【スマートモード】タスクの編集画面の紹介 - ScrapeStorm
摘要:本文では、スマートモードのタスク編集画面を紹介します。 ScrapeStorm無料ダウンロード
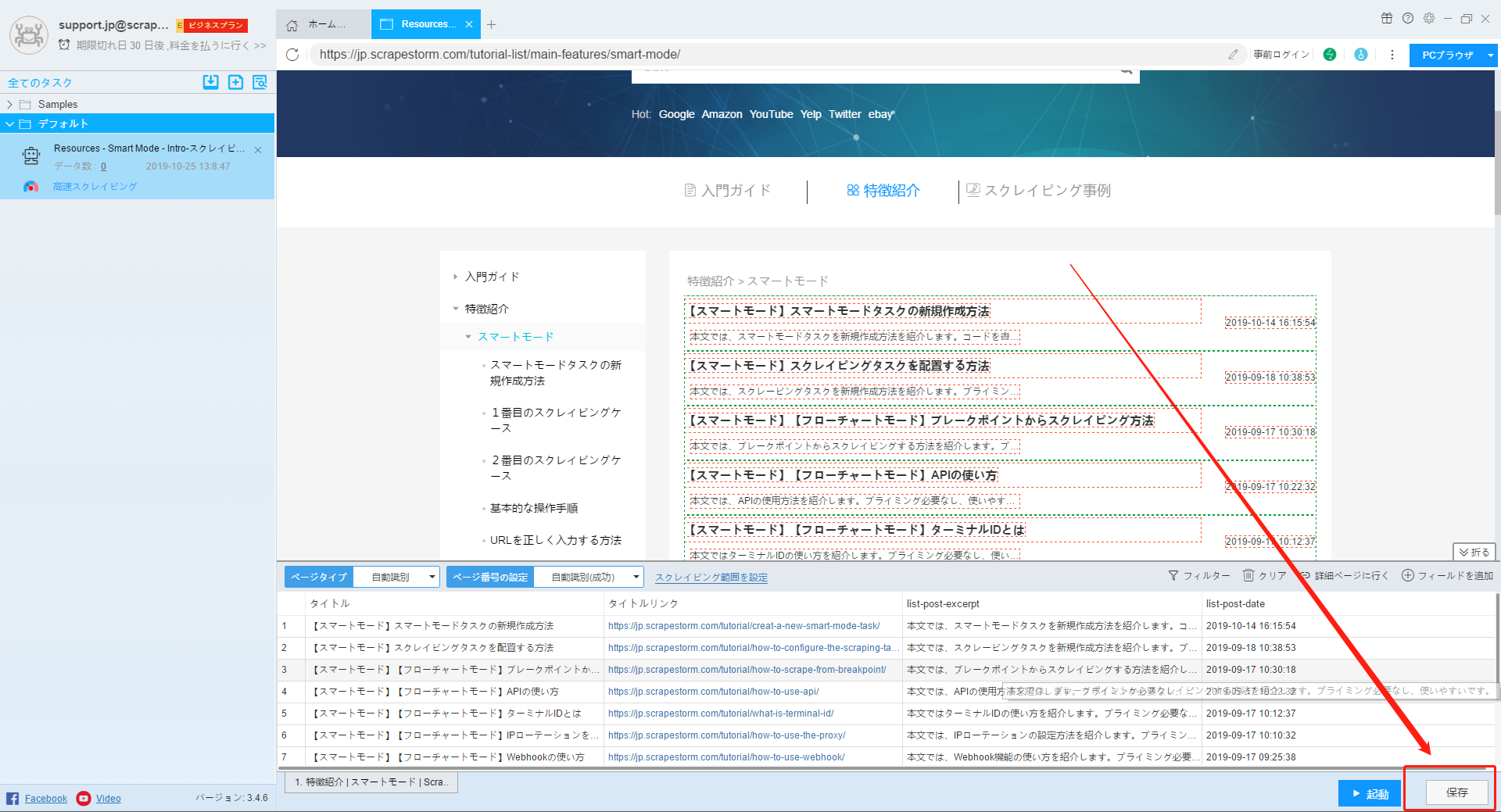
タスクを新規作成した後、編集画面に行きます。本文では、タスクの編集画面を簡単に紹介します。
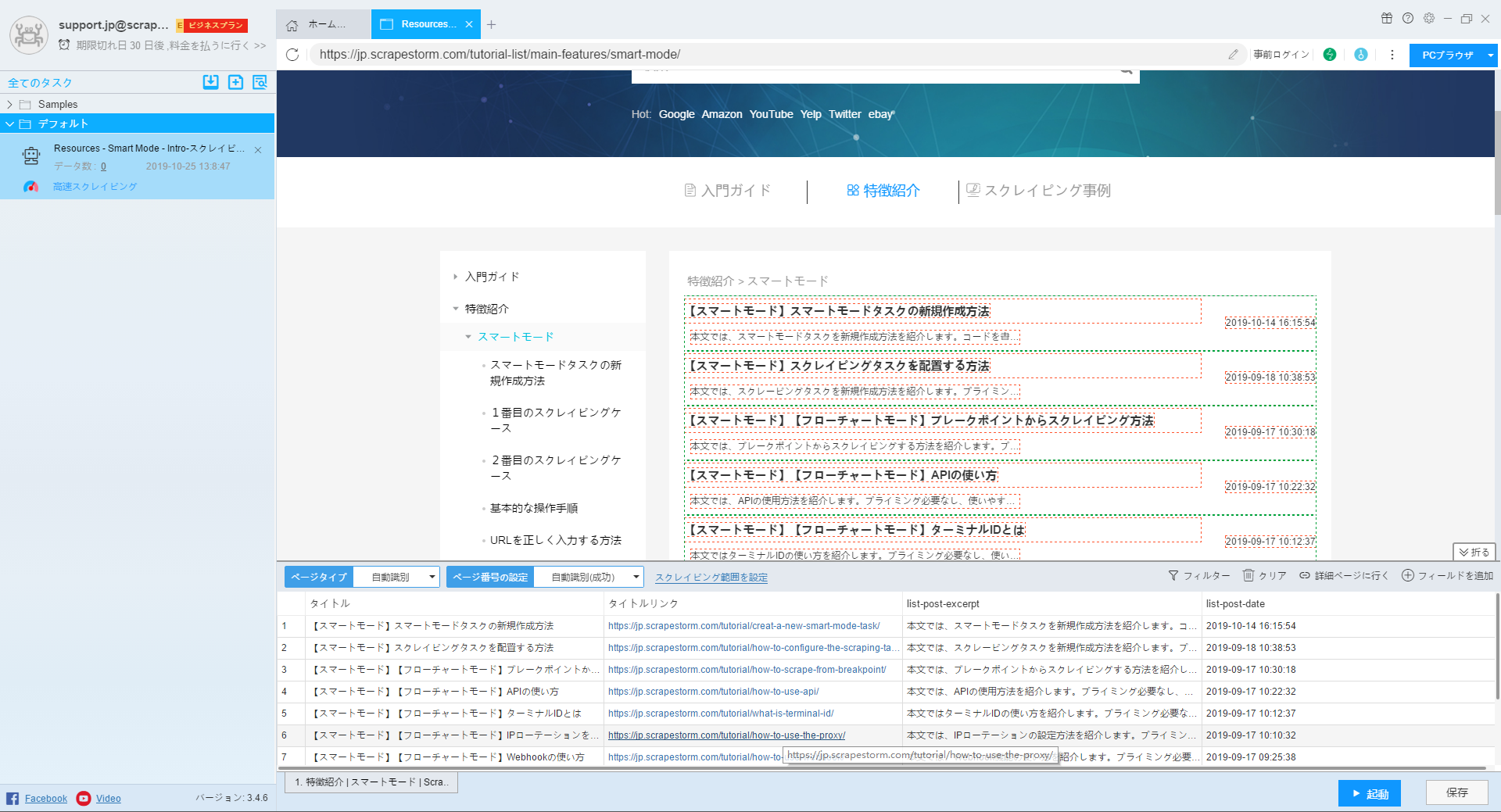
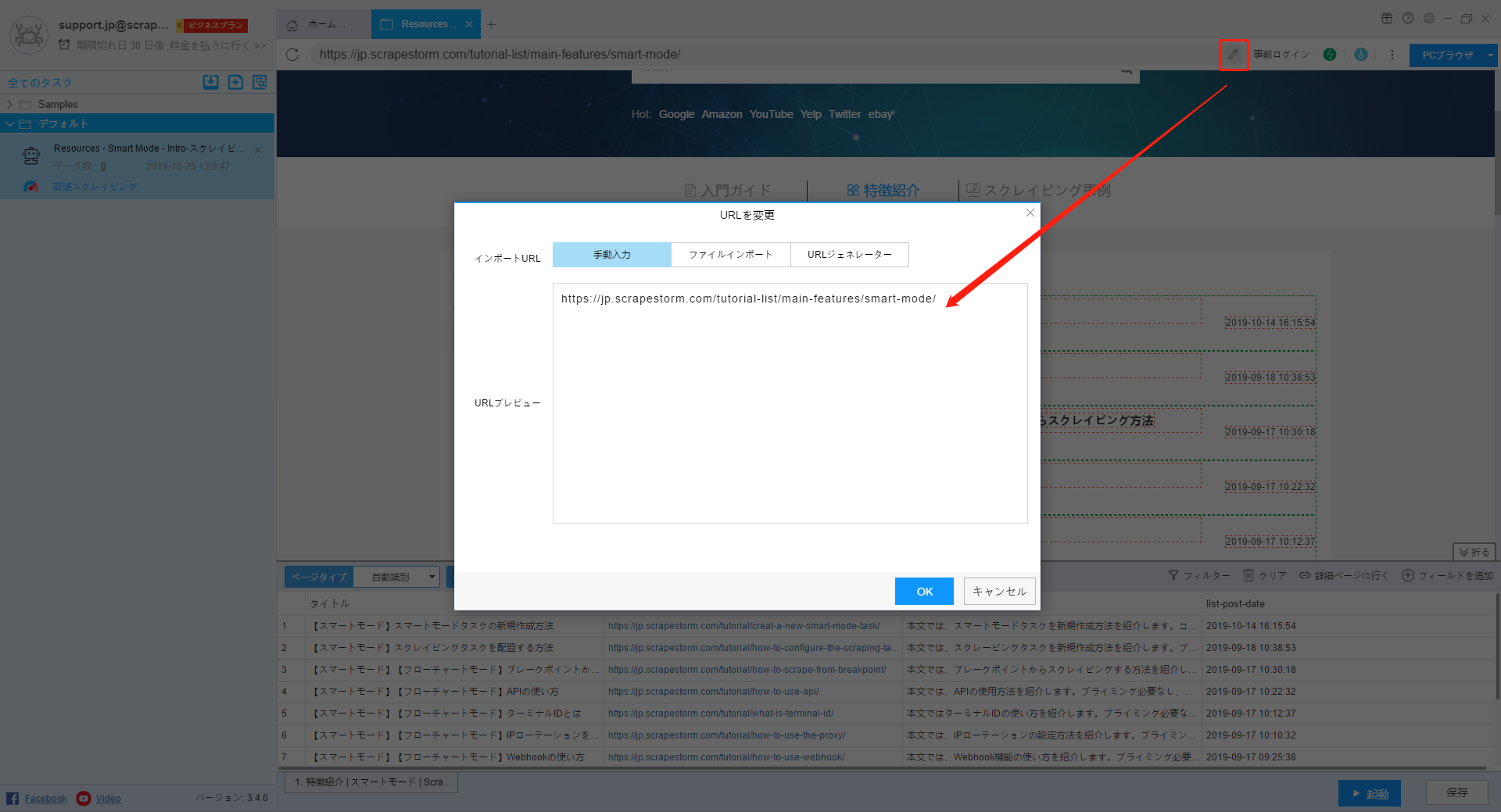
1.URLの変更
下記の画像のようなアイコンをクリックして、URLを変更できます。但し、200以上の変更はローカルのファイルで編集してください。
ヒント:こちらの変更はローカルのファイルに影響を与えません。
URL編集の詳細はこちらでご参照ください。
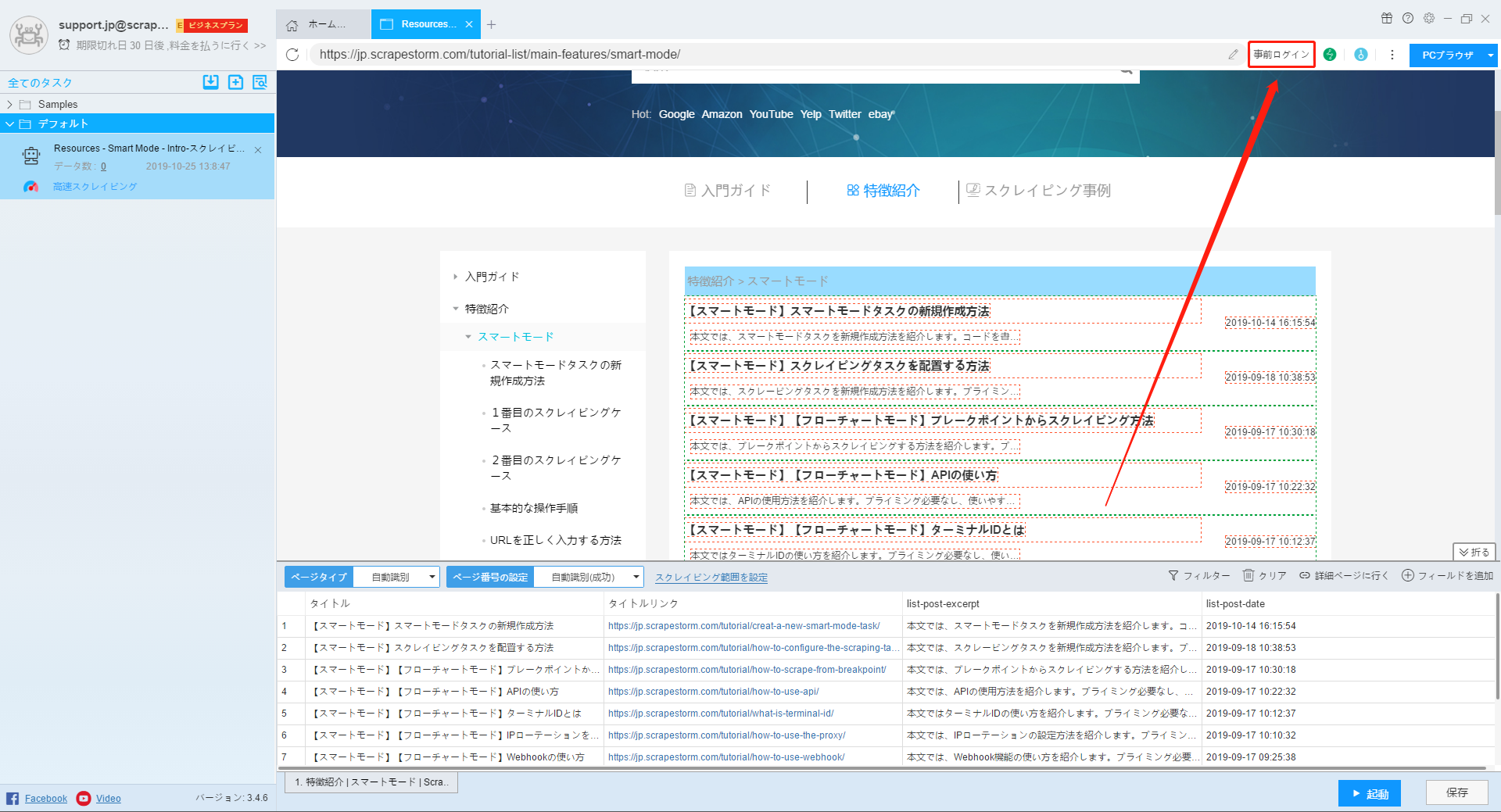
2.事前ログイン
ログイン必要なページをスクレイピングする時、事前ログイン機能をご利用ください。
事前ログインの詳細はこちらでご参照ください。
3.事前操作
下記の画像のようなアイコンをクリックして、事前操作ができます。
事前操作にはフローチャートモードにかなり似っていますので、フローチャートモードの操作をご参照ください。

4.キャプチャーの解決
下記の画像のようなアイコンをクリックして、キャプチャーを手動で解決できます。
5.プロキシサーバー
キャプチャーとその他にブラックされた時、プロキシを切り替えがちゃんと役に立ちます。
6.Webセキュリティーオプション
Webページはエラーが発生したときにこの機能を試すことができますが、このオプションを開くと、ページ上の一部のコンテンツ(iframe内のコンテンツなど)がスクレイプされない場合があることに注意してください。
7.ブラウザーの切り替え
一部のWebページには、コンピューターと携帯電話で異なるコンテンツが表示されます。 通常、ソフトウェアはデフォルトでコンピューターバージョンのWebページをスクレイピングします。 ユーザーがモバイル版のWebページをスクレイピングしたい場合は、ブラウザーモードを切り替えることでスクレイピングできます。
ブラウザーの切り替えの詳細はこちらでご参照ください。
8.ページタイプの設定
通常、ソフトウェアはページタイプを自動的に識別します。 識別できないWebページに遭遇した場合、xpathを編集または手動で識別に変更できます。 通常、ソフトウェアはデフォルトでリストモードページを識別します。 詳細ページの場合は、手動で変更する必要があります。
ページタイプの設定の詳細はこちらでご参照ください。
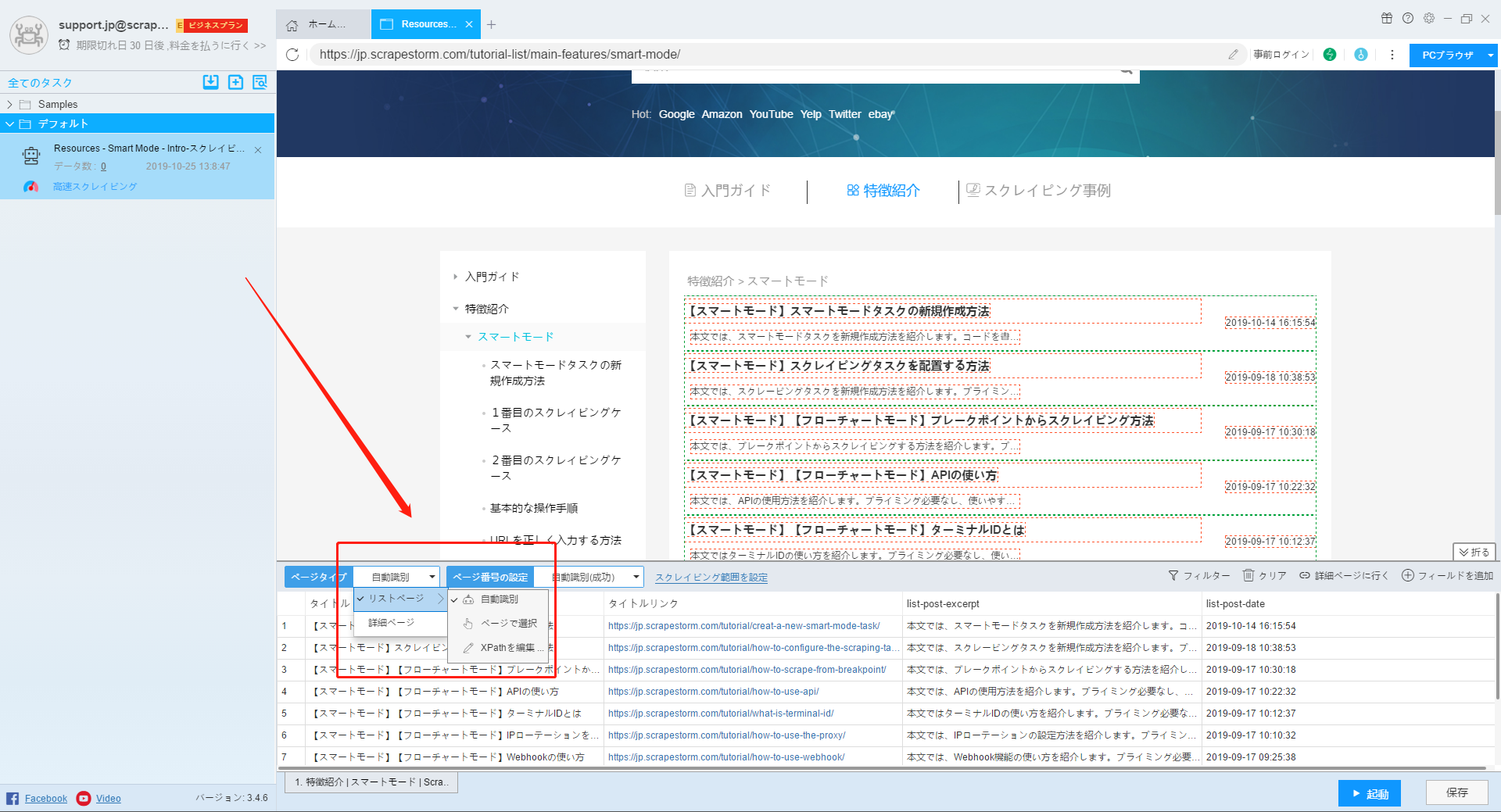
9.ページ番号の設定
ソフトウェアは通常、ページネーションを自動的に認識します。 自動的に識別できないページの場合、ページボタンを手動で選択するか、xpathを変更できます。 詳細ページタイプのページが見つかった場合は、[必要なし]を選択してください。
ページ番号の設定の詳細はこちらでご参照ください。
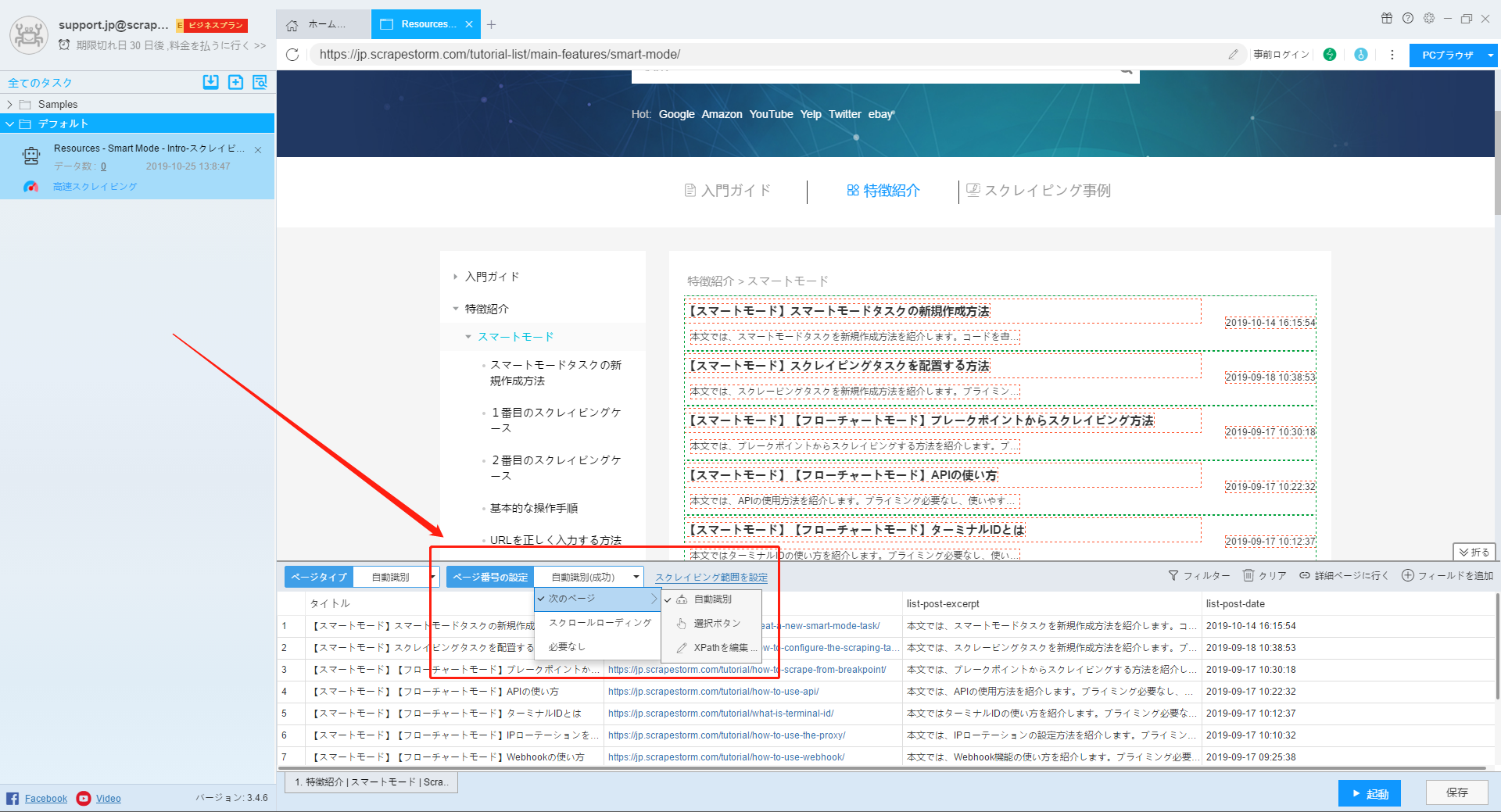
10.スクレイピング範囲の設定
この機能を使用して、開始ページと終了ページを設定したり、データのスキップとタスクの停止トリガーを設定したりできます。

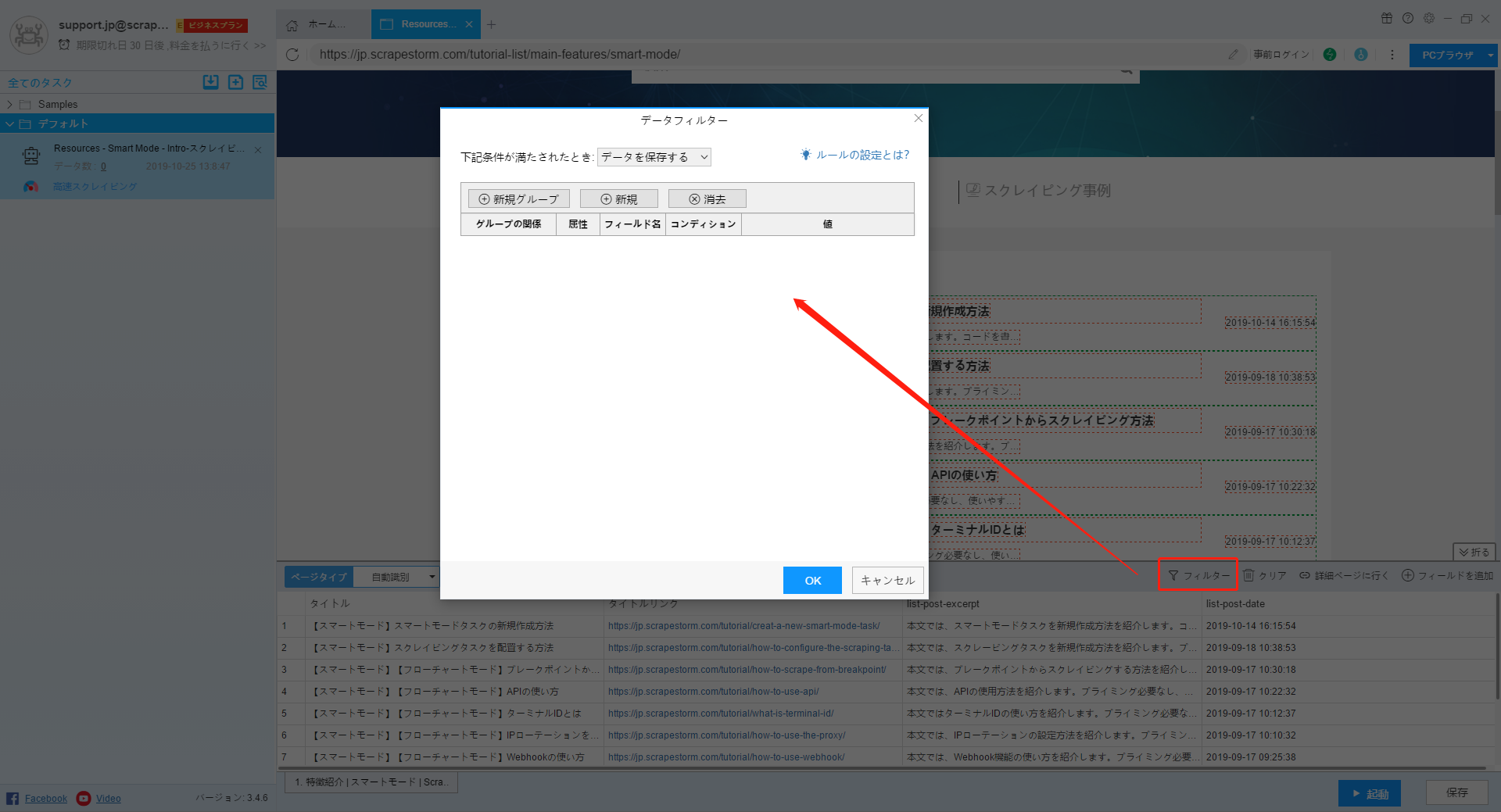
11.フィルター
下記の画像のようなアイコンをクリックして、データーのフィルターができます。
フィルターの詳細はこちらでご参照ください。
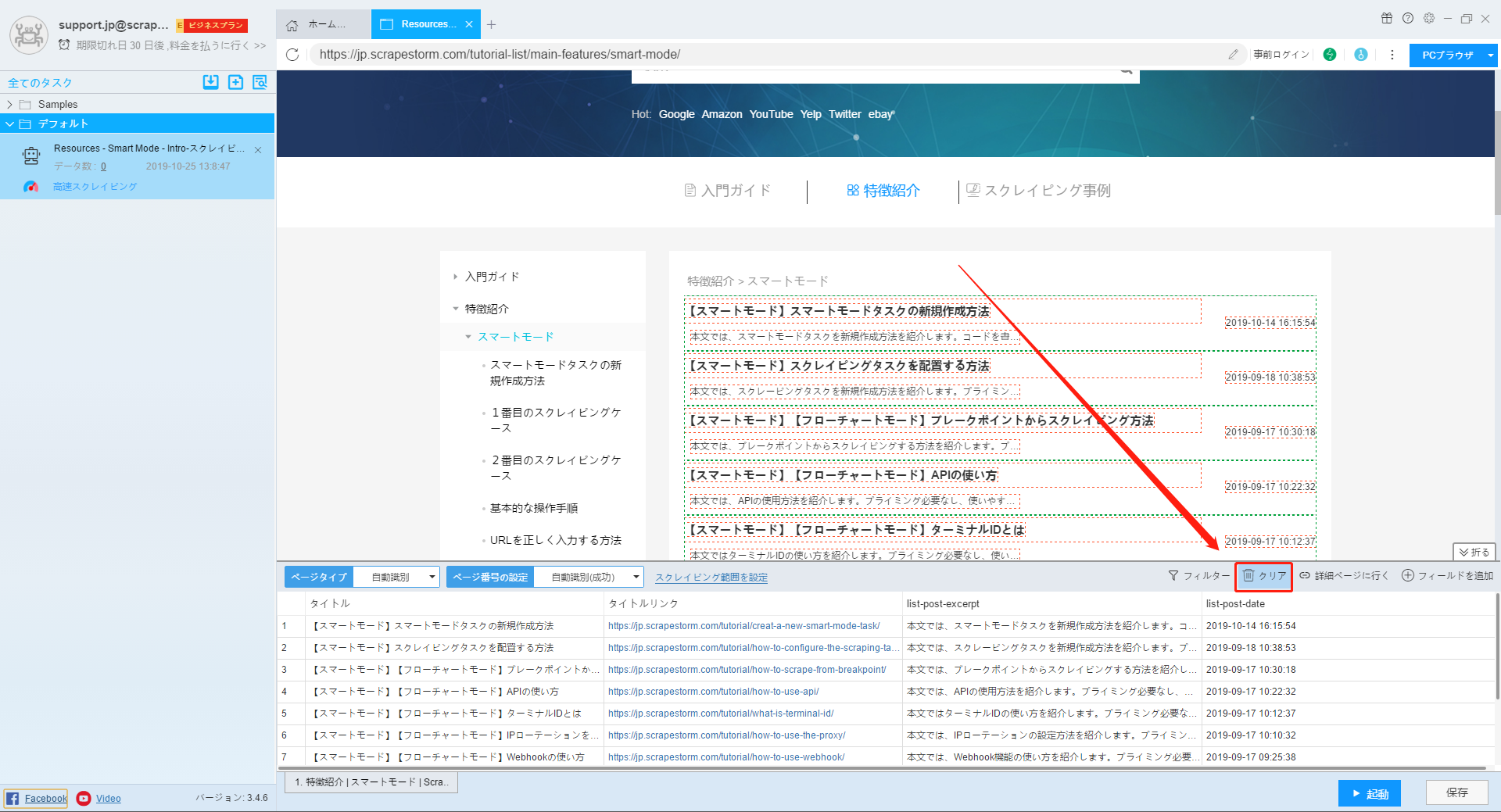
12.クリア
ソフトウェアによって自動的に識別されるデータに満足できない場合は、この機能を使用してすべてのデータをクリアし、フィールドの追加機能を使用して必要なデータを選択できます。
13.詳細ページに行く
詳細ページのデータをスクレイピングする必要がある場合は、詳細ページに行く
機能を使用してスクレイピングできます。
詳細ページに行くの詳細はこちらでご参照ください。
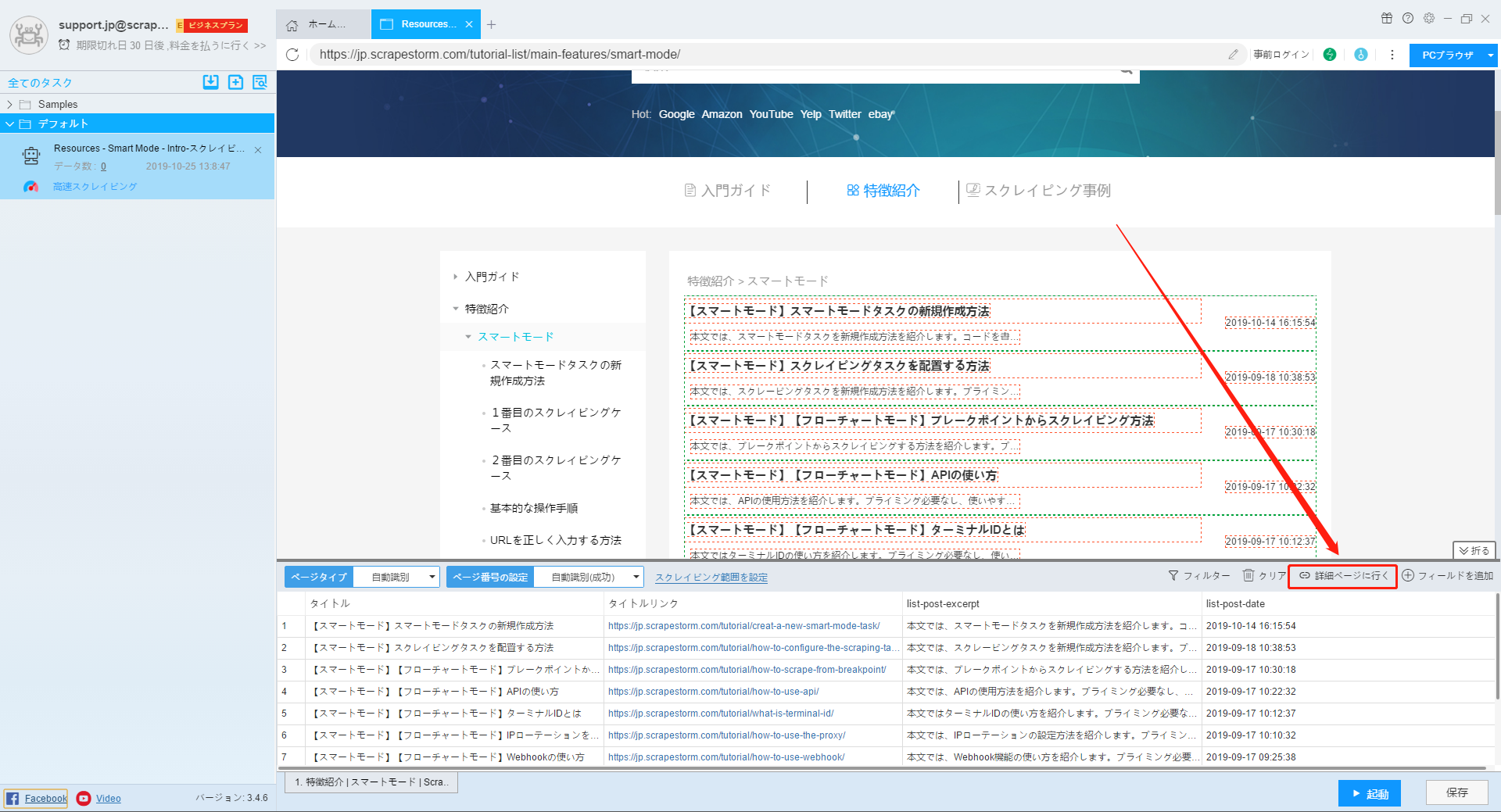
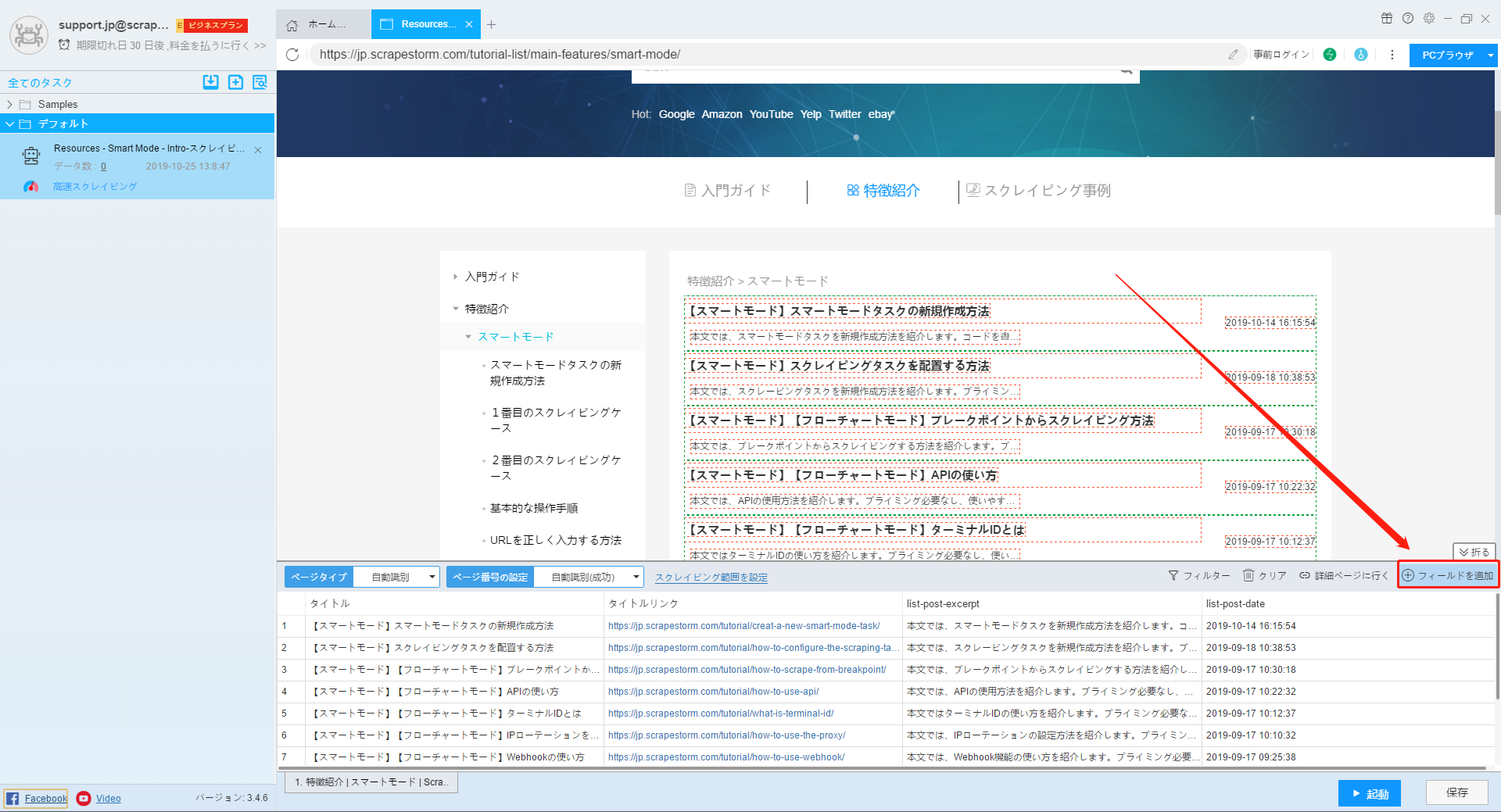
14.フィールドの追加
下記の画像のようなアイコンをクリックして、フィールドを追加できます。
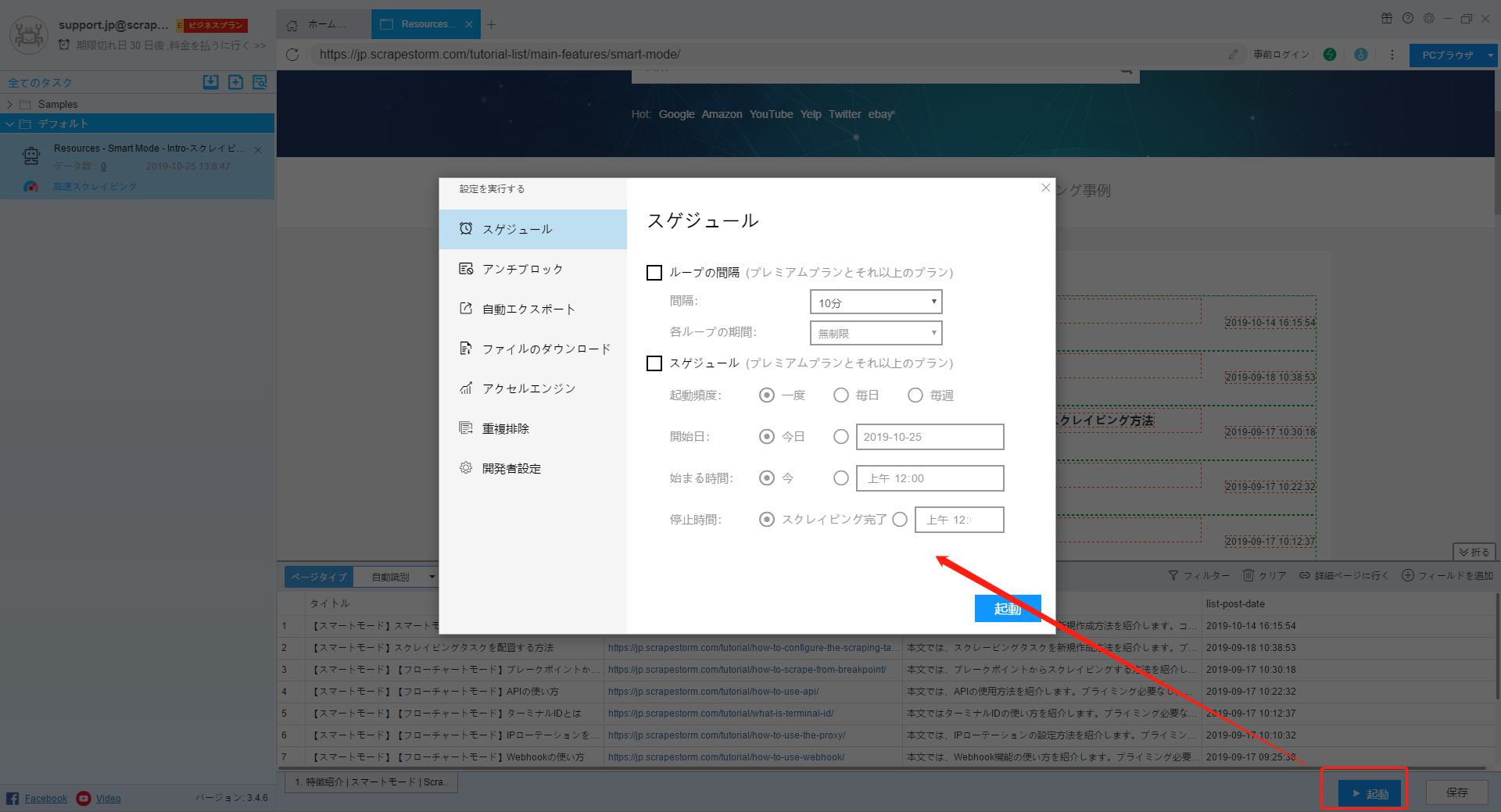
15.起動
タスクの設定が完了後、起動ボタンをクリックして、スクレイピングを開始します。
16.保存
タスクの設定が完了後、保存ボタンをクリックして、設定された条件を保存できます。