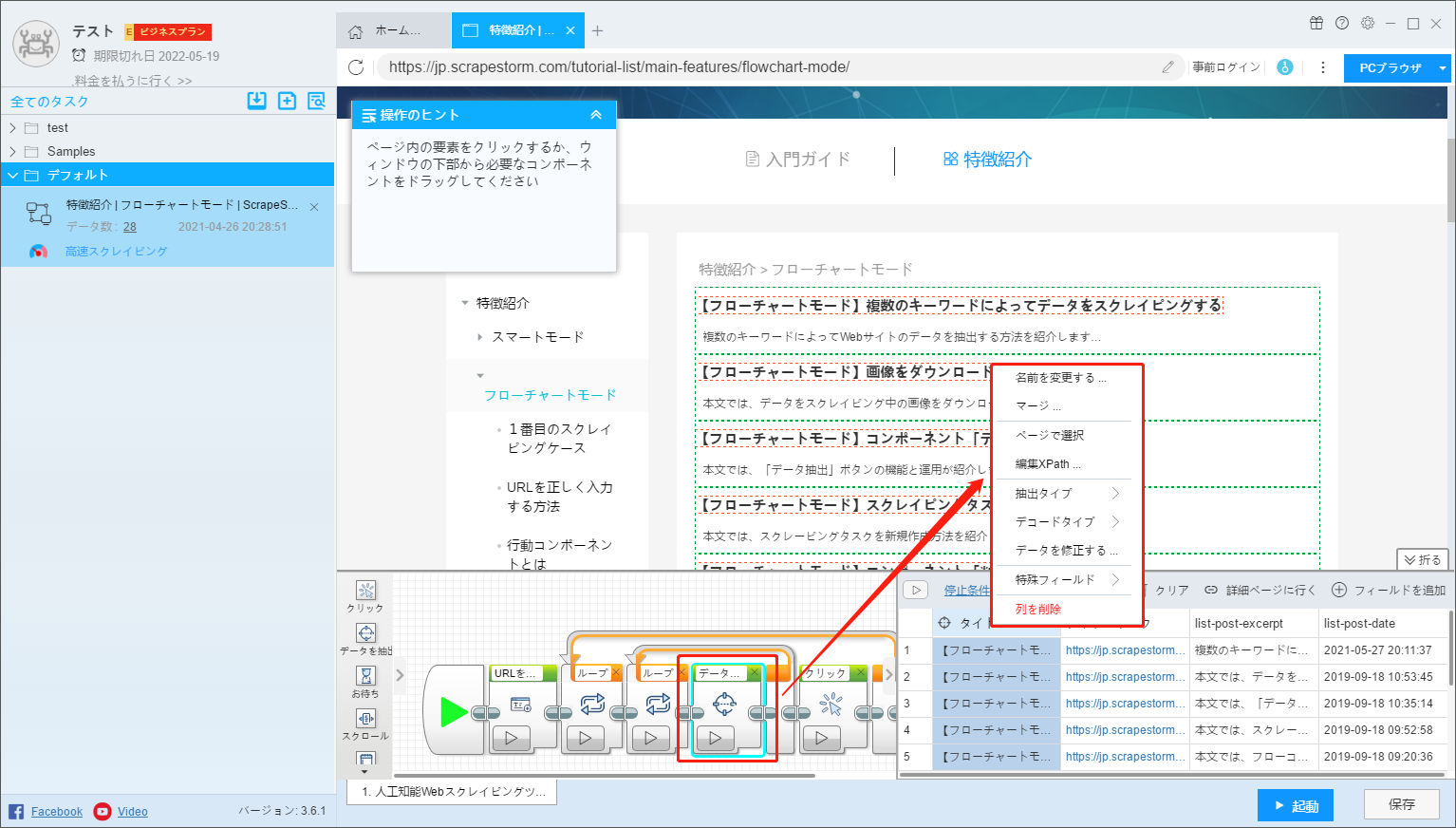
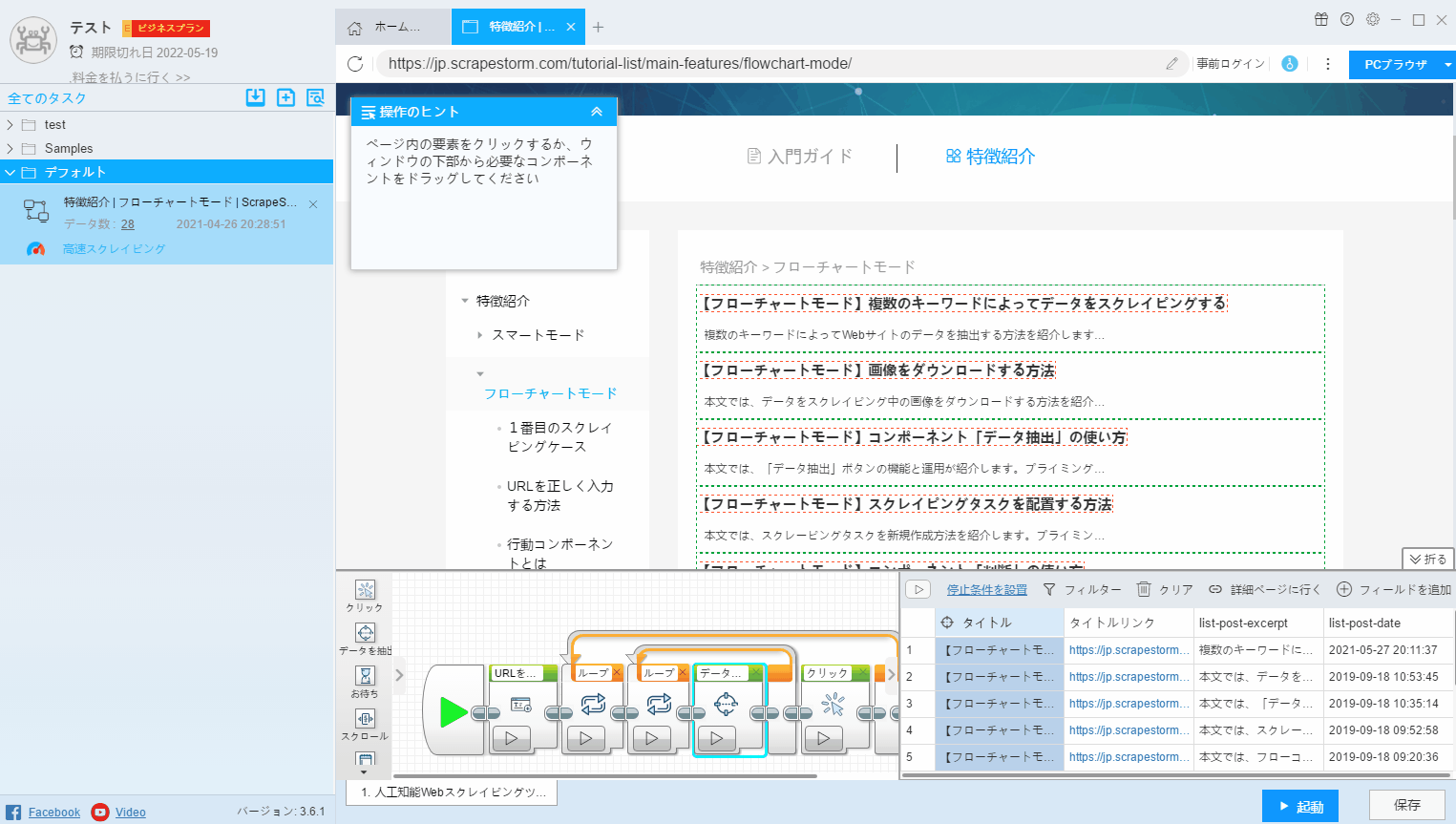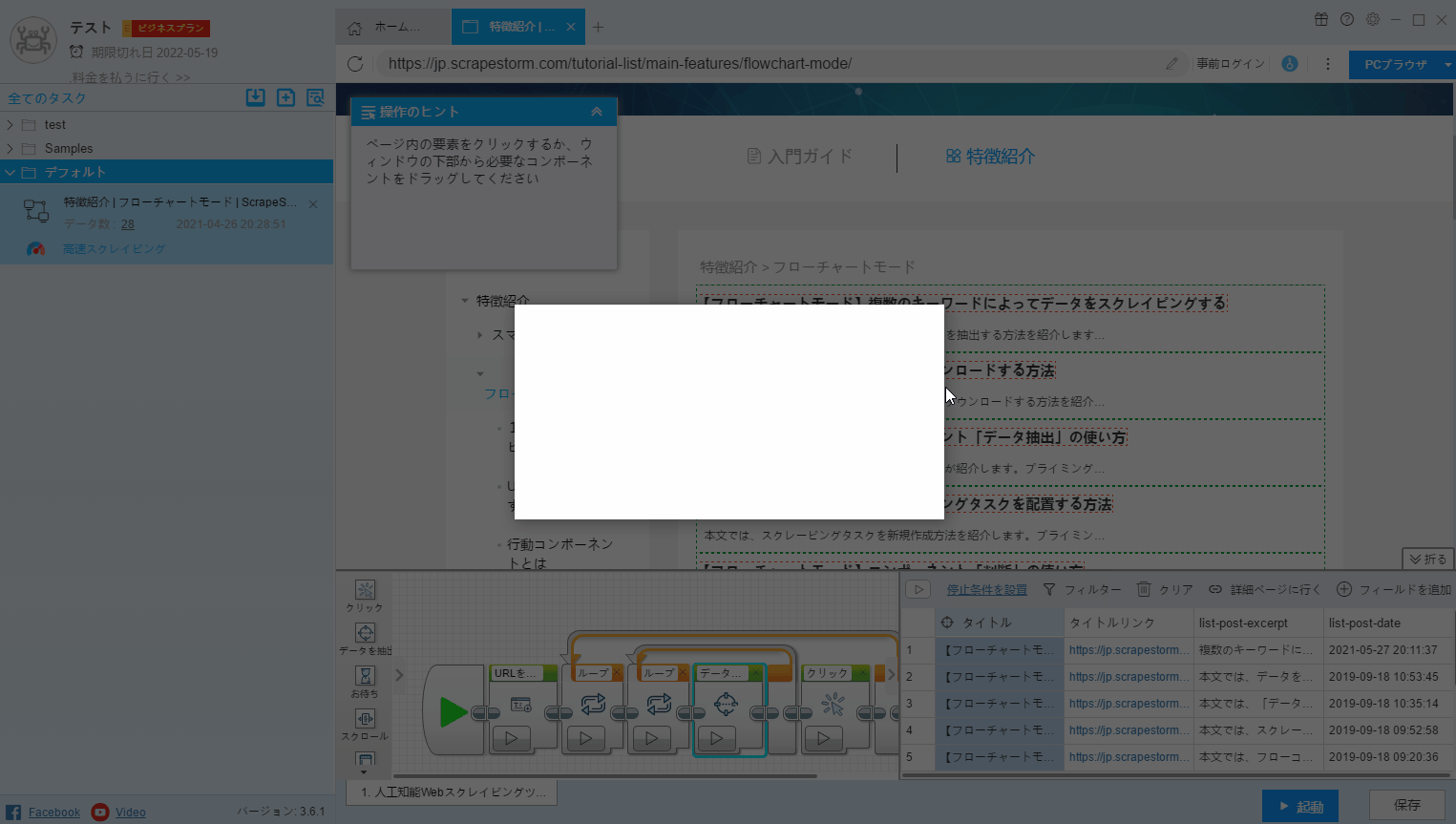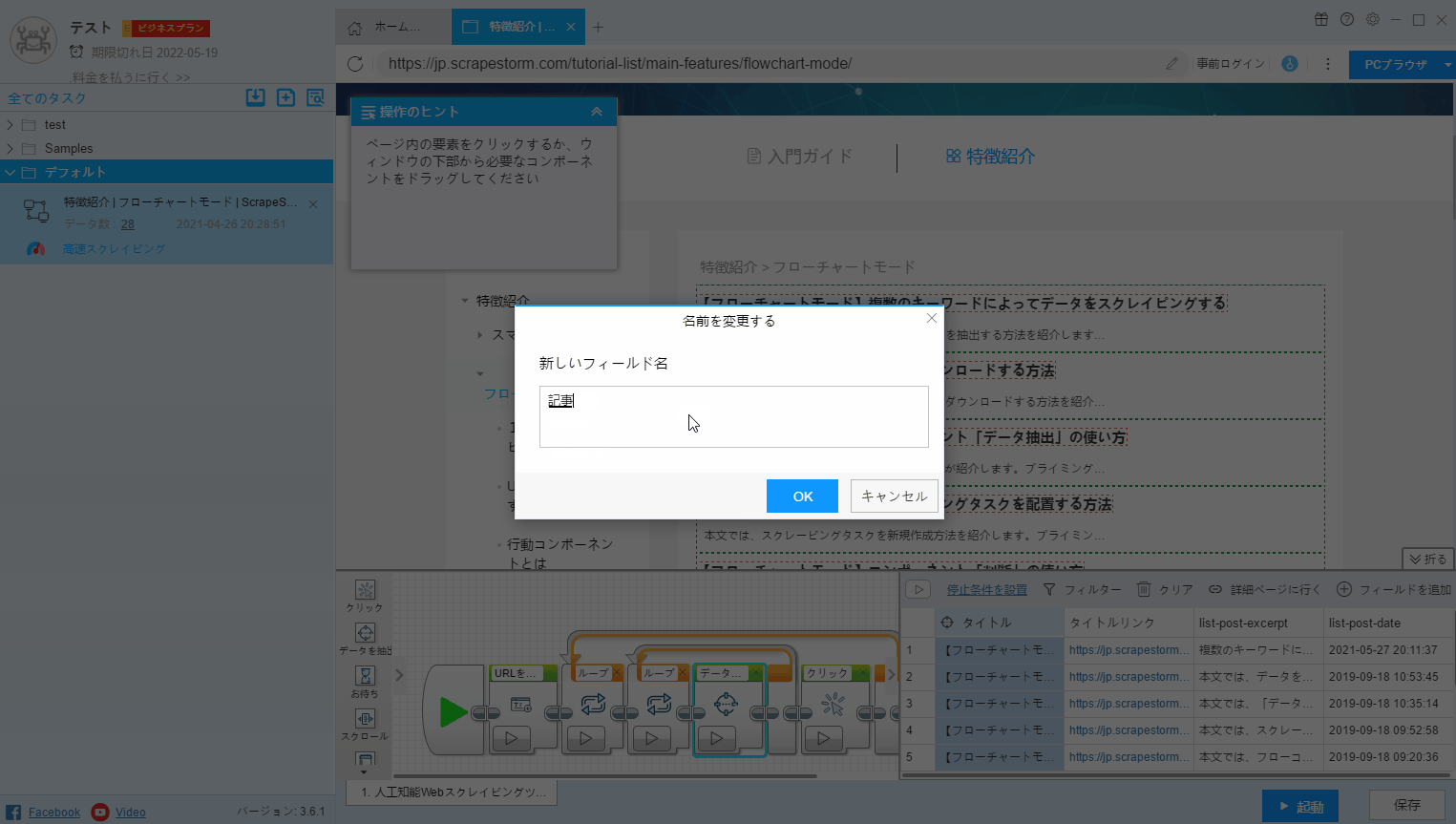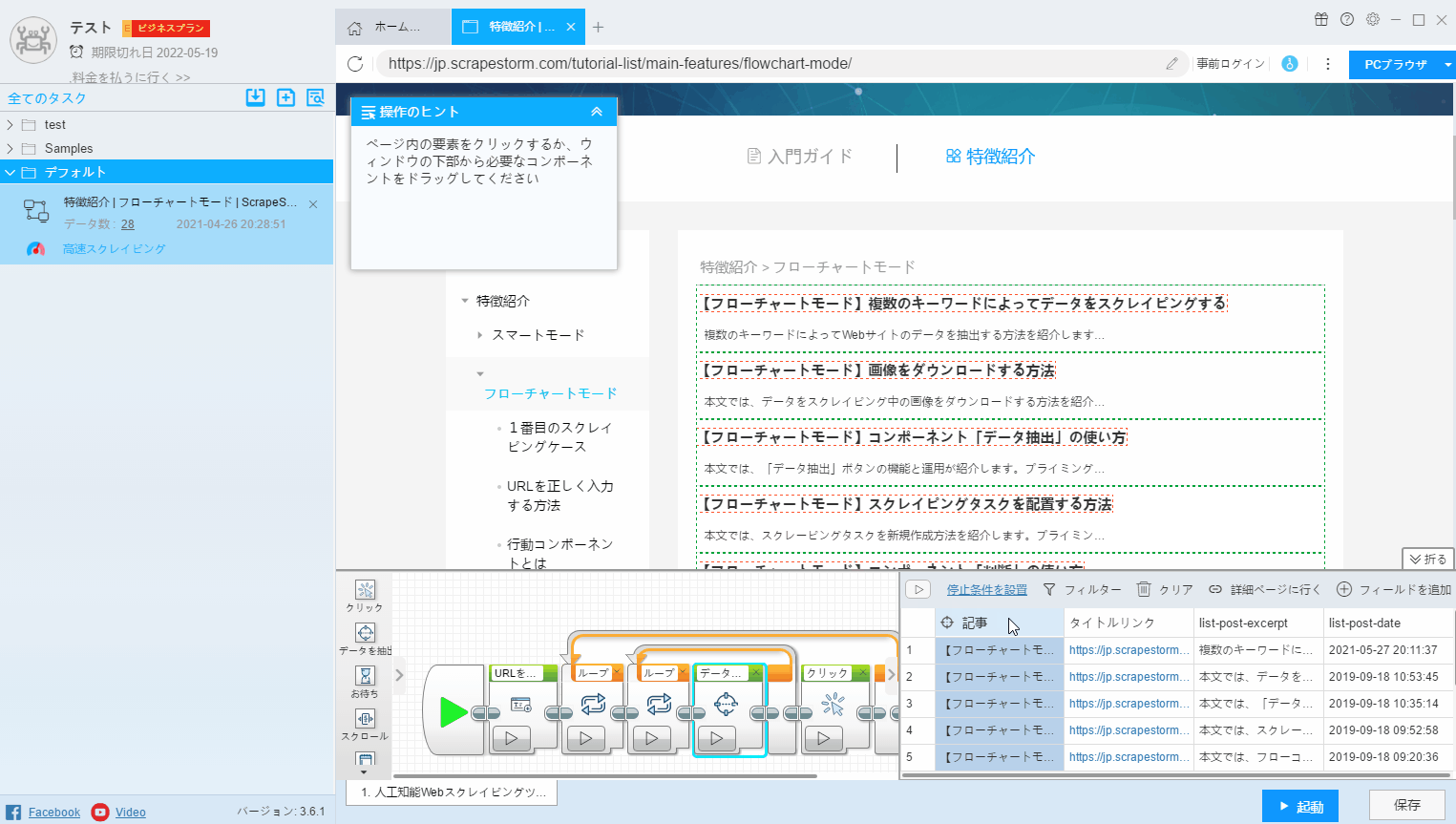
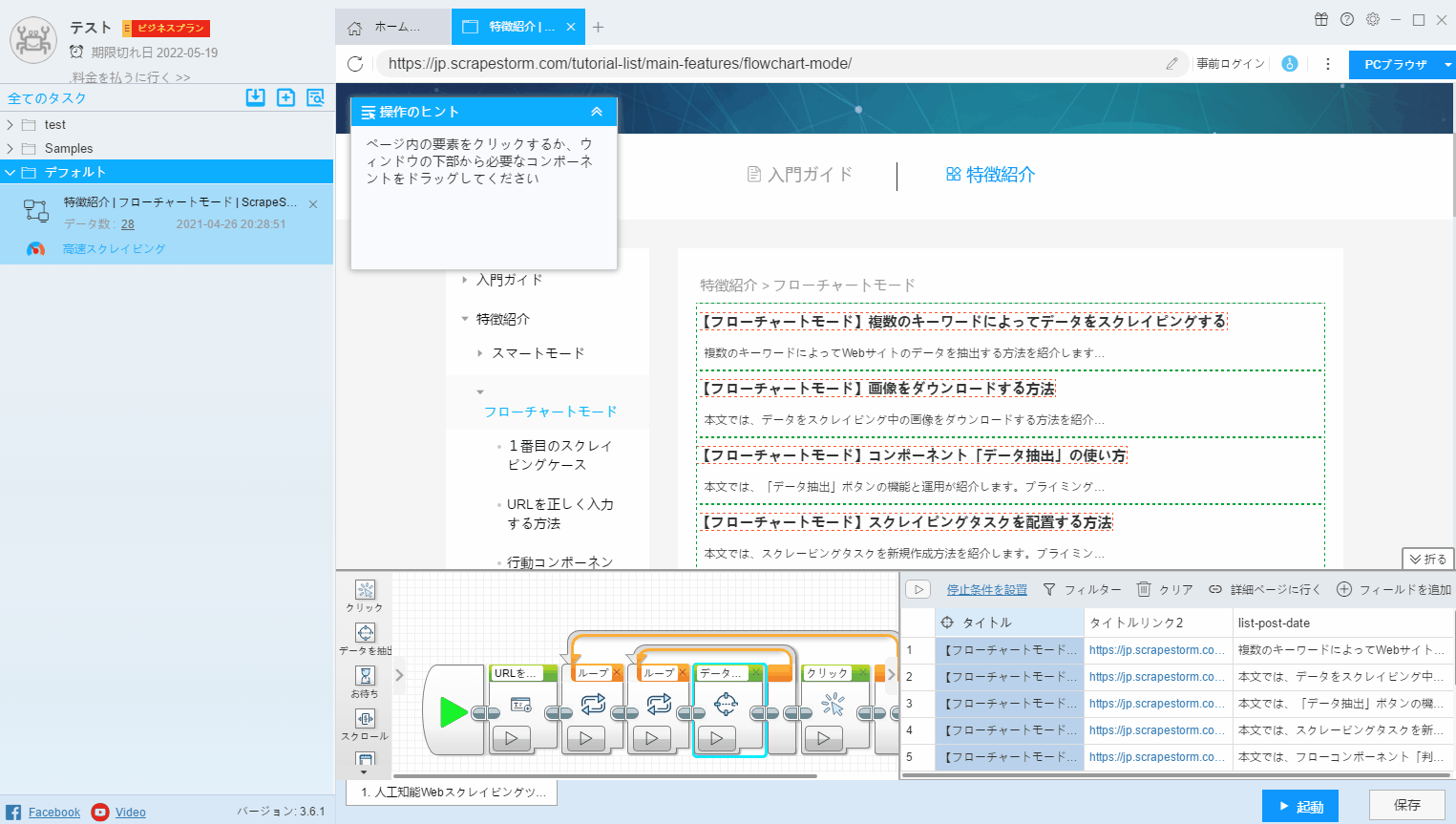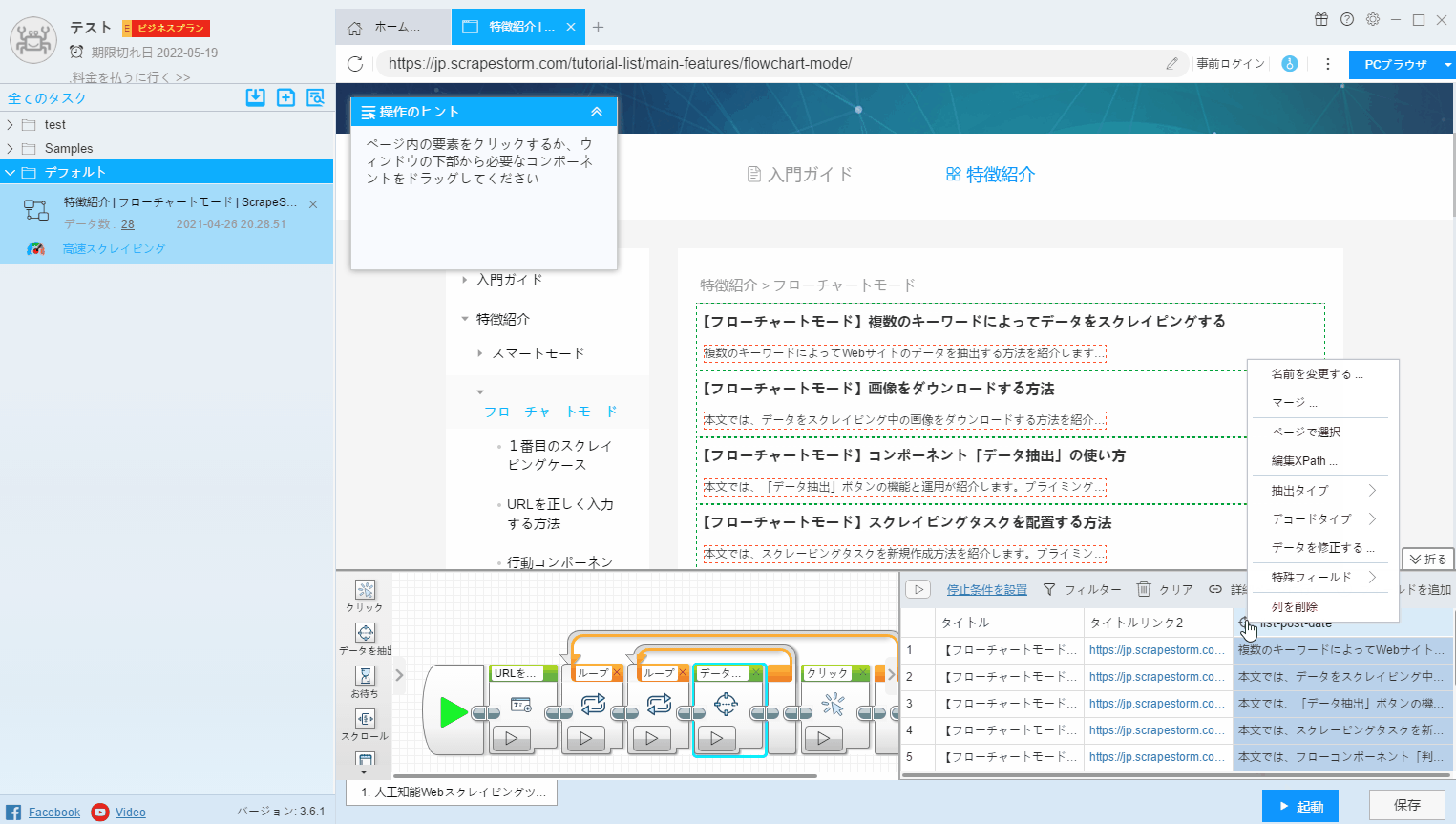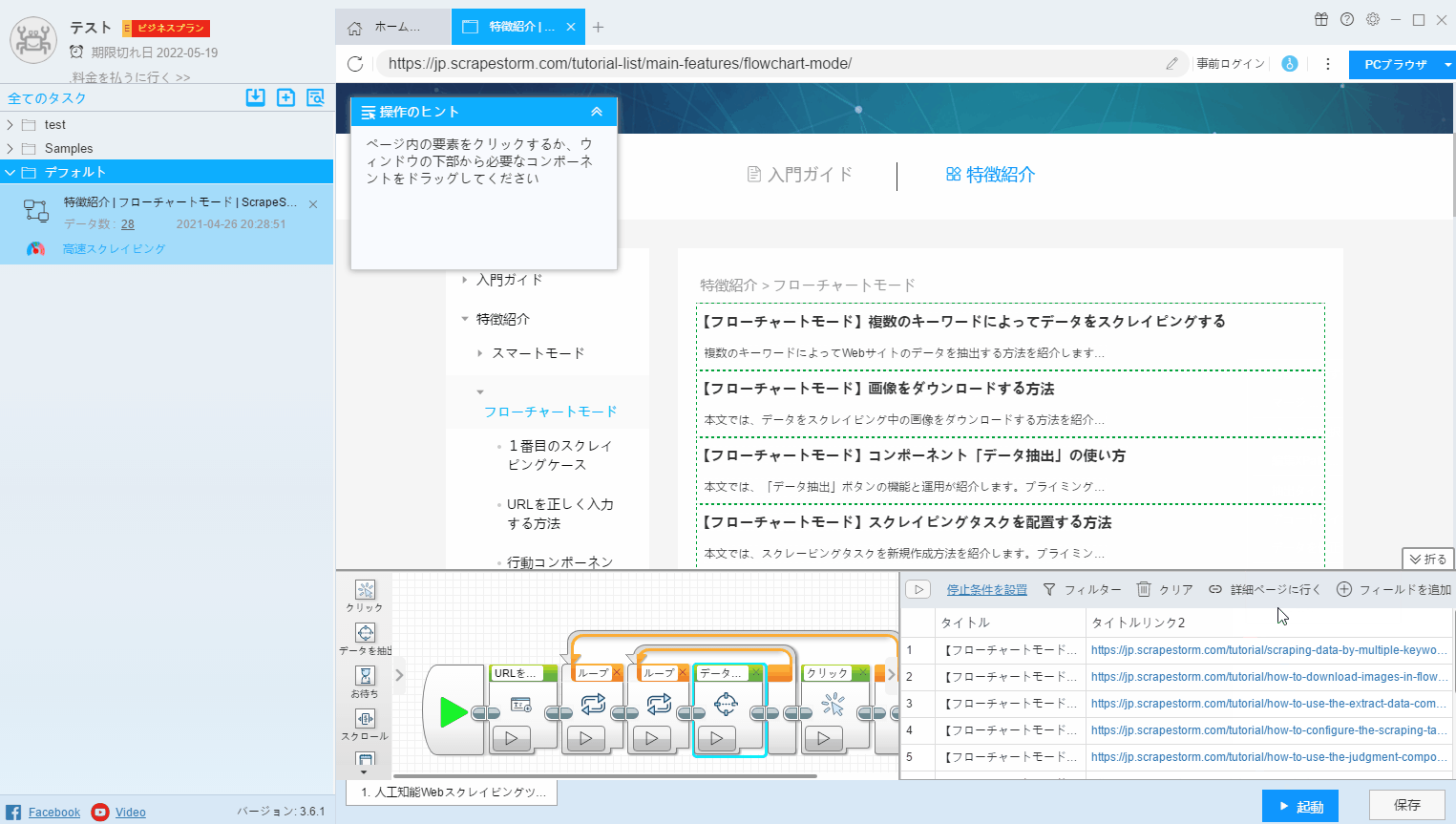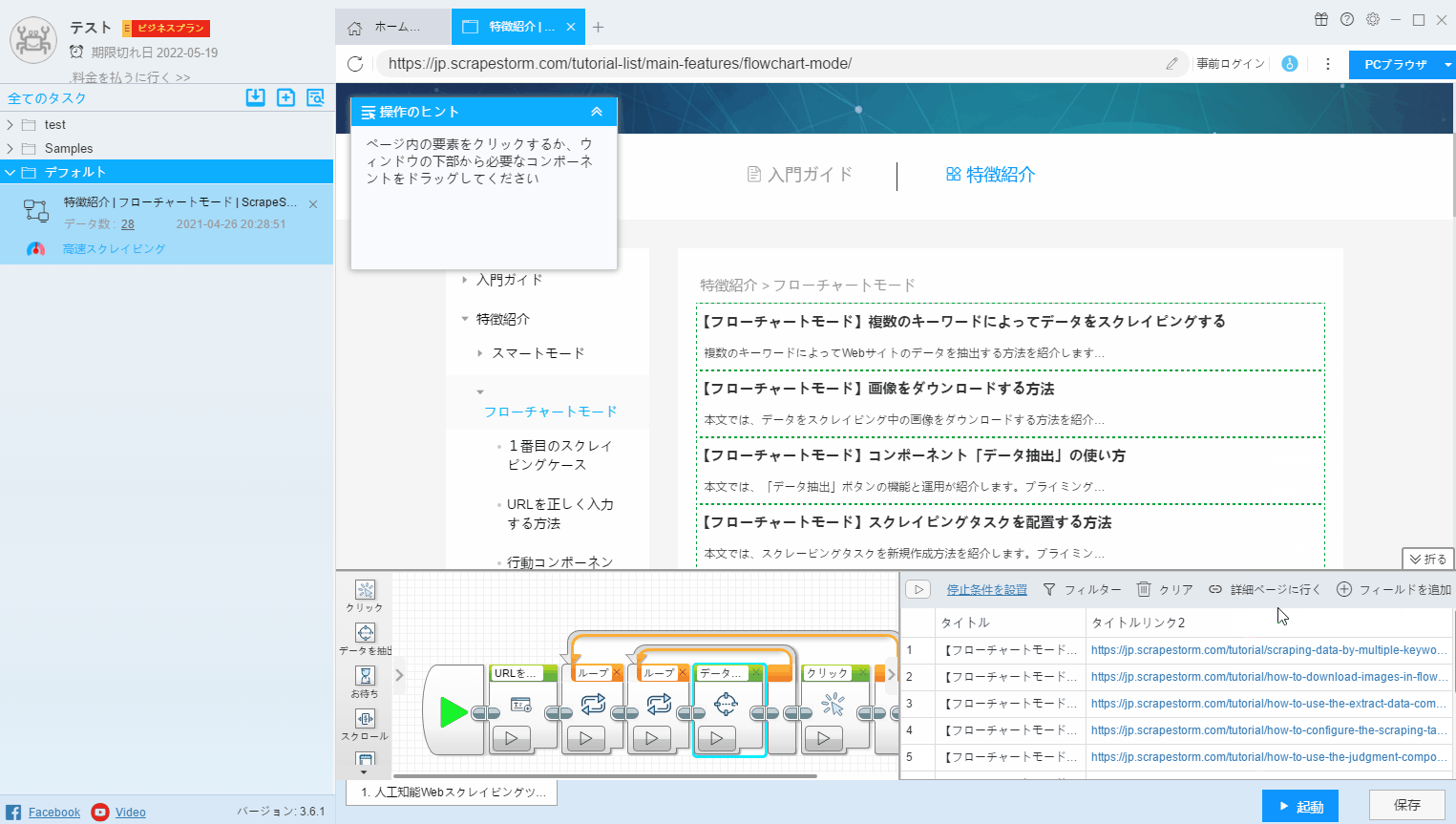
1.名前を変更する
2. マージ
フィールドをマージするには2つの方法があります。
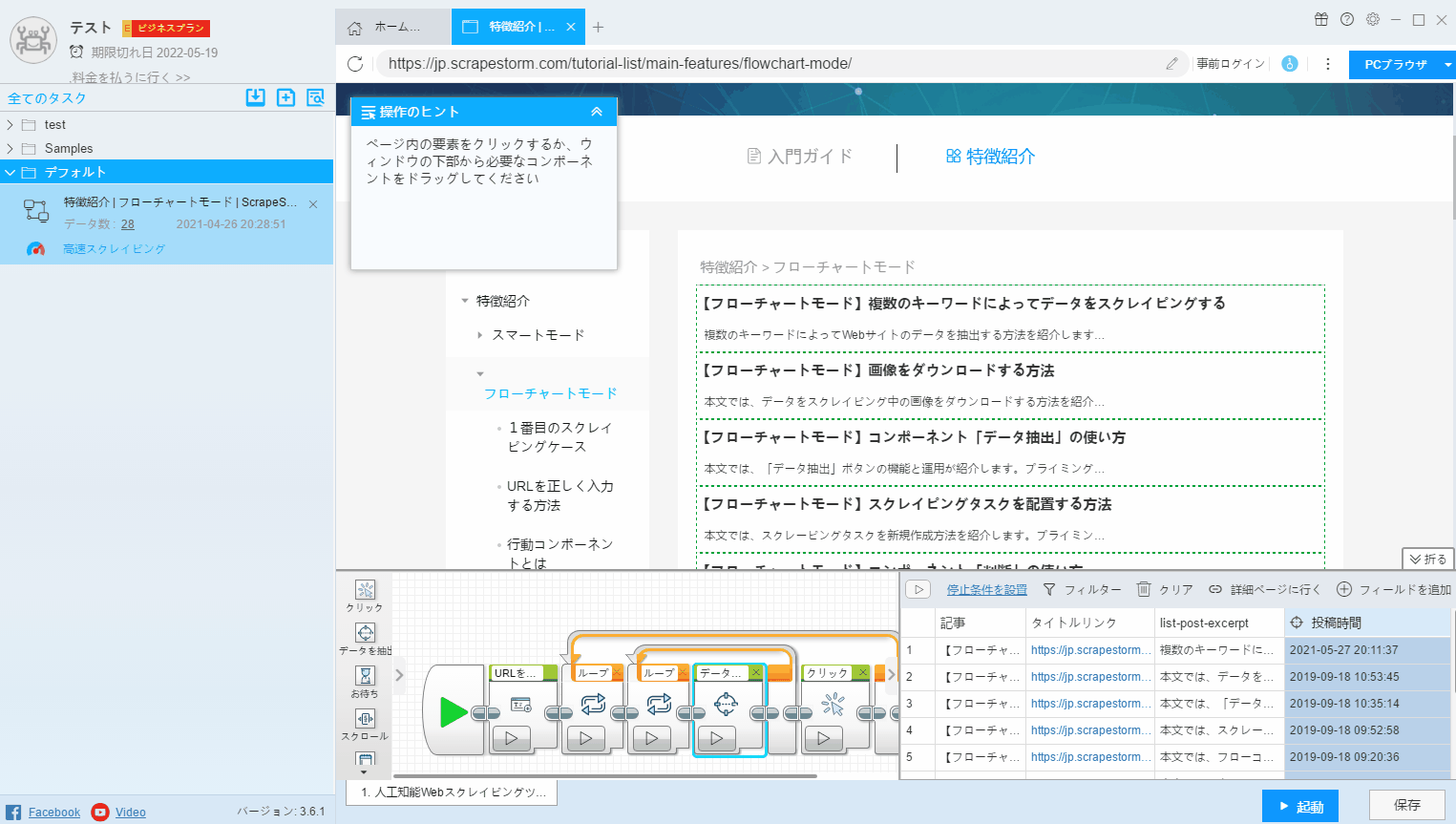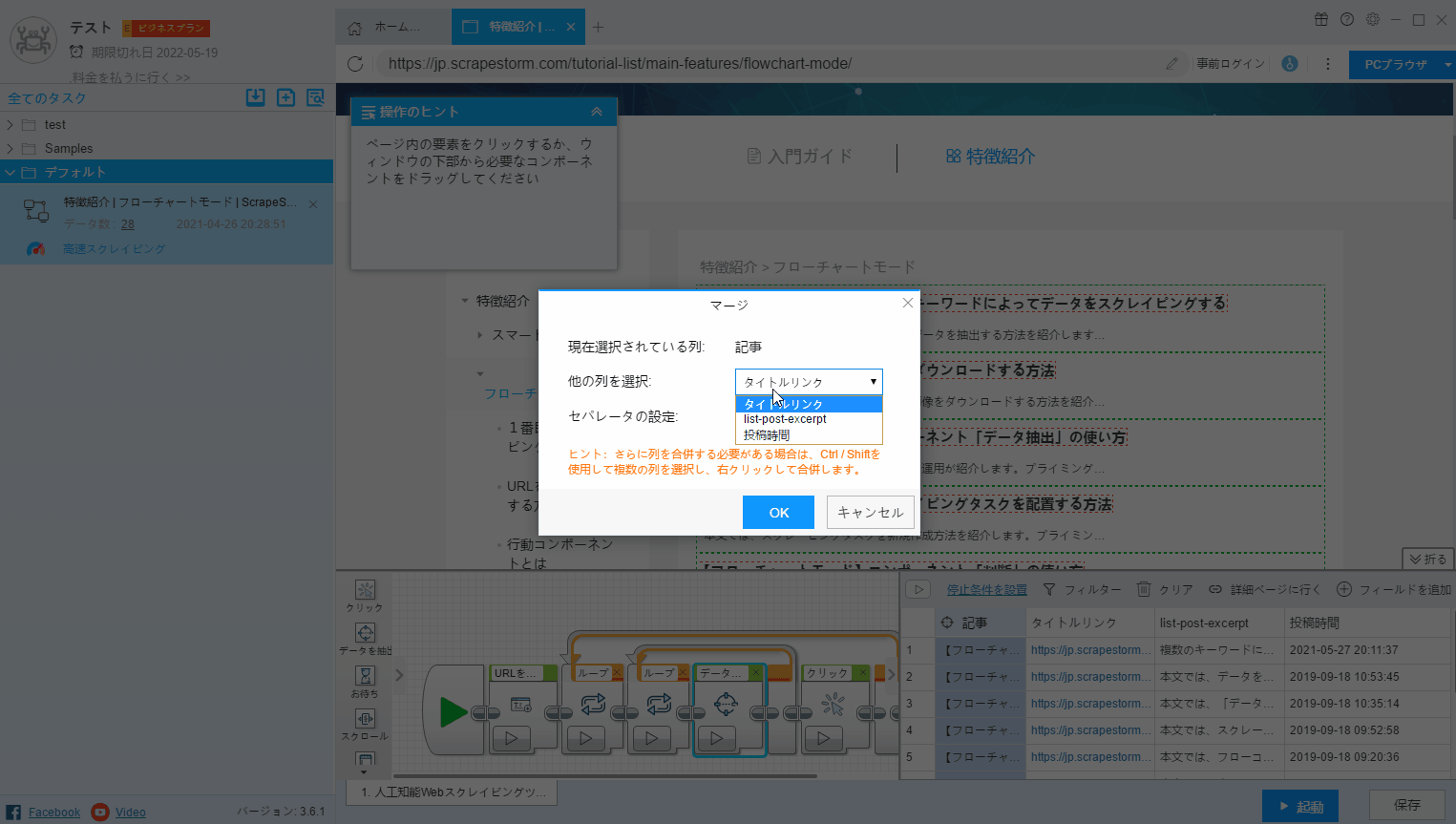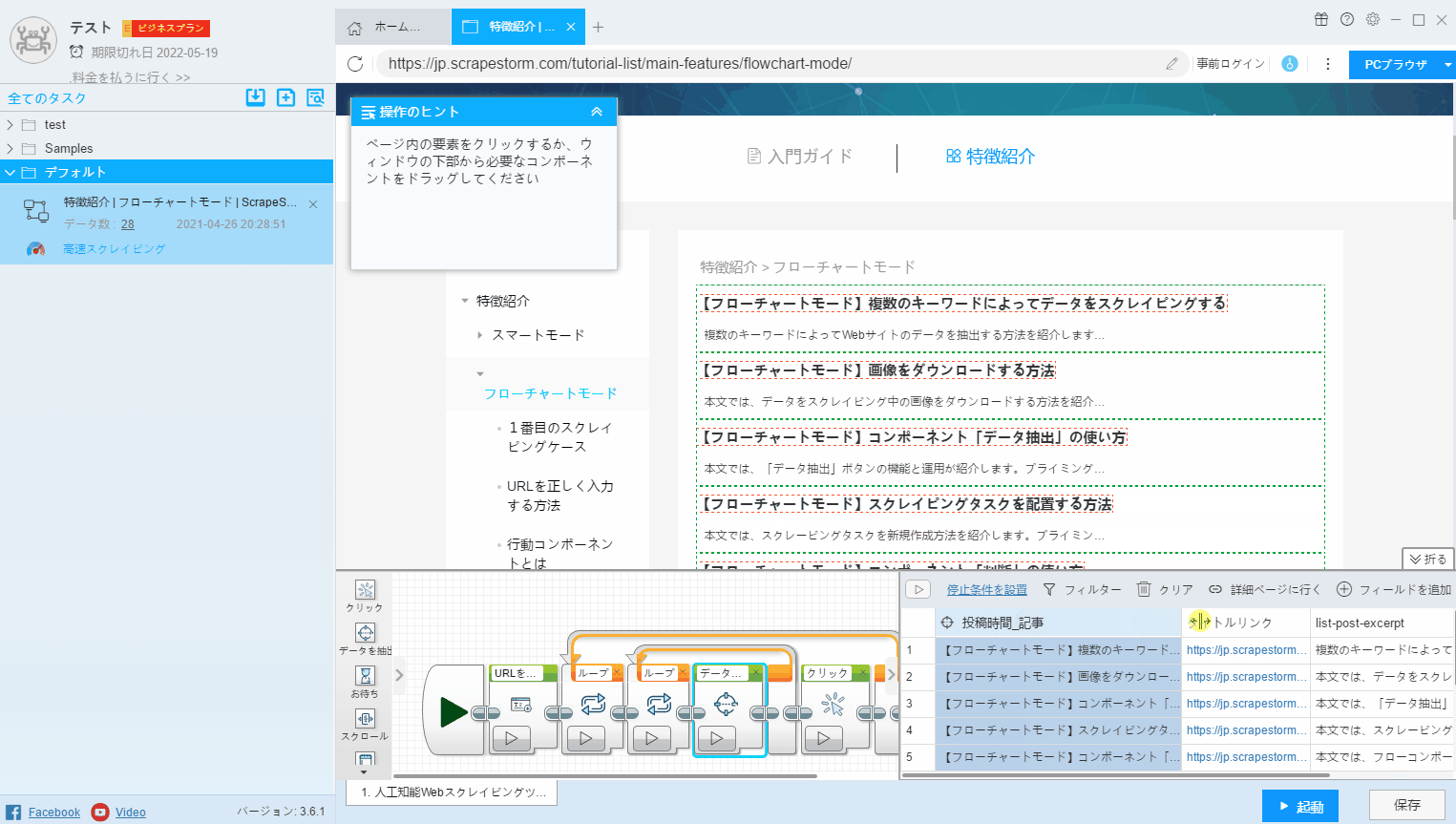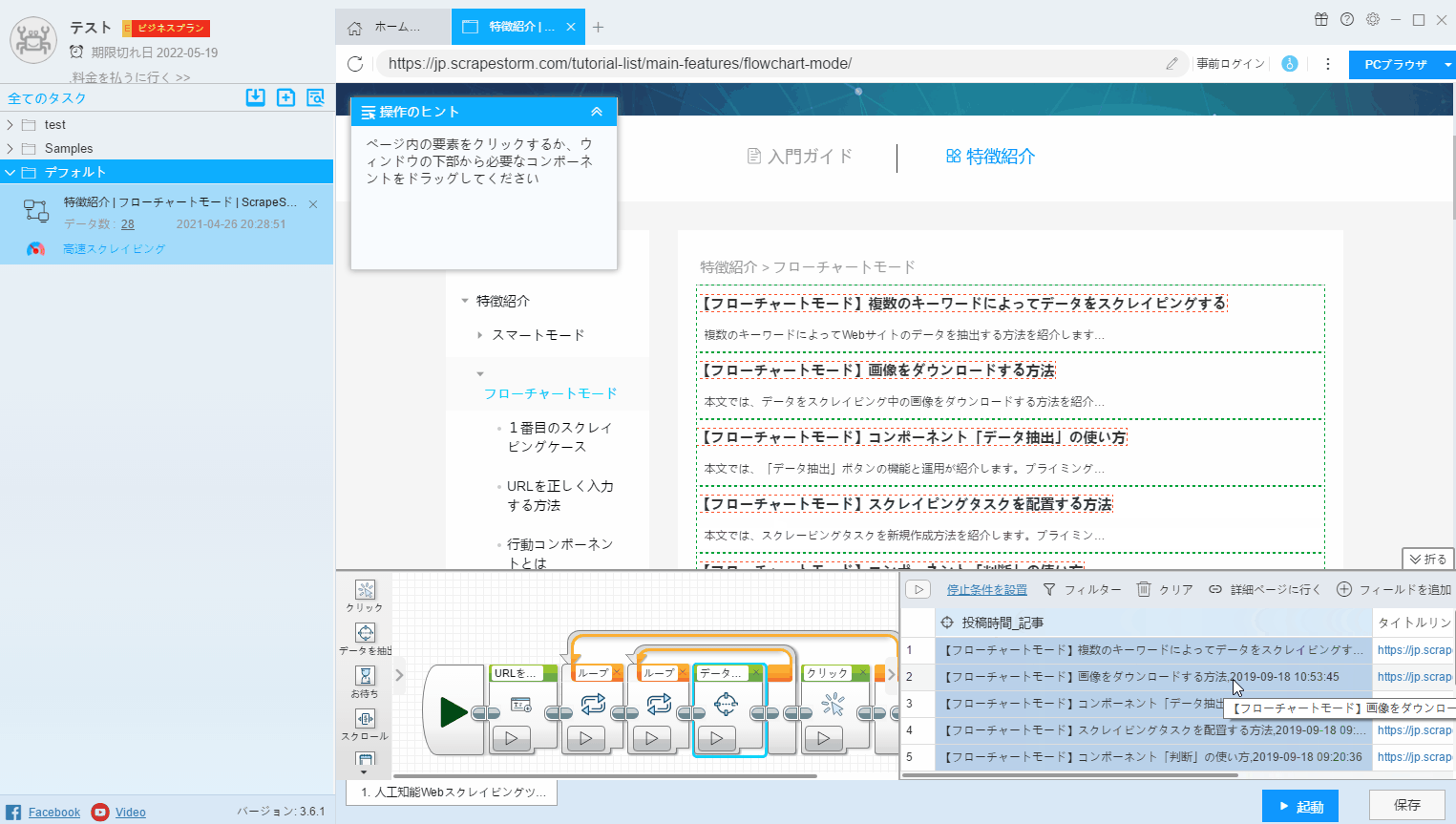
(1) マージする必要のあるフィールドをクリックし、右クリックして「マージ」を選択し、ページでマージするフィールドを選択します。
(2)CtrlキーまたはShiftキーを押して複数のフィールドを選択し、右クリックして「選択結合」を押します。 この方法は、複数のフィールドの組み合わせに適しています。
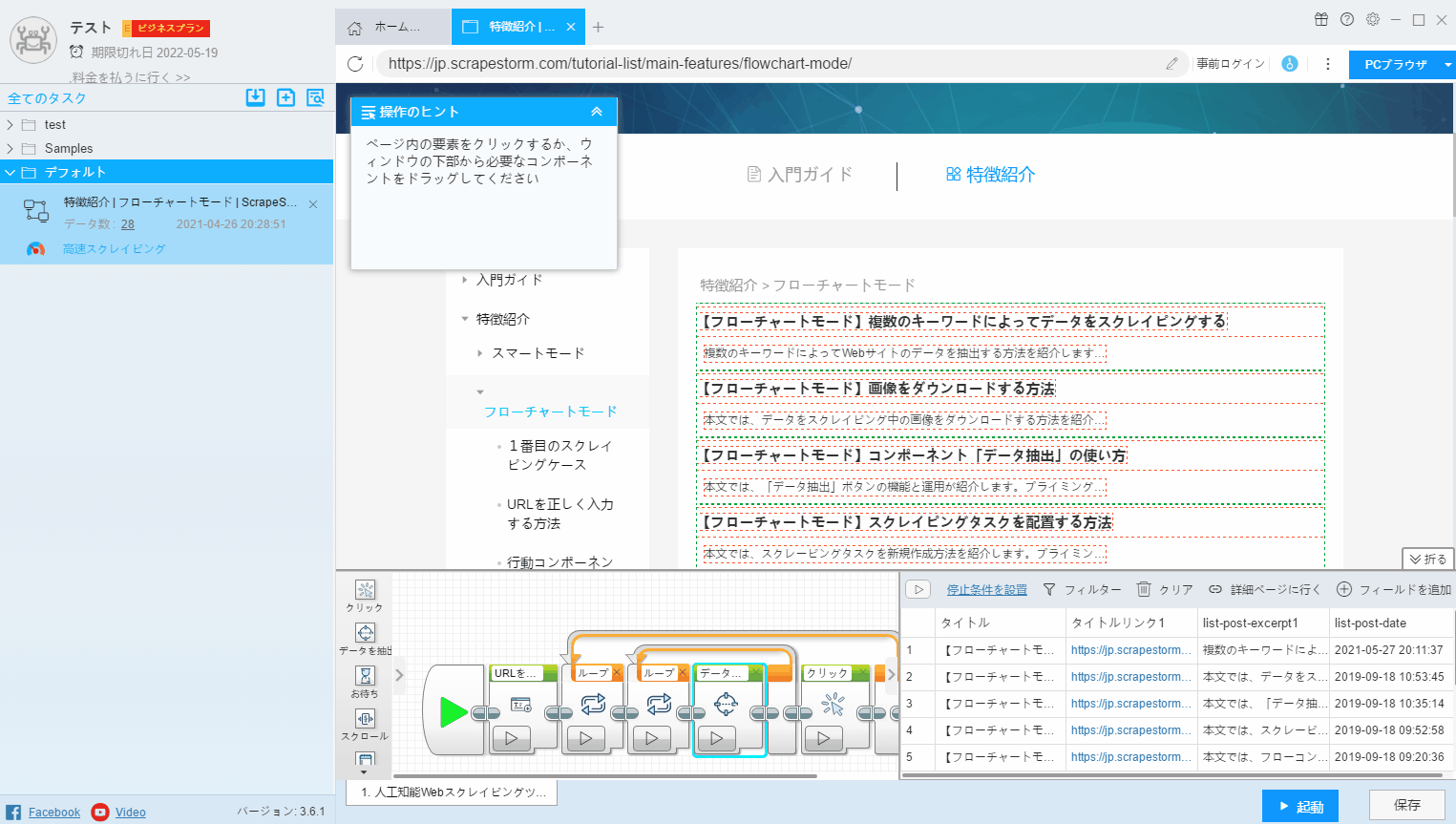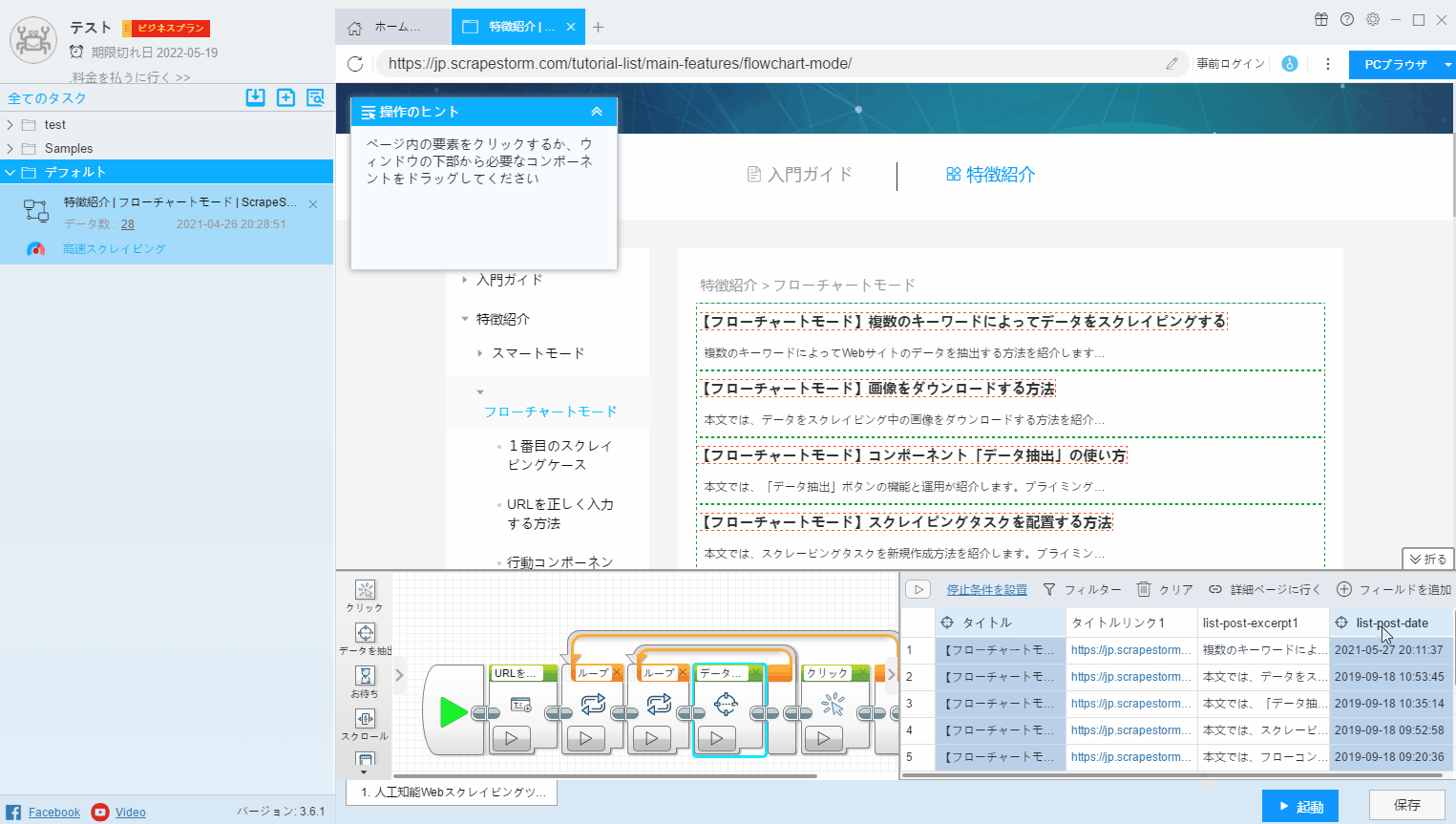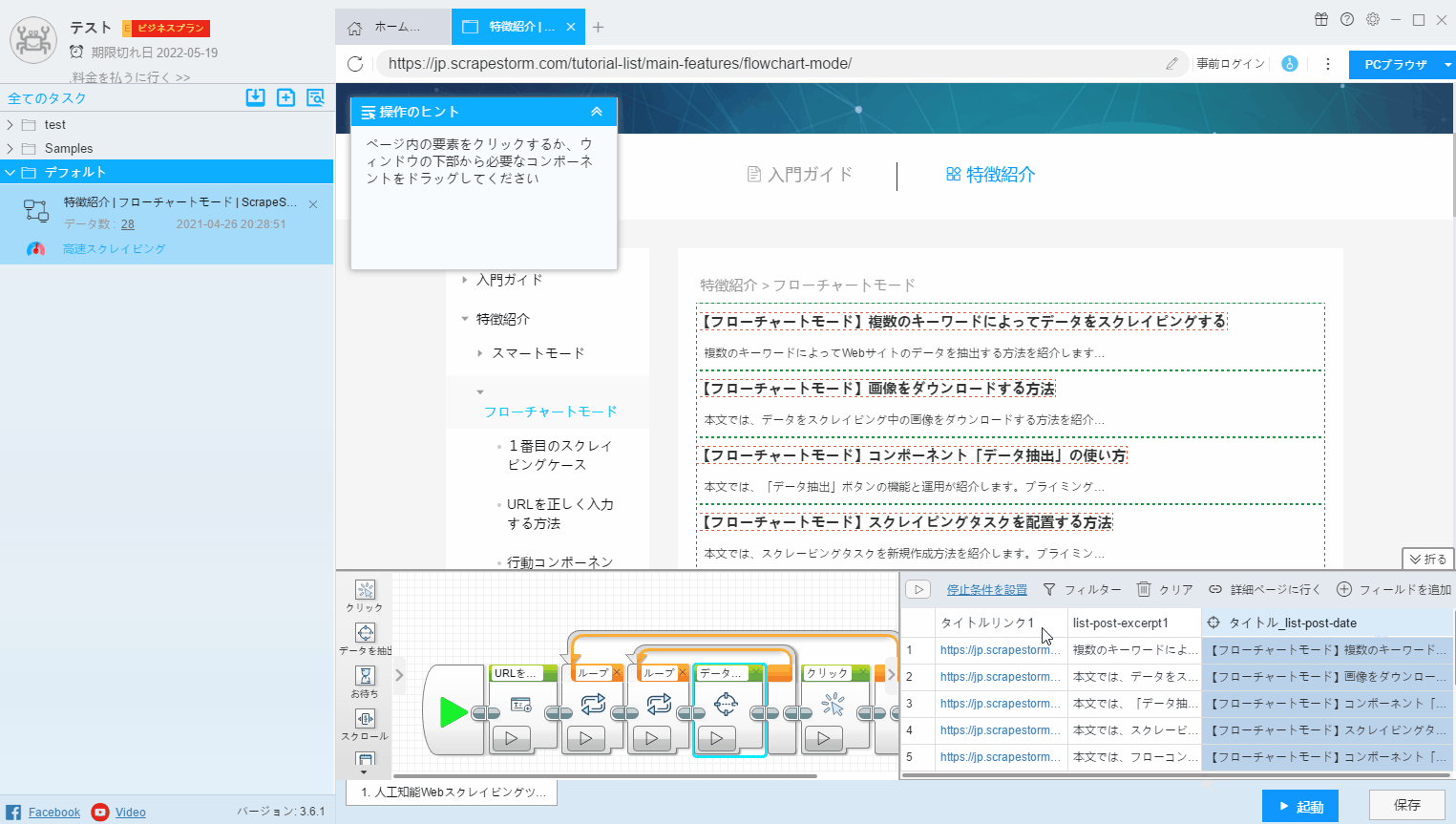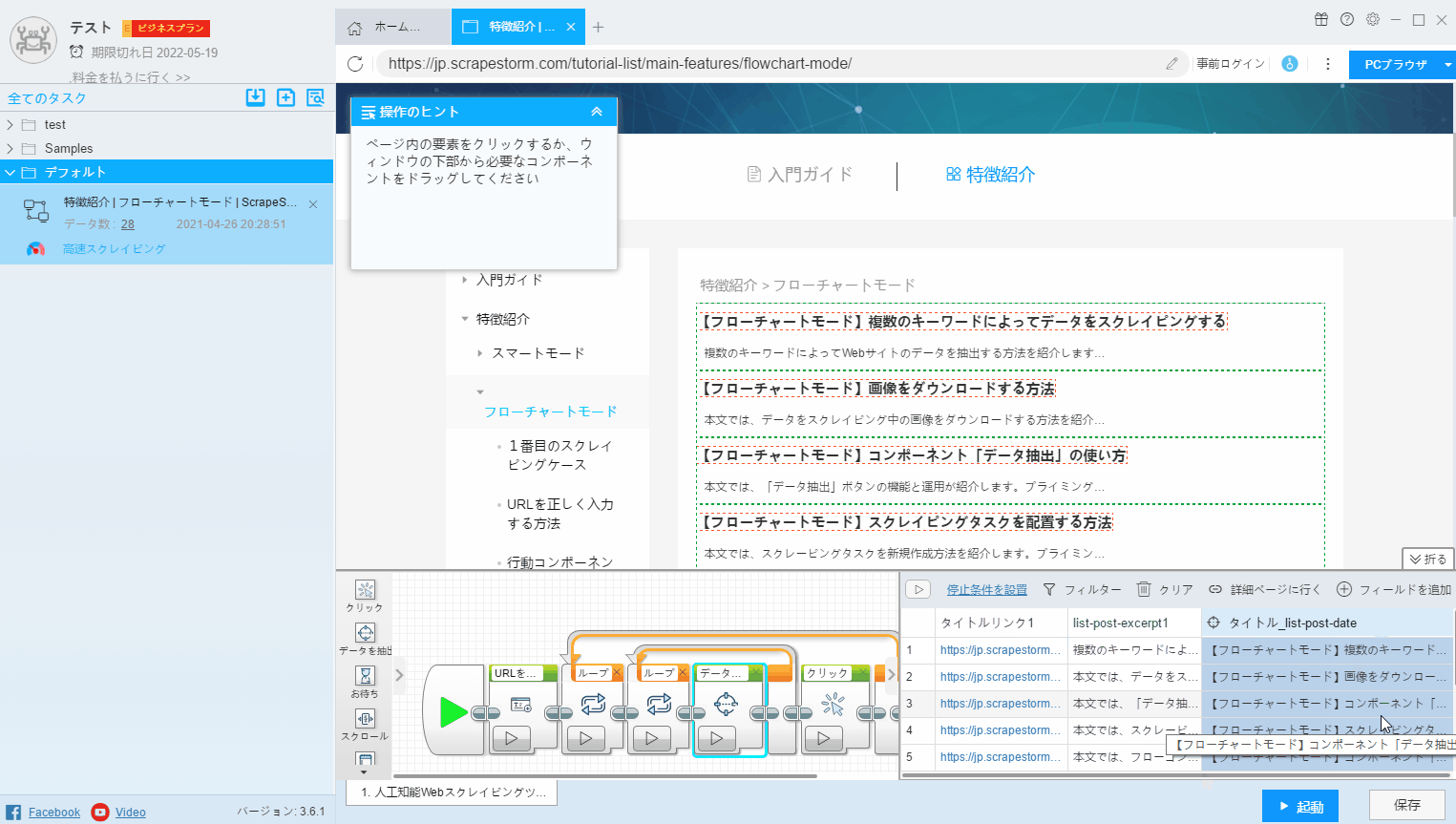
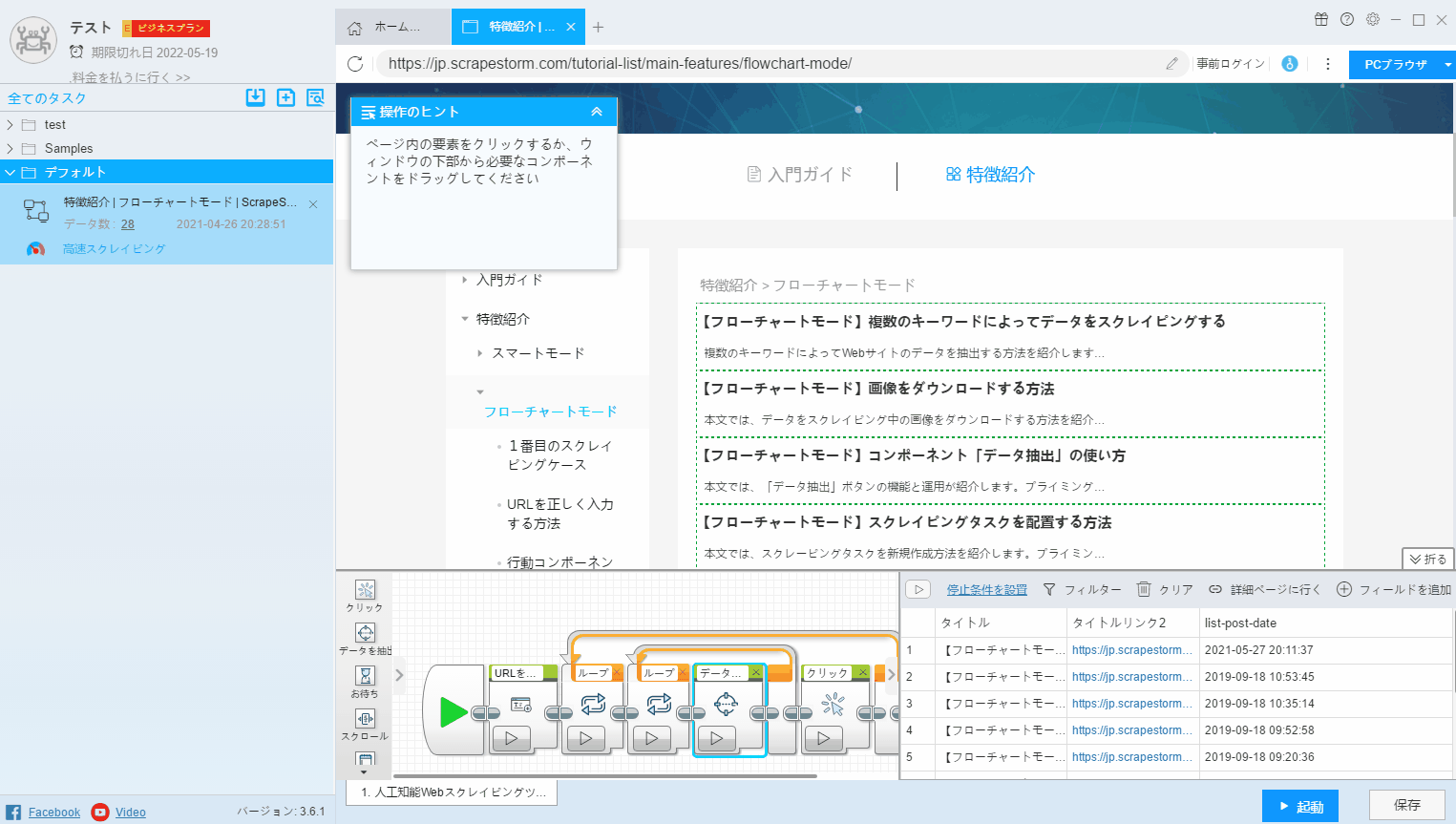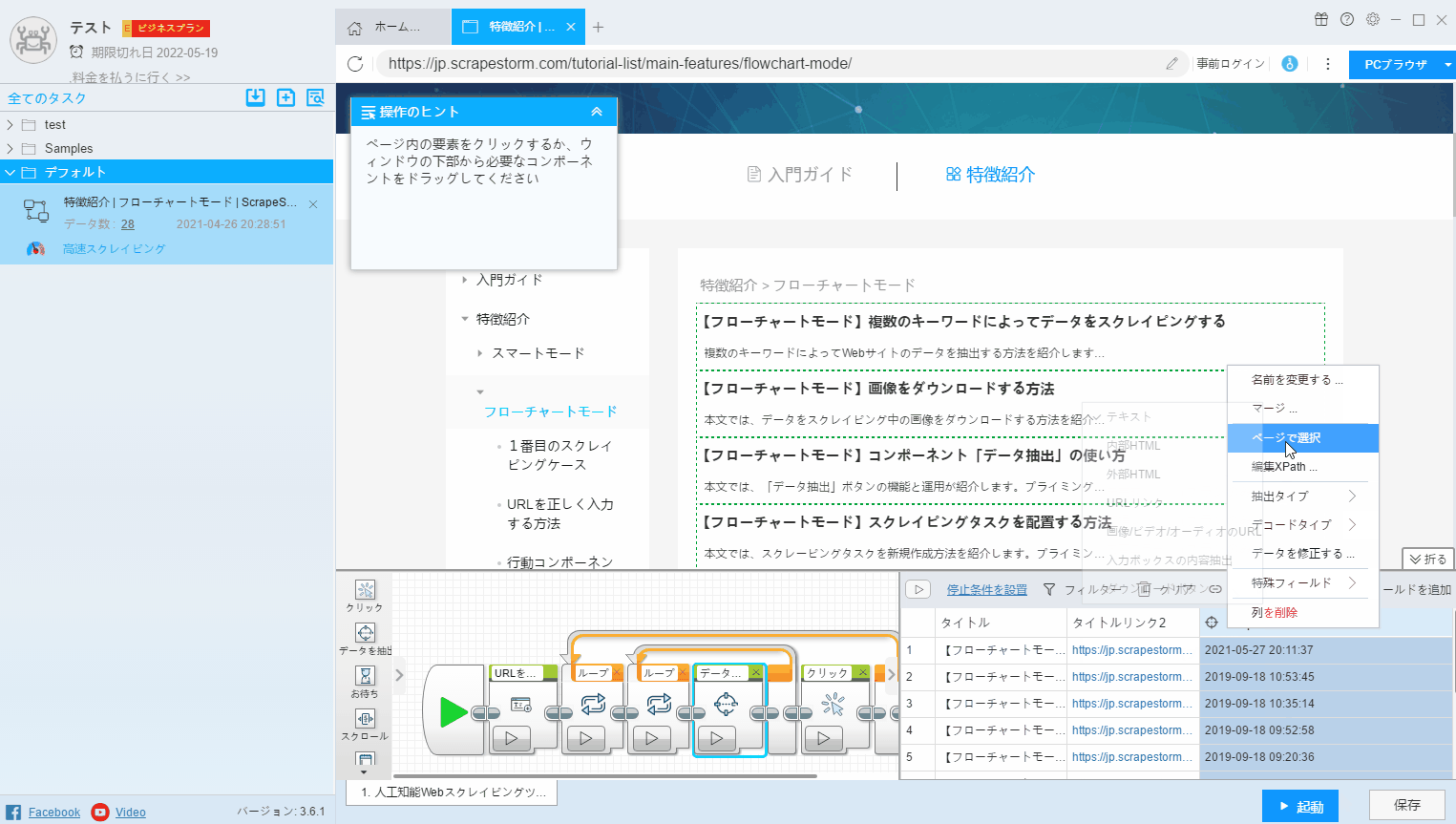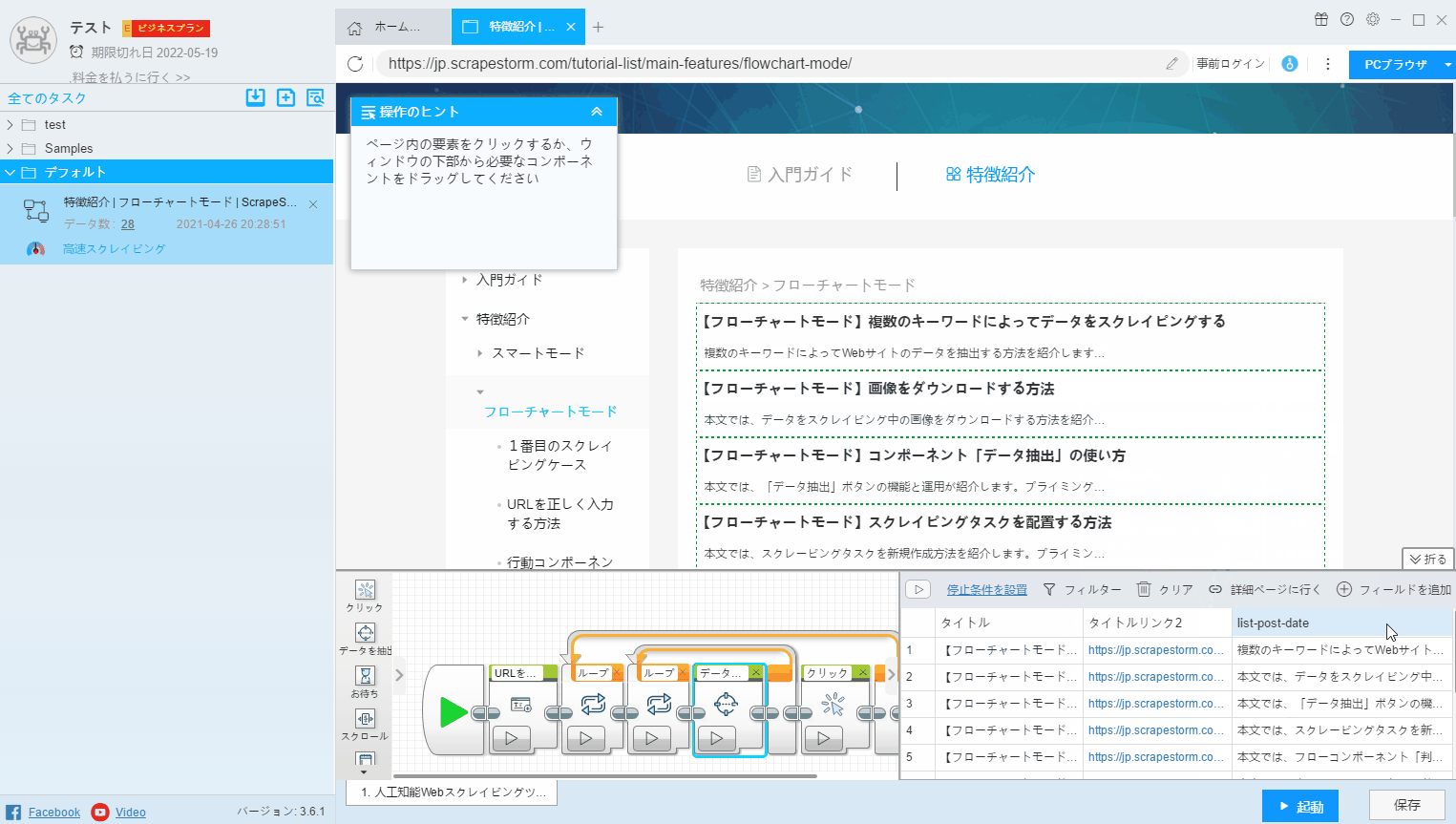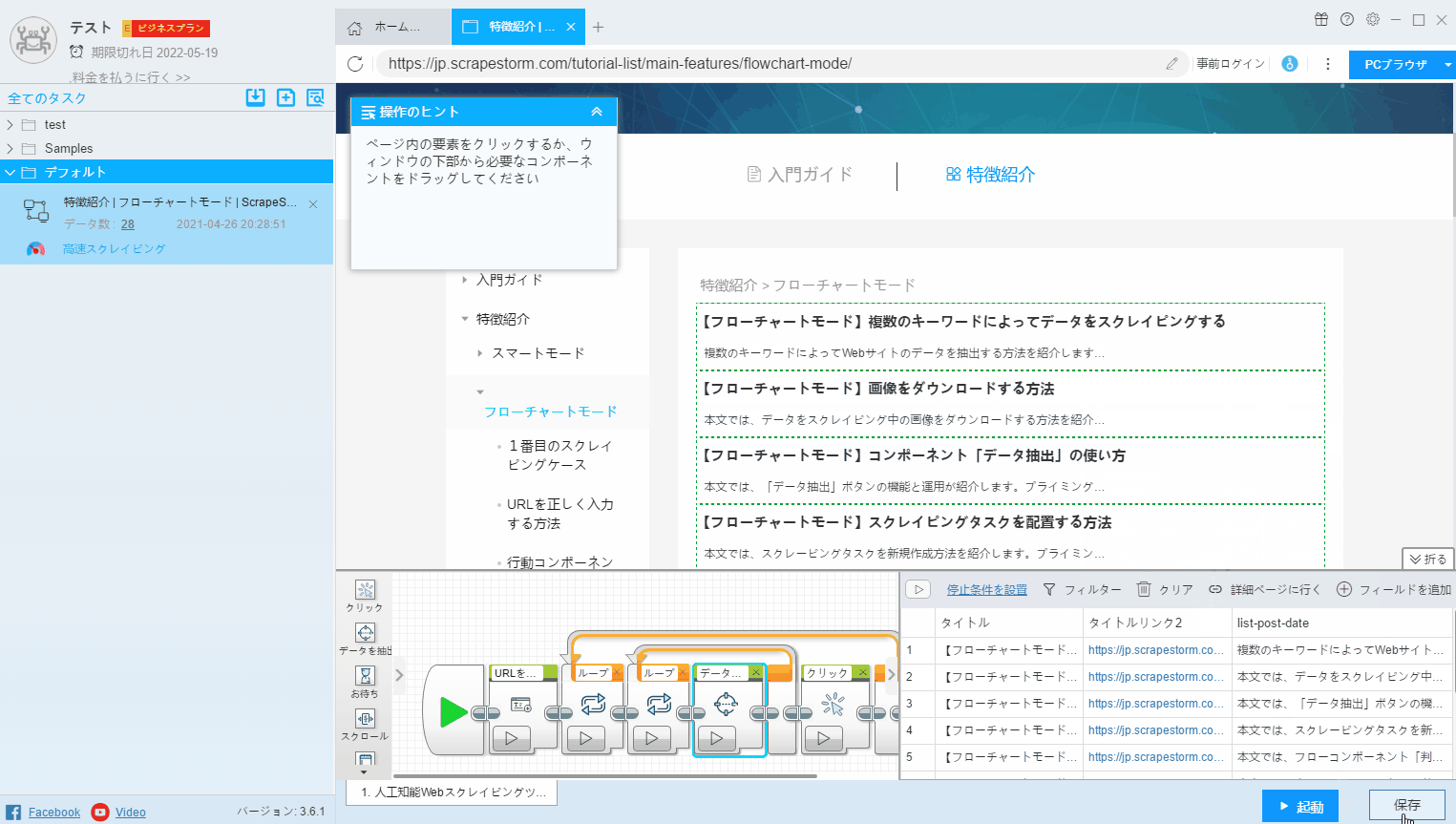
3.ページで選択
フィールドで抽出されたデータを変更する場合、または新しいフィールドを追加する場合は、「ページで選択」をクリックして、Webページで必要なデータを抽出する必要があります。
4.Xpathの編集
Xpathは、パス式を使用してWebページで必要なデータの場所を見つけるパスクエリ言語です。プログラミング経験を持つユーザーさんは、この機能を使用して新しいXPathをセットアップできます。
Xpathの詳細については、ここをクリックしてください。
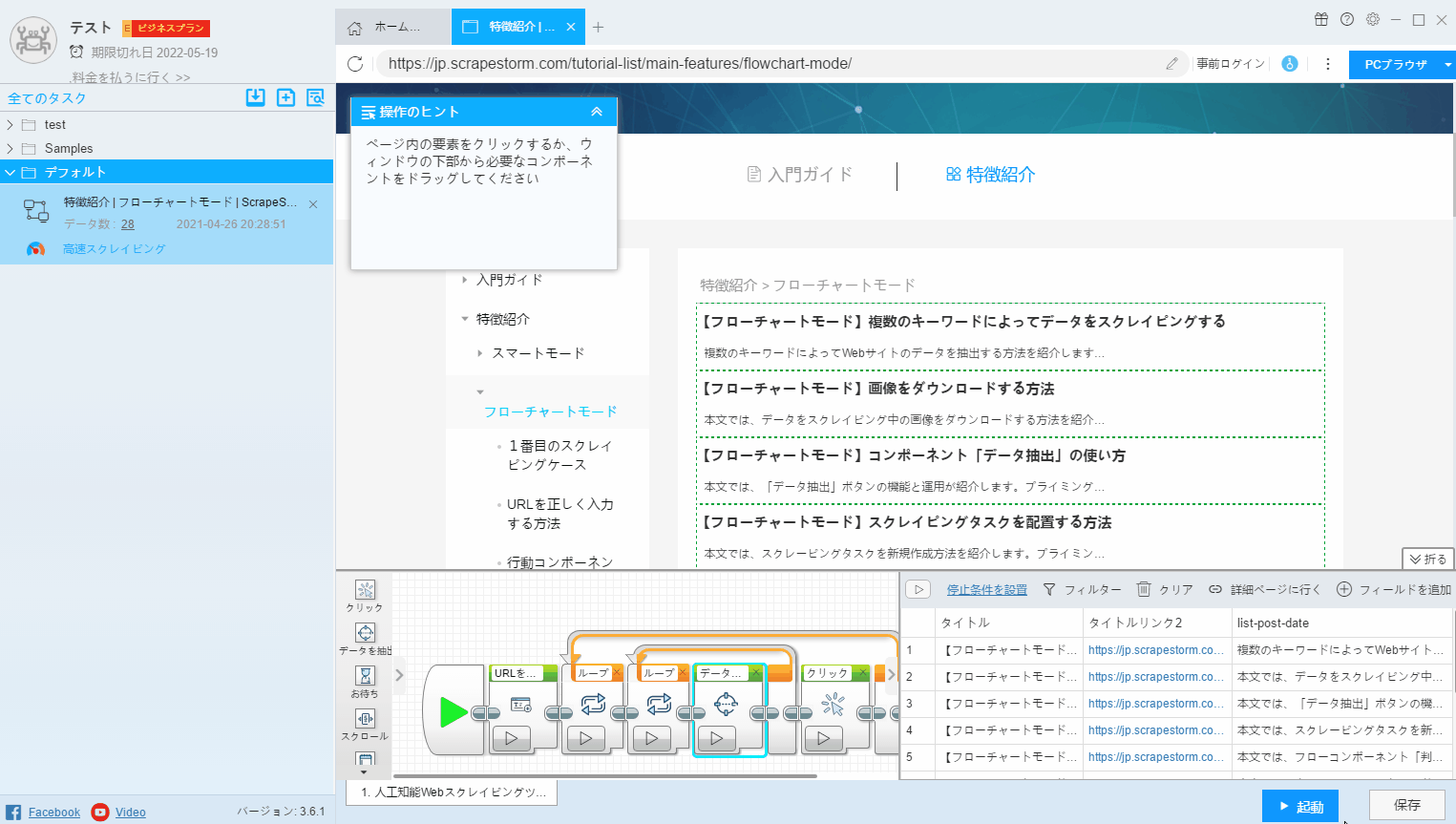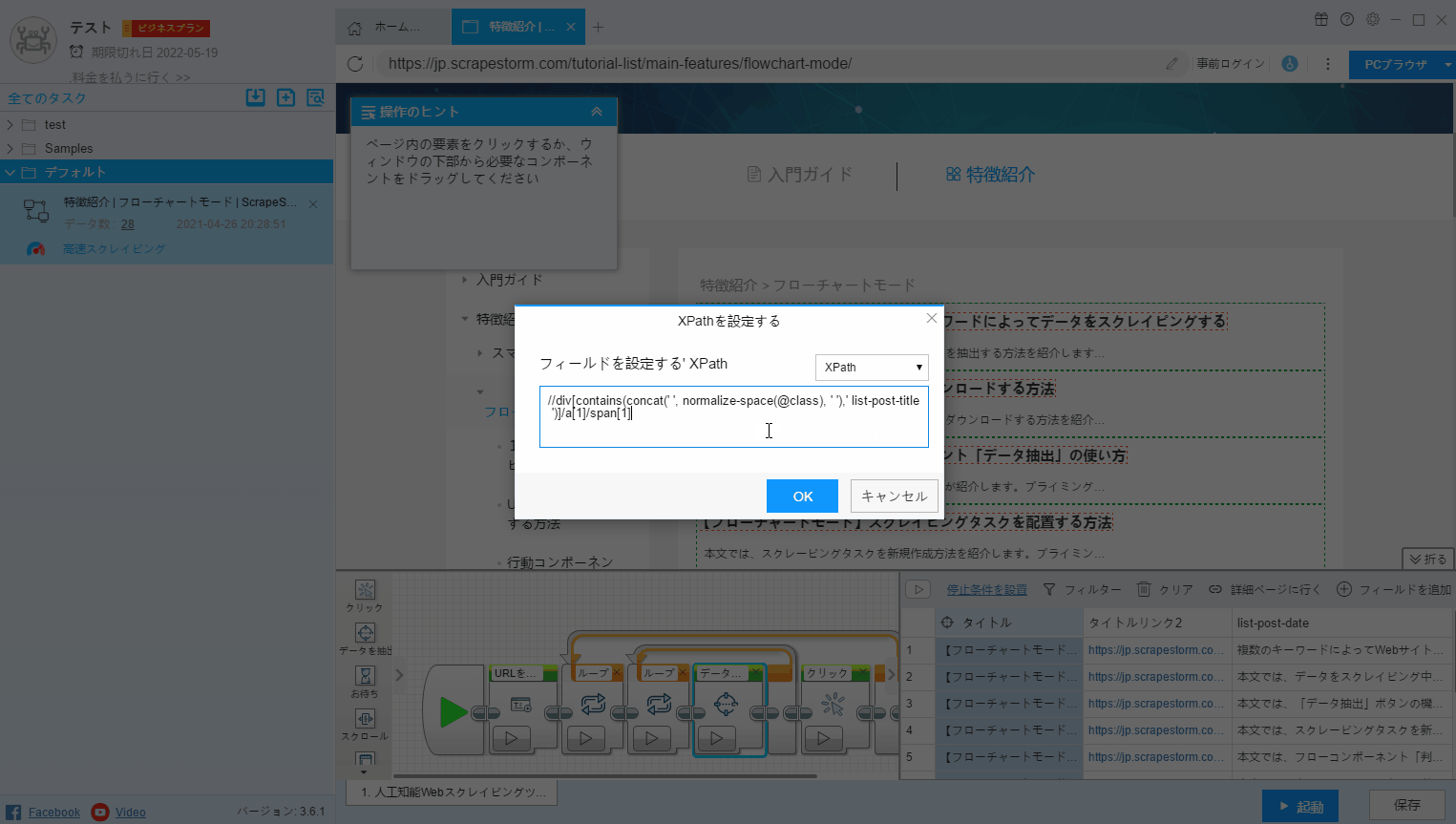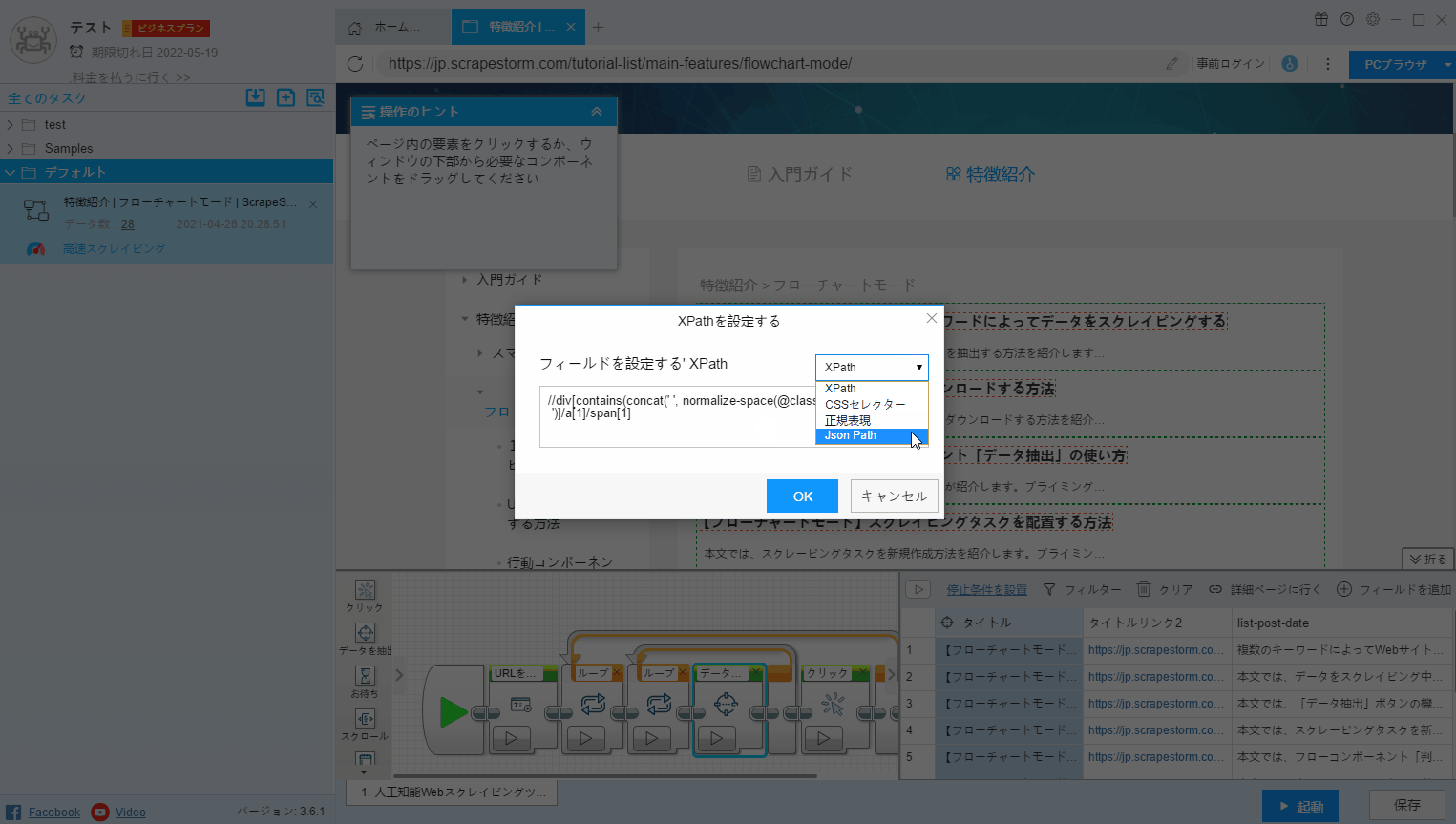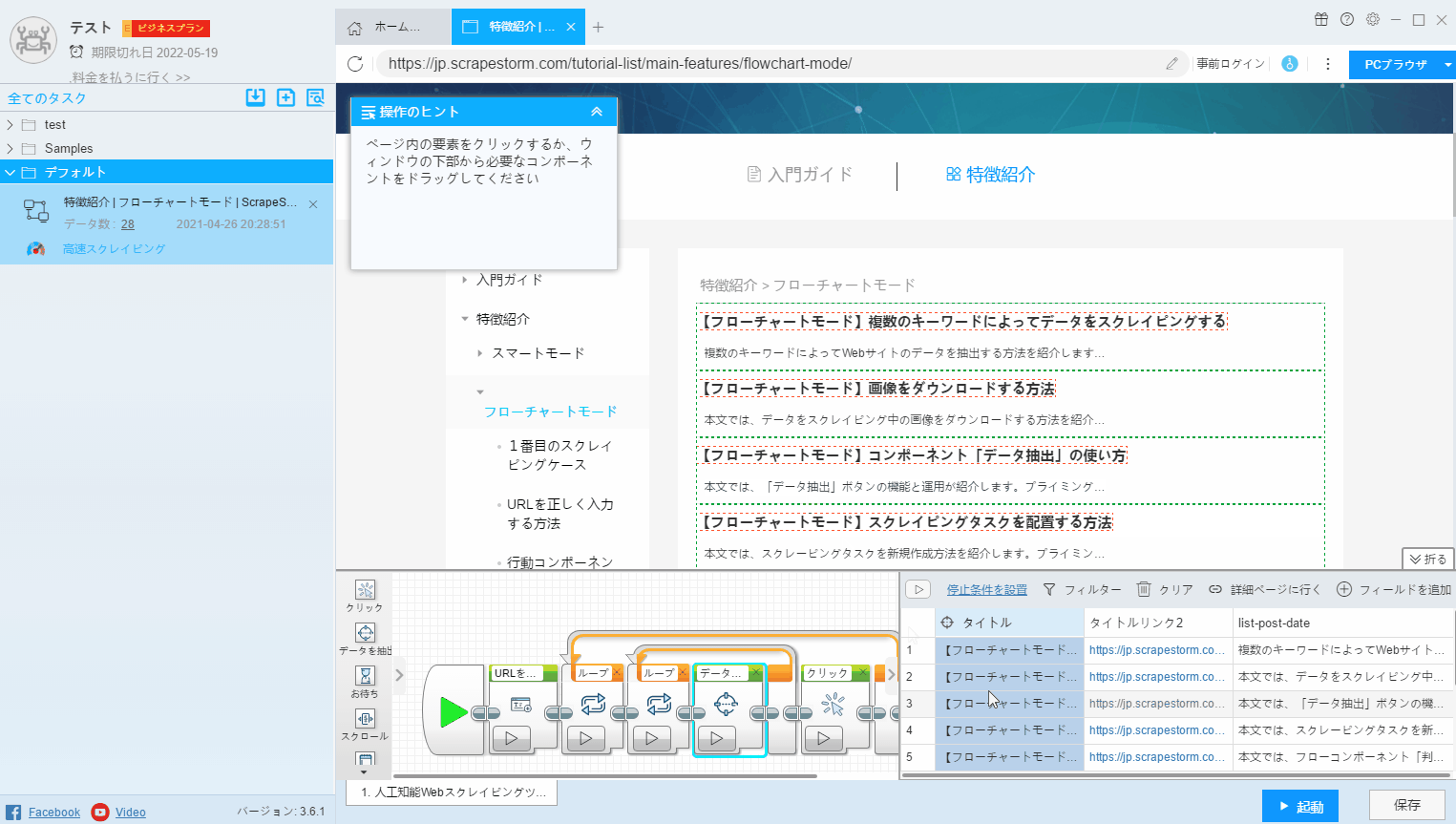
5.抽出タイプの選択
データごとに異なる値属性を設定する必要があります。 新しいフィールドを設定すると、フィールドの値はデフォルトでテキストフィールドになります。
一般的に、新しいデータを選択すると、ScrapeStormが自動的にフィールド属性を決定します。設定する必要はありません。ただし、判断エラーがある場合は、フィールドの値属性を自分で設定する必要になります。
テキスト:通常のテキストデータに適しています。
外部HTML:コンテンツ自体を含まないHTMLの抽出に適しています。
内部HTML:コンテンツ自体を含むHTMLの抽出に適しています。
リンクURL:リンクの抽出に適しています
画像/ビデオのURL:画像の抽出に適しています
入力ボックスの内容を抽出
ヒント:HTMLはWebページの記述に使用される言語です。 主にデータの表示と外観を制御するために使用されます。 HTMLドキュメントはWebページとも呼ばれます。
HTMLの詳細については、ここをクリックしてください。
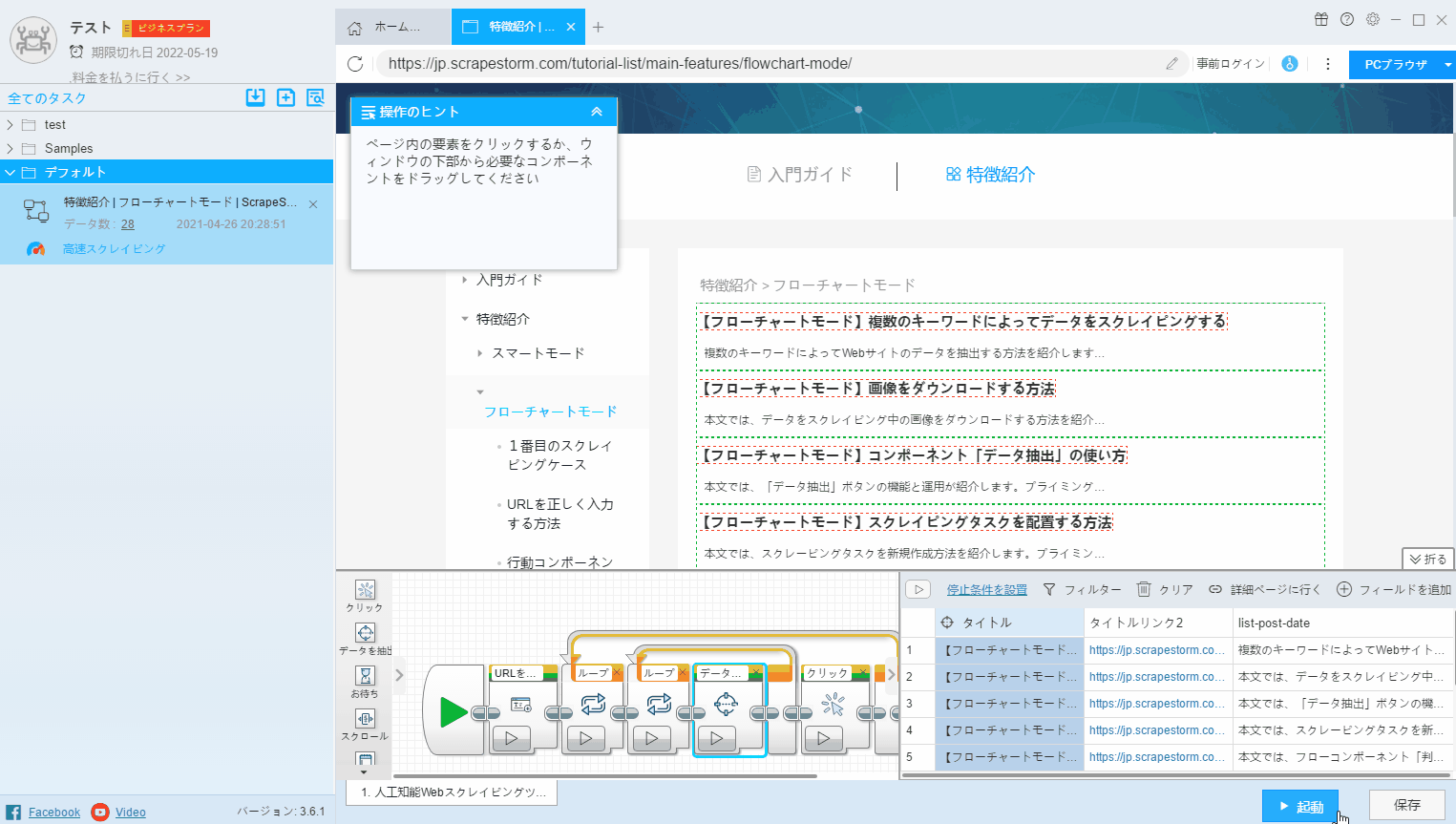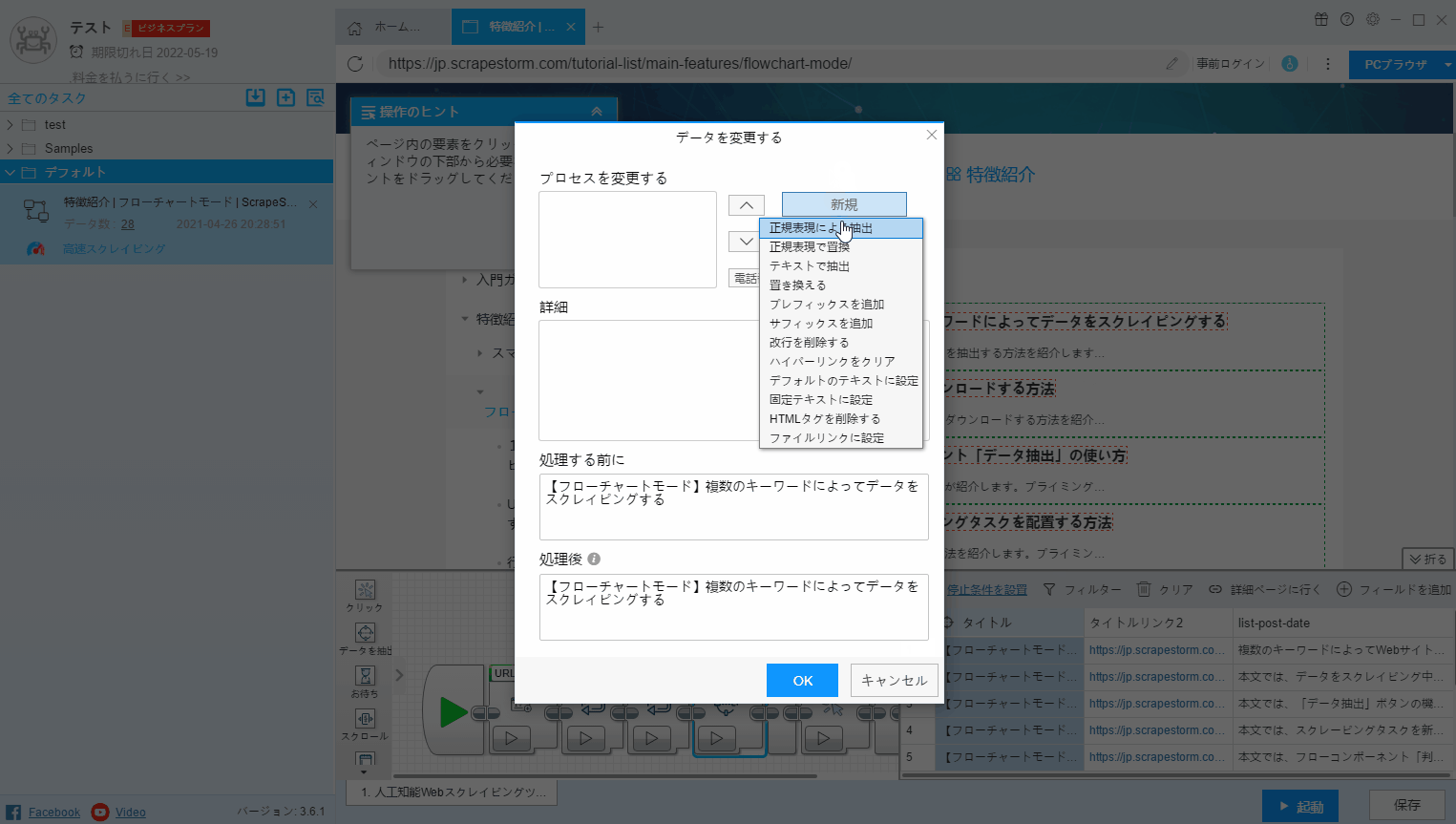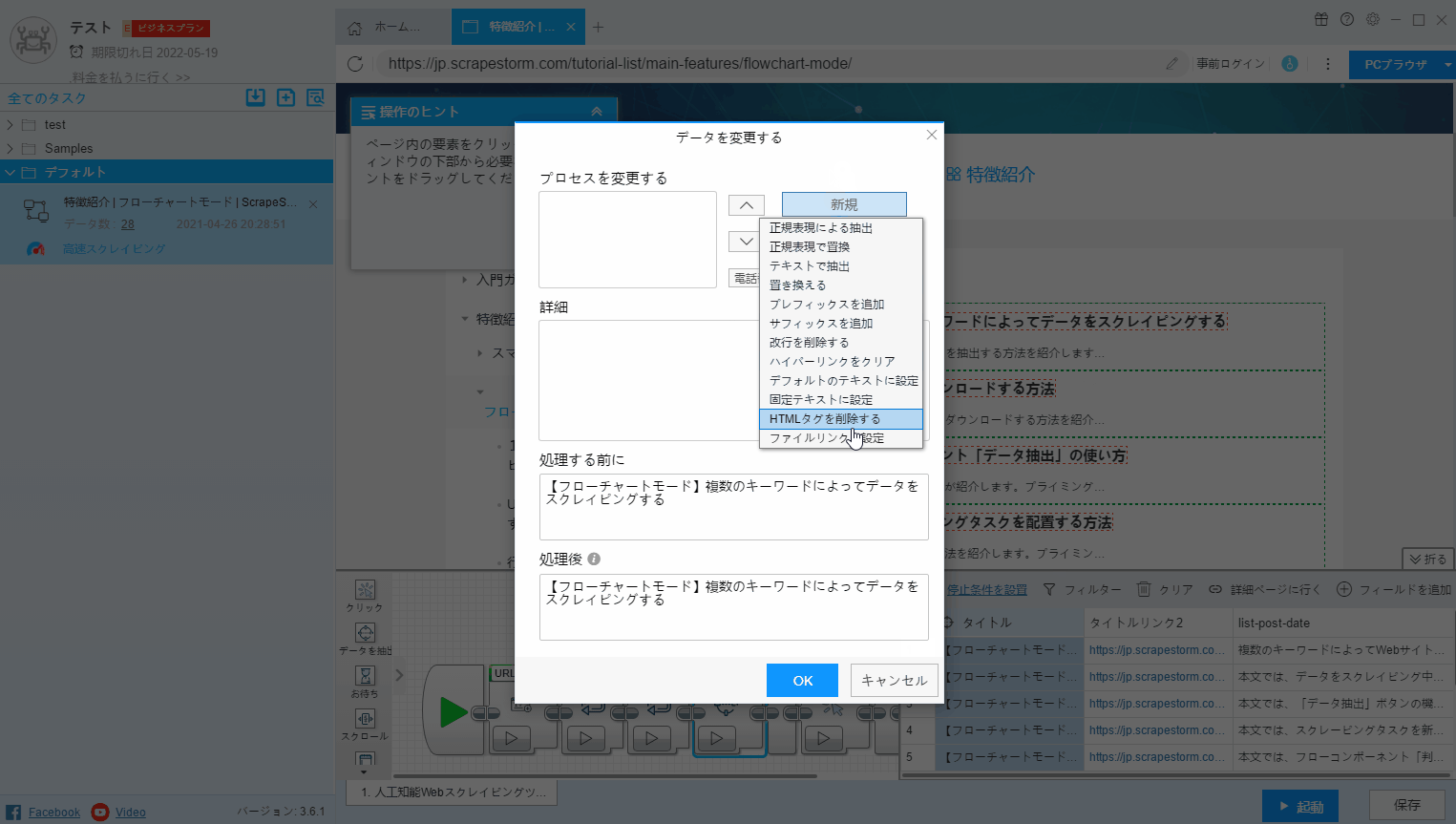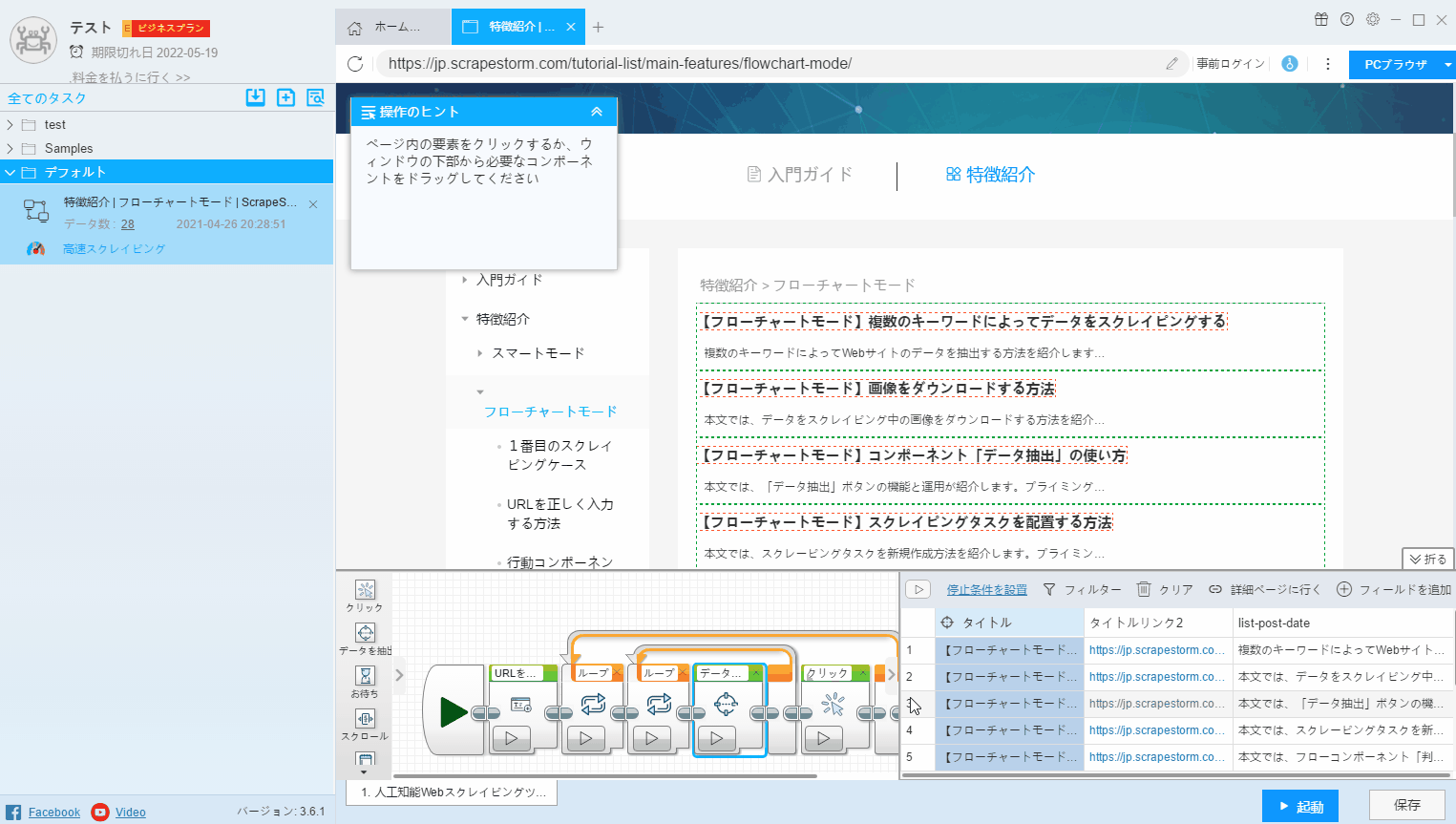
6.データを修正する
抽出されたフィールドのコンテンツに対して何らかの処理を行う必要がある場合があります。たとえば、フィールドの数字とメールのみが必要な場合、フィールドのテキストを新しいテキストに置き換える、先頭と末尾の空白文字をクリアする、または新しい正規表現を作成するなど、「データを修正する」ボタンで実現されます。
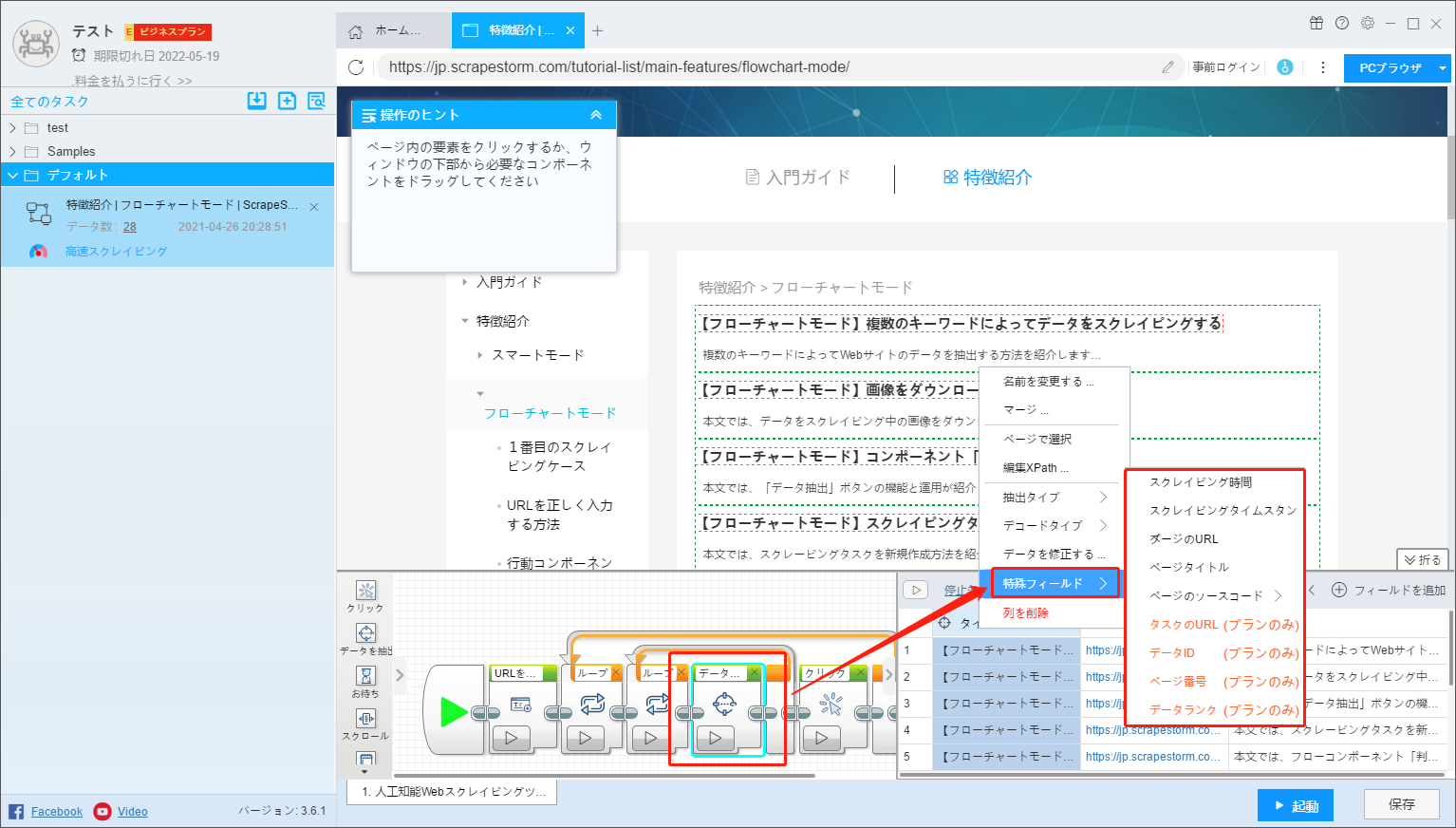
7. 特殊フィールド
一部のユーザーは、スクレイピング時間、ページソースコード、現在のページタイトル、現在のページURLなどの特別なフィールドをスクレイピングする必要があります。
これらのフィールドをWebページで直接スクレイピングすることはできません。「特殊フィールド」を使用してフィールドを設定できます。 ユーザーは、新しいフィールドを作成したり、フィールドを特別なフィールドに変更したり、元のフィールドを特別なフィールドに変更したりできます。
8. 列を削除
フィールドを右クリックして[列を削除]を選択するか、CtrlまたはShiftを押して複数のフィールドを削除します。
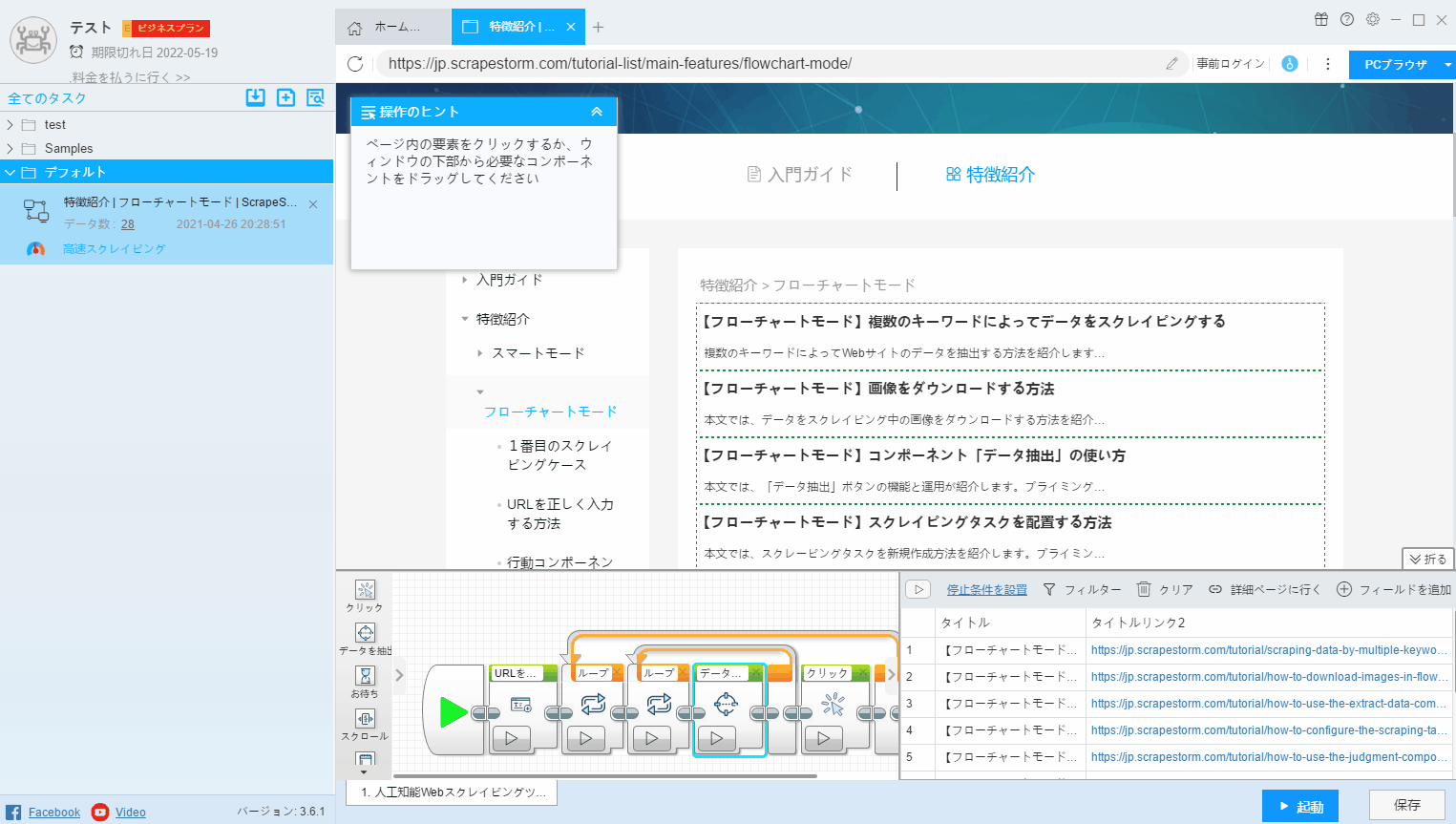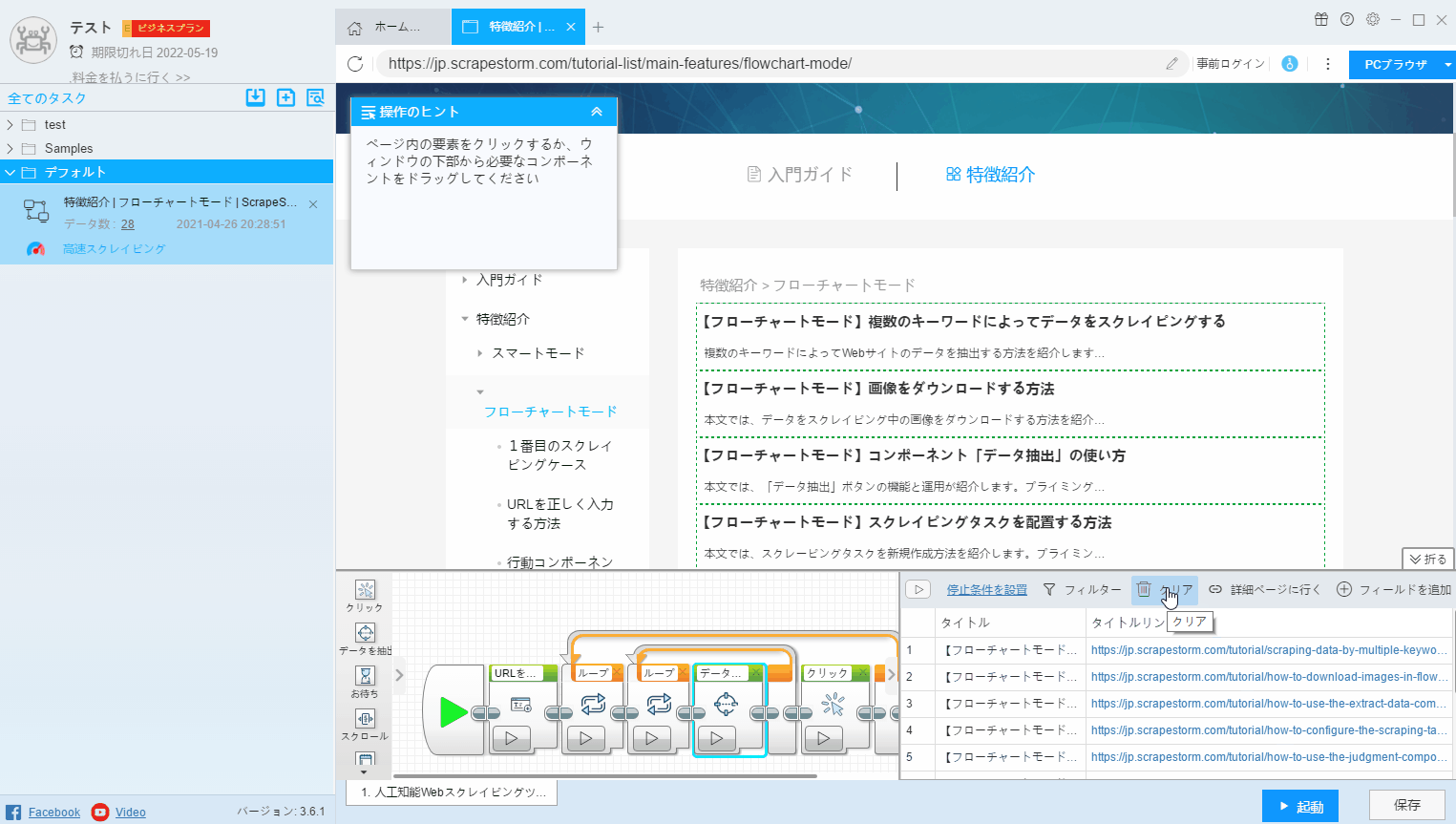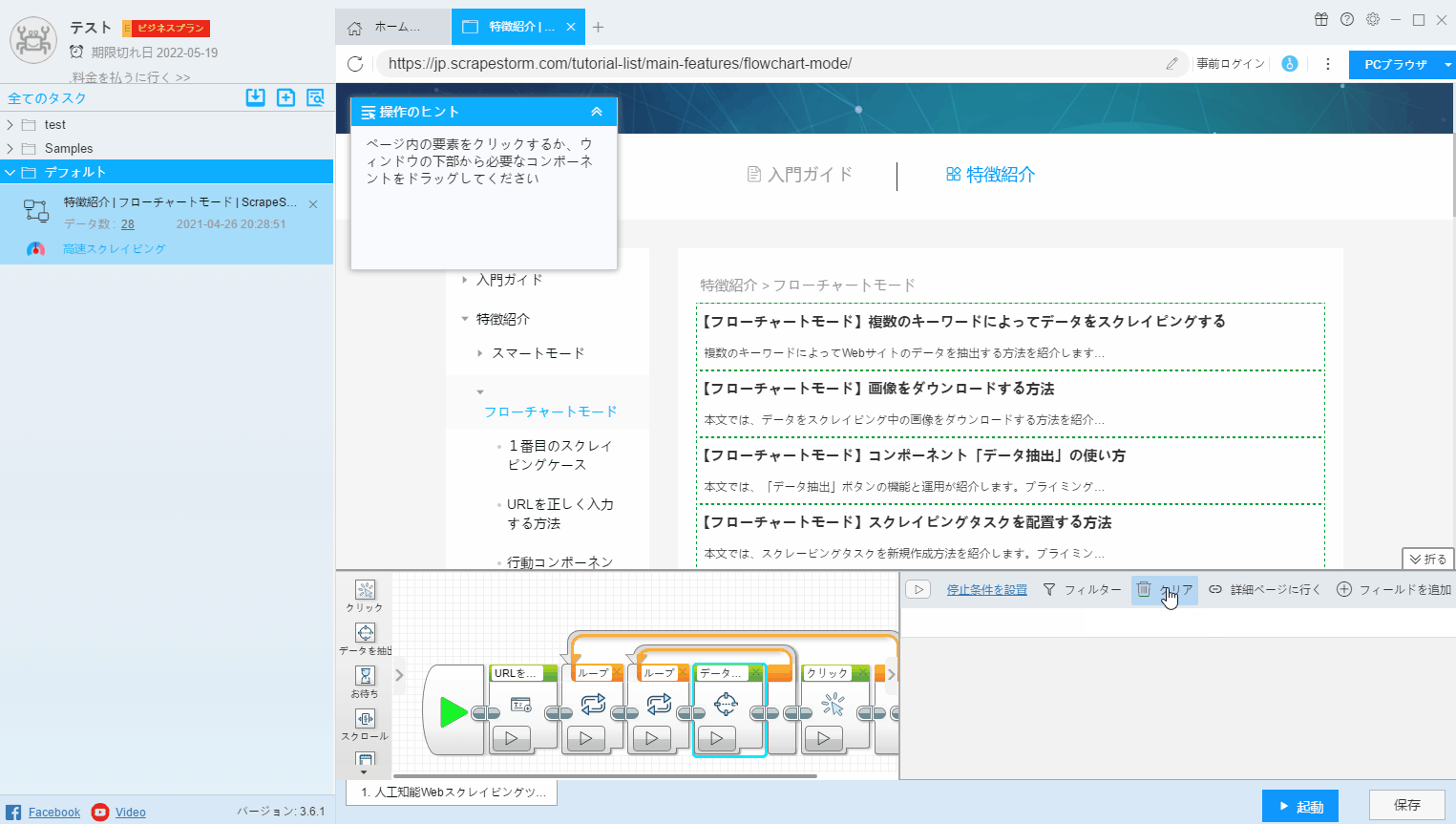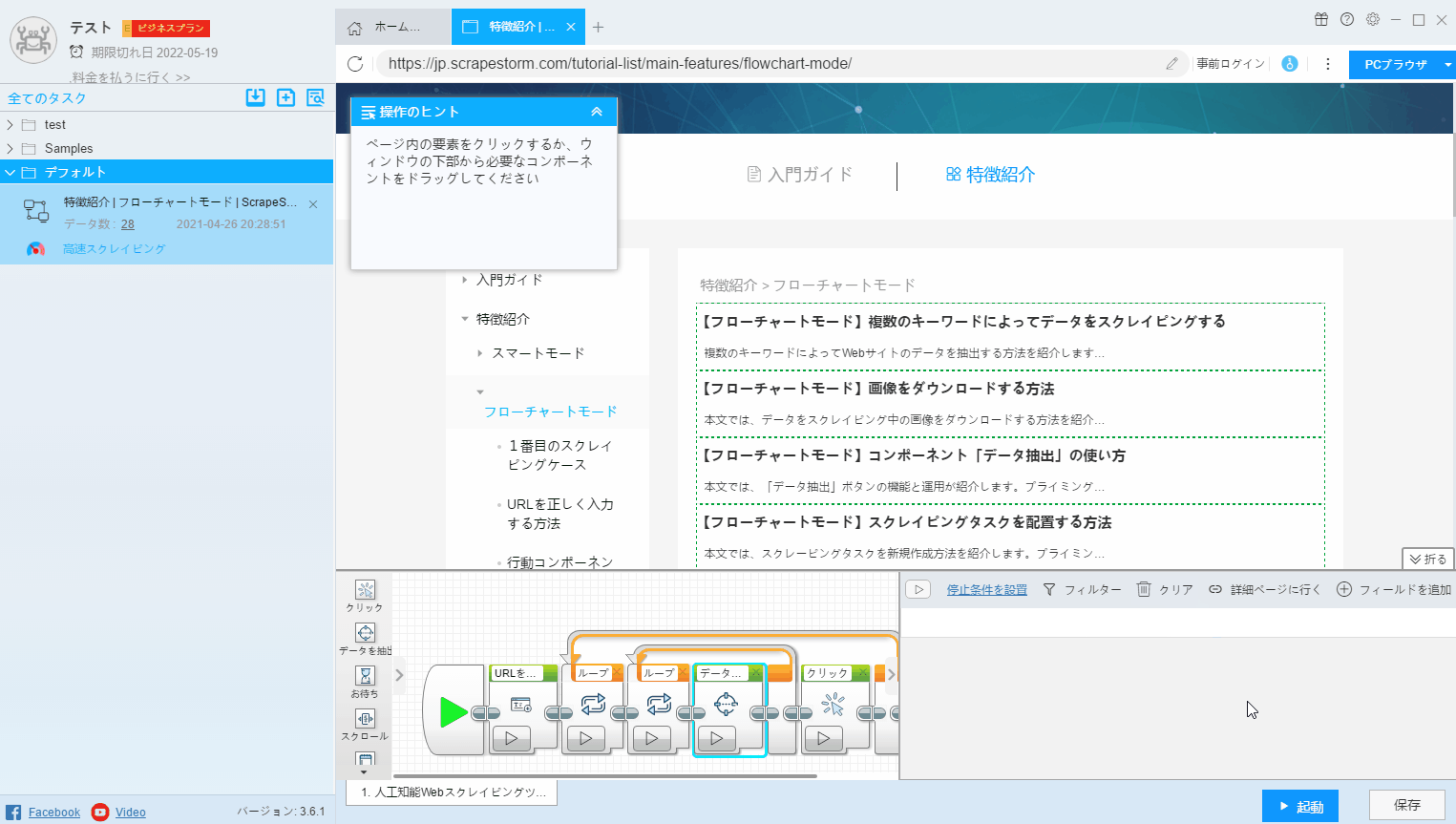
9. クリア
もし自動的に識別するフィールドを必要としない場合、「クリア」をクリックしてフィールドをクリアし、必要なフィールドをリセットできます。
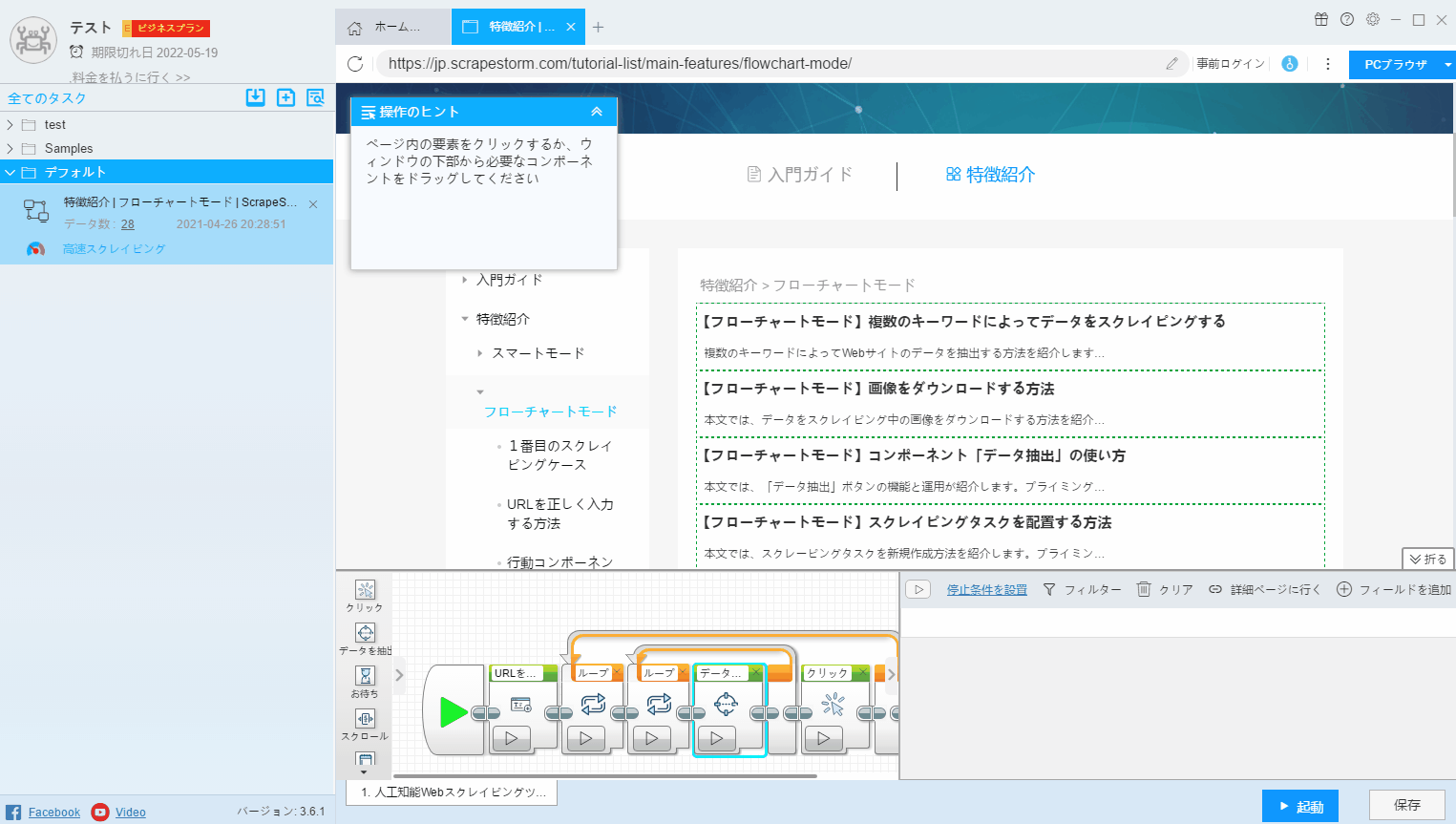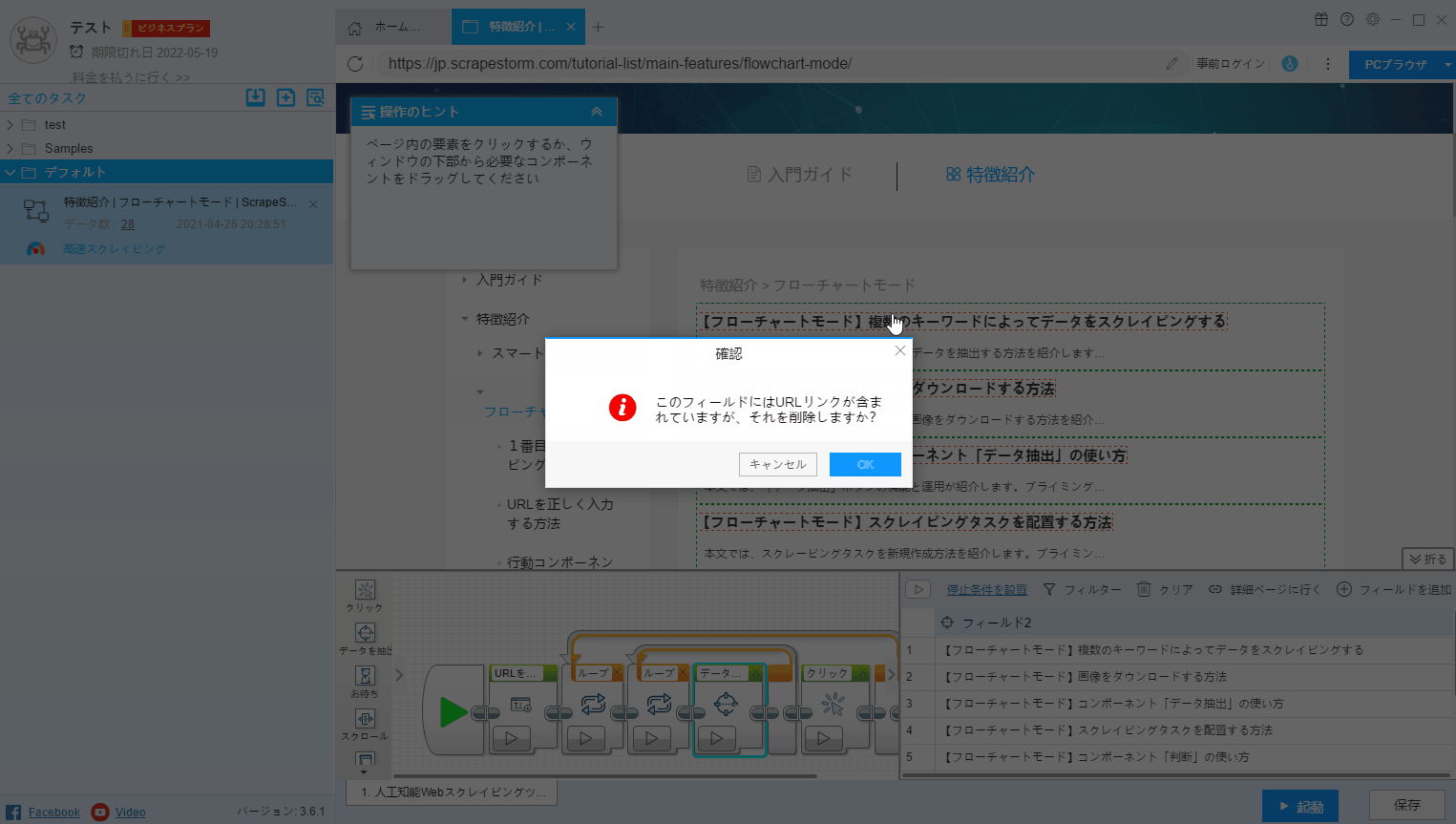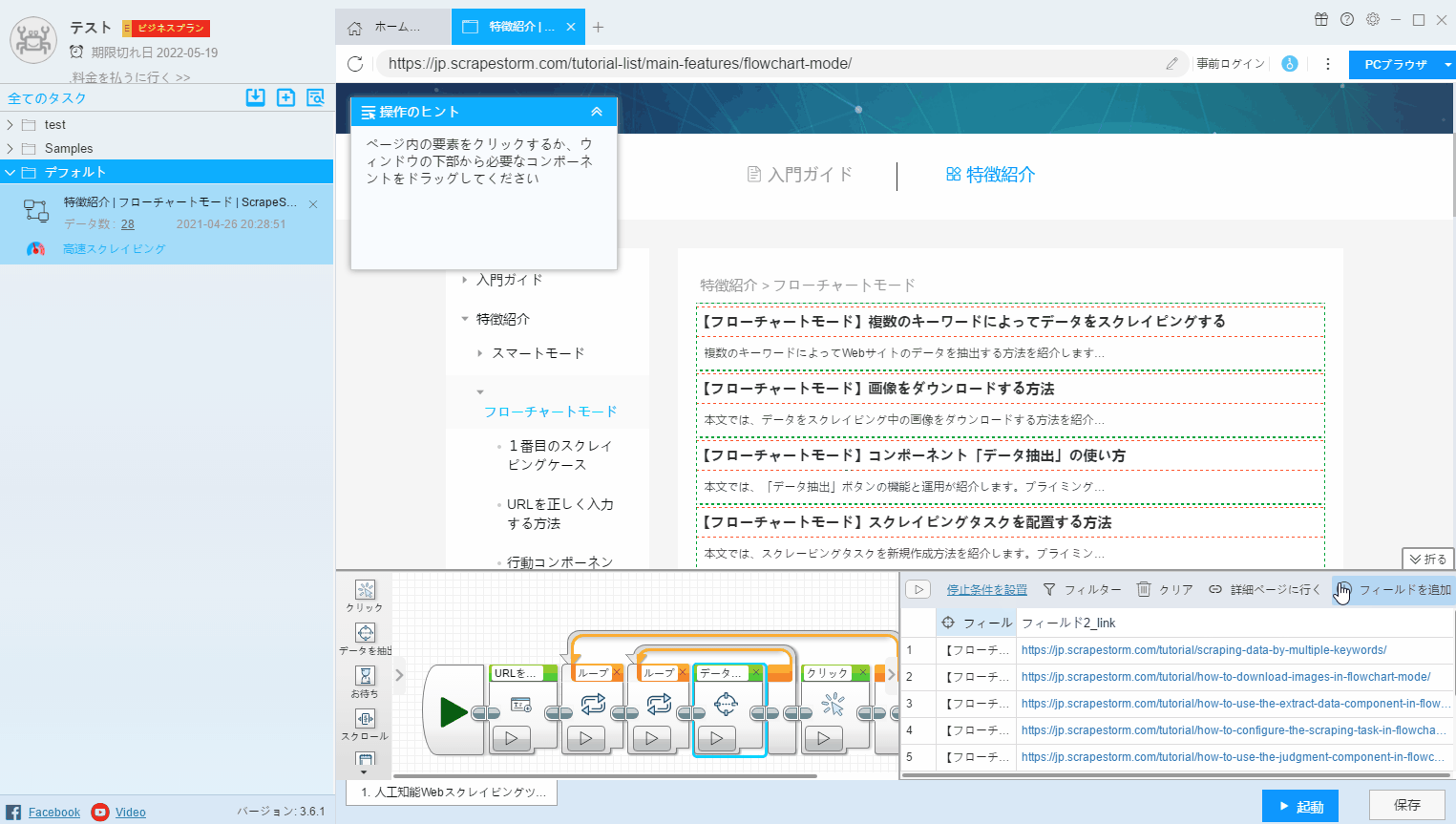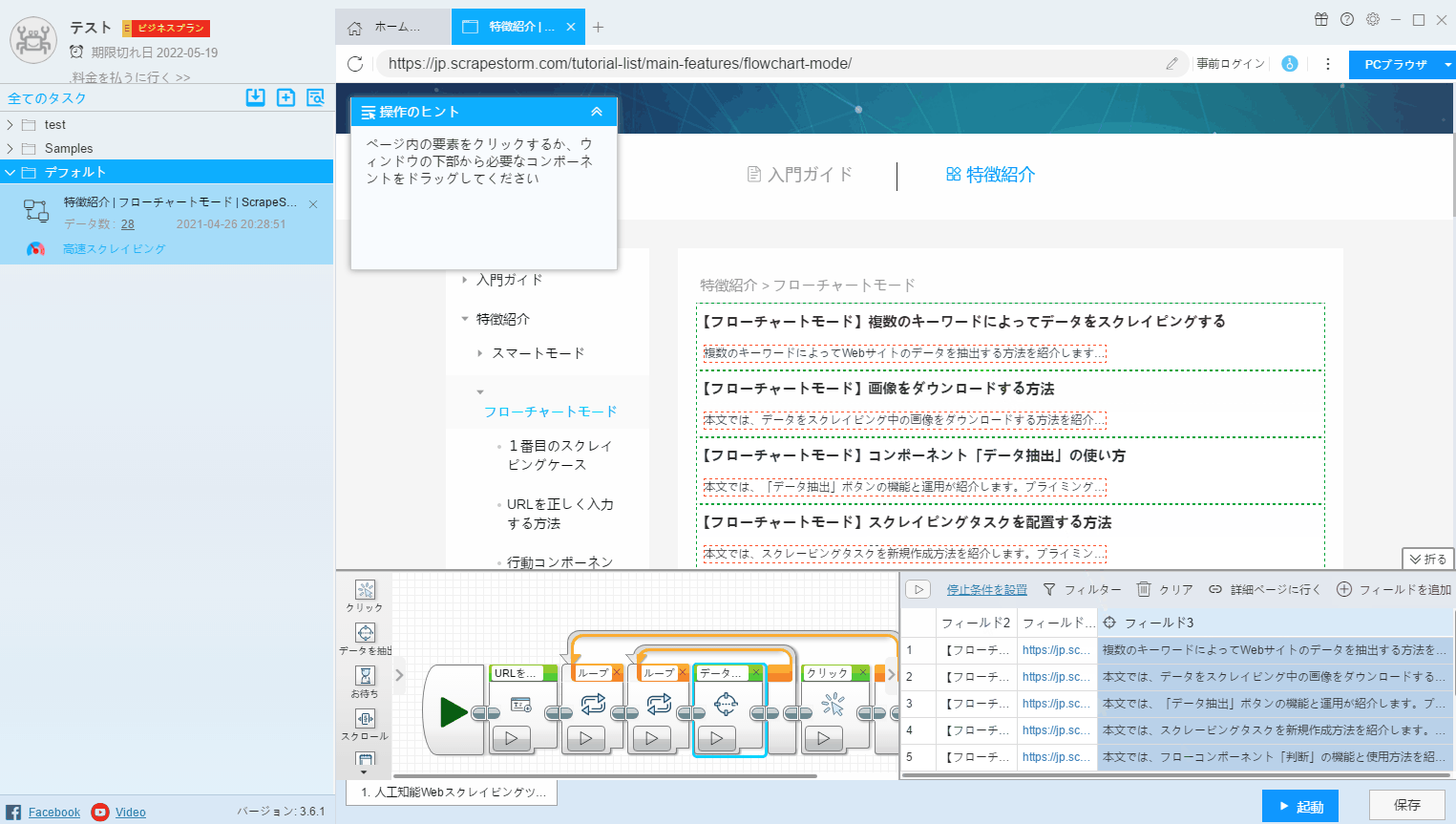
10. フィールドを追加
新しいフィールドを追加する場合は、右上隅の「フィールドを追加」をクリックし、新しく追加したフィールドを右クリックして「ページで選択」をクリックし、ページから必要なデータを抽出します。
11.フィルター
フィルターの詳細については、ここをクリックしてください。