すべてのデータが収集される前にスクレイピングが停止した場合はどうすればよいですか? | Webクローラ | ScrapeStorm
摘要:「すべてのデータが収集される前にスクレイピングが停止した場合はどうすればよいですか?」という質問に対する回答です。 ScrapeStorm無料ダウンロード
質問:
すべてのデータが収集される前にスクレイピングが停止した場合はどうすればよいですか?
回答:
1. まず、ウェブサイトのコレクションにログインが必要かどうかを確認します。 ブラウザでコピーしたリンクではログイン状態が保存されないため、ソフトウェアで再度ログインする必要があります。 ログインはソフト右上の事前ログインで行います。
事前ログイン機能の設定については、以下のチュートリアルを参照してください。
2. Web ページで実際にどれだけ閲覧できるかを確認します。検索したデータを表示するのではなく、実際に Web ページで閲覧できるデータの量を表示します。 数万件のデータを表示しているサイトもありますが、実際には数千件しか閲覧できませんので、手動で最後のページにジャンプして実際のデータ量を確認することをお勧めします。
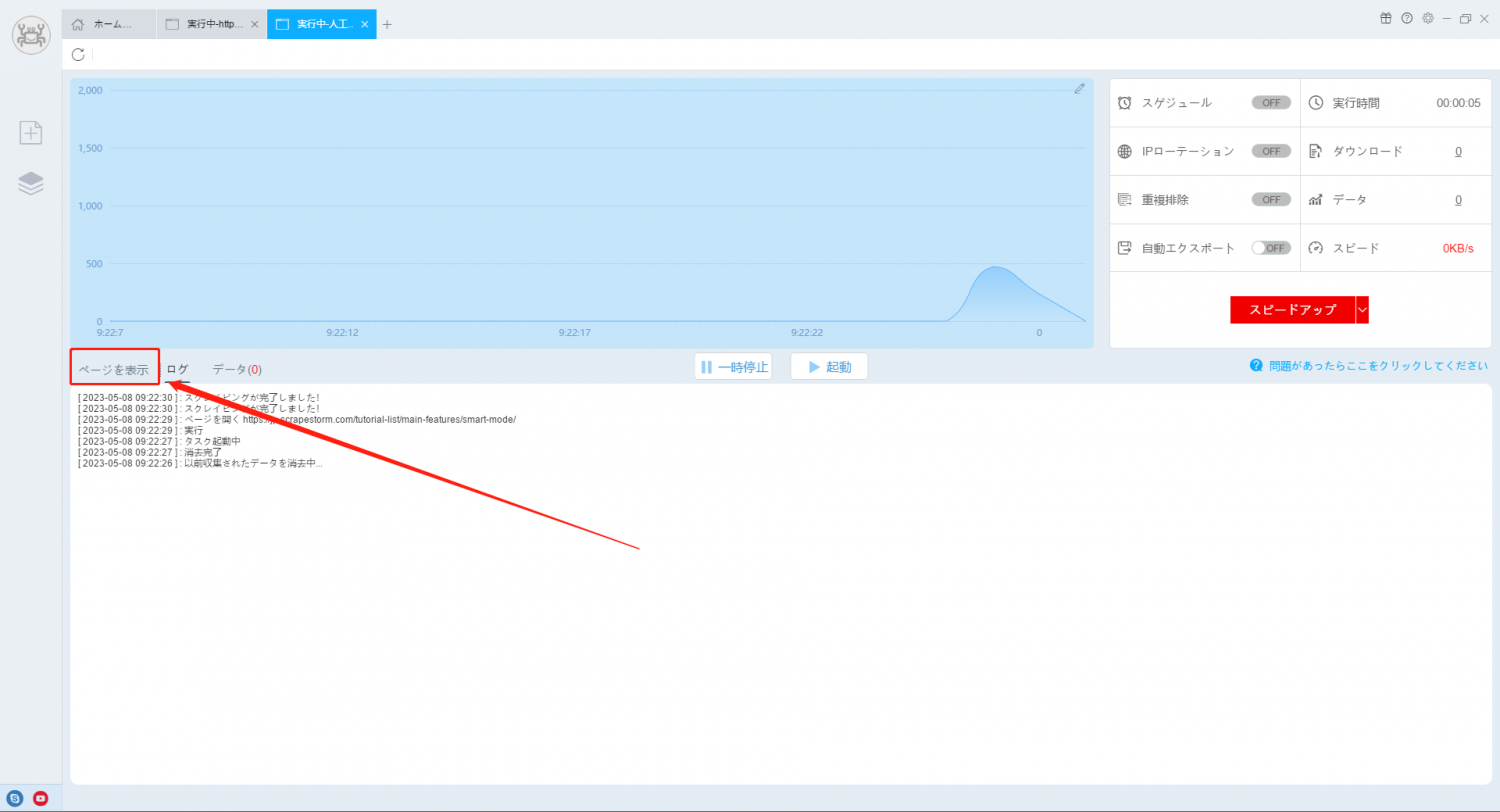
3. 「ページを表示」ボタンをクリックして、実際にWebページを実行中のオープン状態、制限されているかどうか、ポップアップウィンドウが表示されているかどうかを確認します。
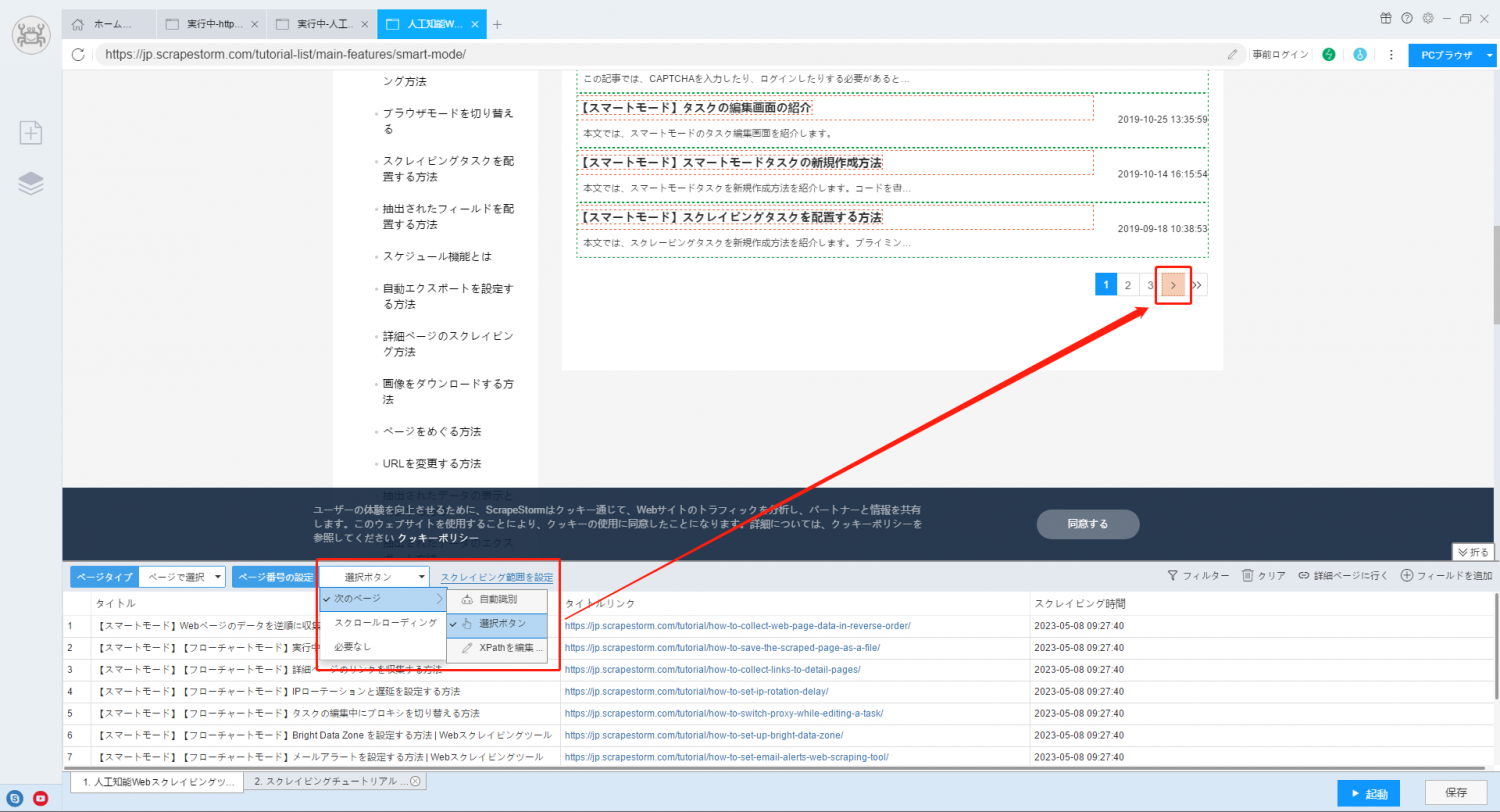
4. Web ページのページめくり認識が正しい認識するかどうかを確認します。自動認識ではエラーが発生している可能性がありますので、手動で認識することをお勧めします。 ページめくり認識は、2 ページ目のボタンではなく、次のページ ボタンを認識する必要があります。
ページめくりの設定については、以下のチュートリアルを参照してください。
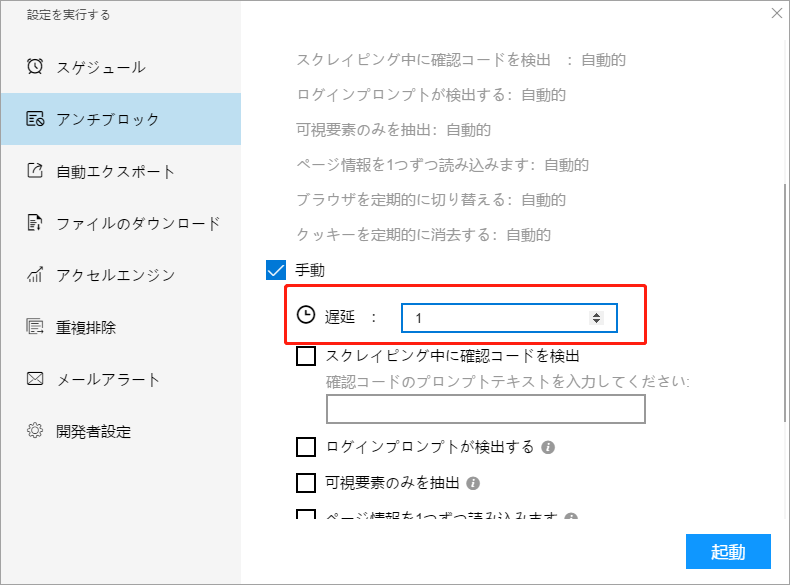
5. すべてのデータがWebページ上に表示され、制限されていない場合、その原因はネットワーク速度の問題である可能性があり、ソフトウェアは何度も収集を繰り返してWebページをロードしていないので、その場合はアンチブロックに遅延時間を設定してください。
6. 上訴すべての原因を確認し、それともすべてのデータを収集していないか、ページ番号の変動に伴いサイトのURLが変動するかどうかを確認し、変動する場合は、スクレイピング終了位置のサイトを直接コピーし、ソフトウェアに貼り付け、停止した部分からスクレイピングを開始します。
下記のチュートリアルを参照してください。