収集したデータが重複している場合はどうすればよいですか? | Webクローラ | ScrapeStorm
摘要:「収集したデータが重複している場合はどうすればよいですか?」という質問に対する回答です。 ScrapeStorm無料ダウンロード
質問:
収集したデータが重複している場合はどうすればよいですか?
回答:
1. ビデオチュートリアルを視聴したことを確認してください。 コレクション タスクでページタイプを設定することに問題はありません。つまり、単ページタイプをリストタイプに設定していないか、ループの使用方法を誤って理解していることを確認してください。
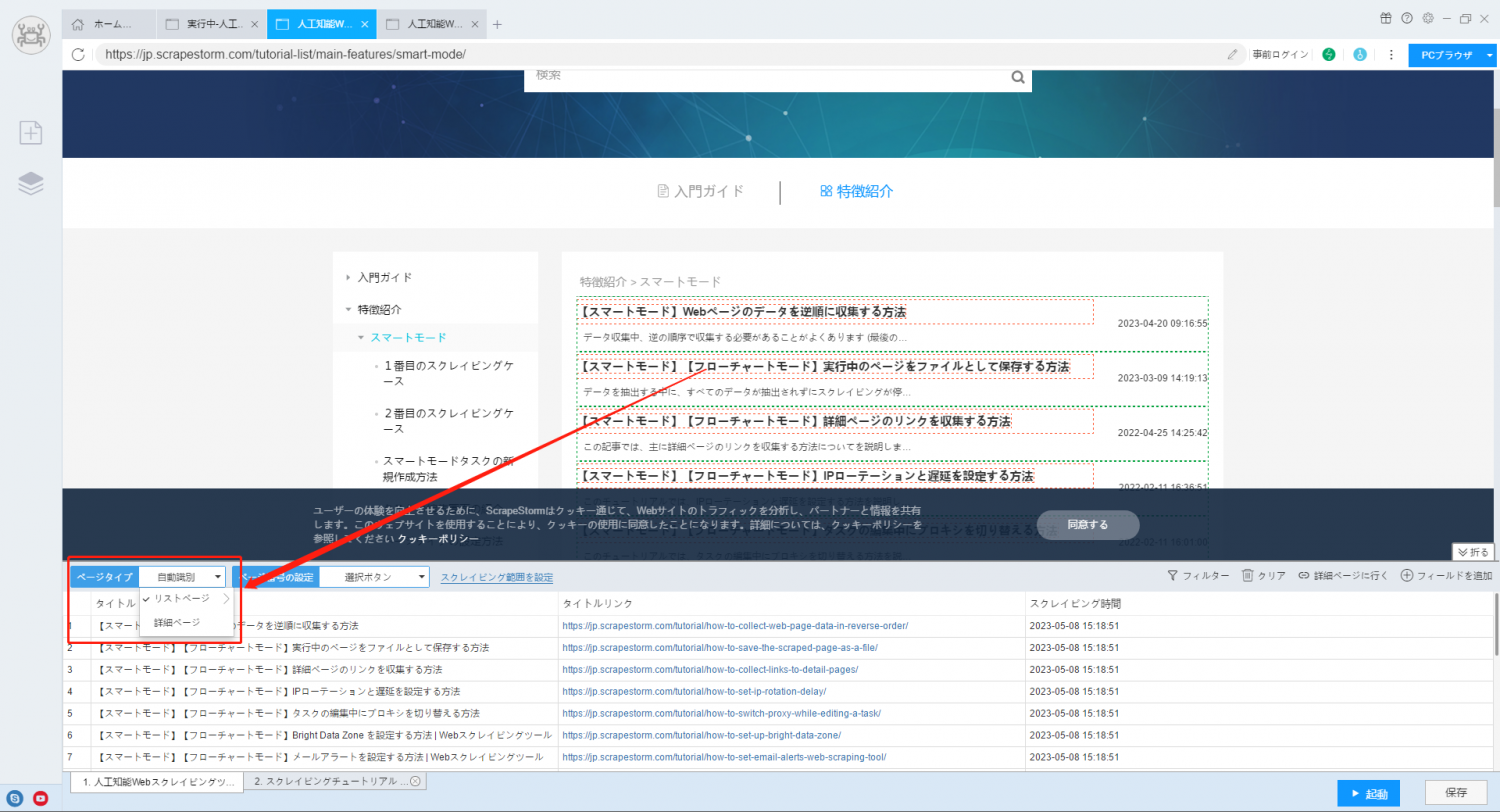
2. ソフトウェア自体にも重複排除機能があります。 この機能を有効にして、状況が改善するかどうかを確認できます。
重複排除機能の設定については、以下のチュートリアルを参照してください。
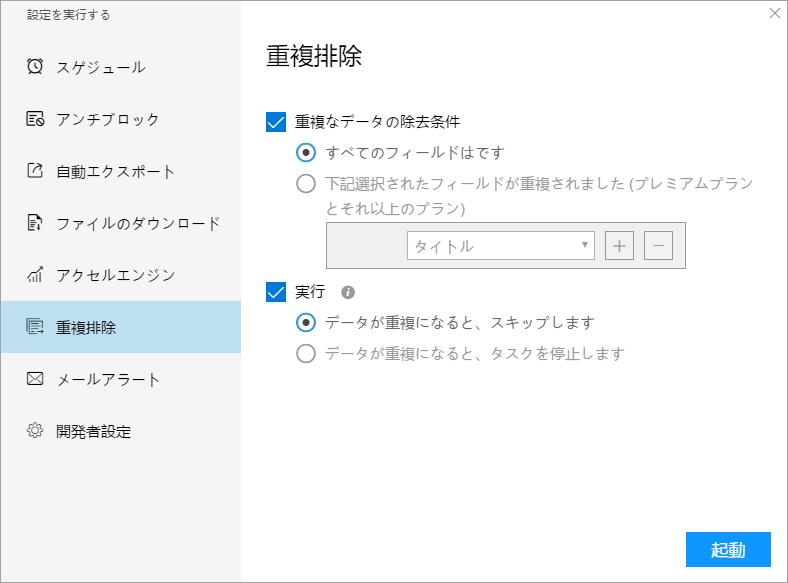
3. データ収集を何度も繰り返したのか、1 回の収集で繰り返しデータを収集したのかを判断してください。
タスクが変更されていない場合、タスクが実行されるたびに、そのたびにデフォルトで最初からスクレイピングを行い、重複したデータを収集されるのが正常です。
1 回の収集で重複が発生する場合は、次の条件が満たされているかどうかを確認してください。
① 繰り返されるデータは最後のページのデータです。これは、最後のページを収集した後にページめくりを停止できなかったことが原因である可能性があります。 スクレイピング範囲を変更して、重複データが引き続き発生するかどうかを確認してください。
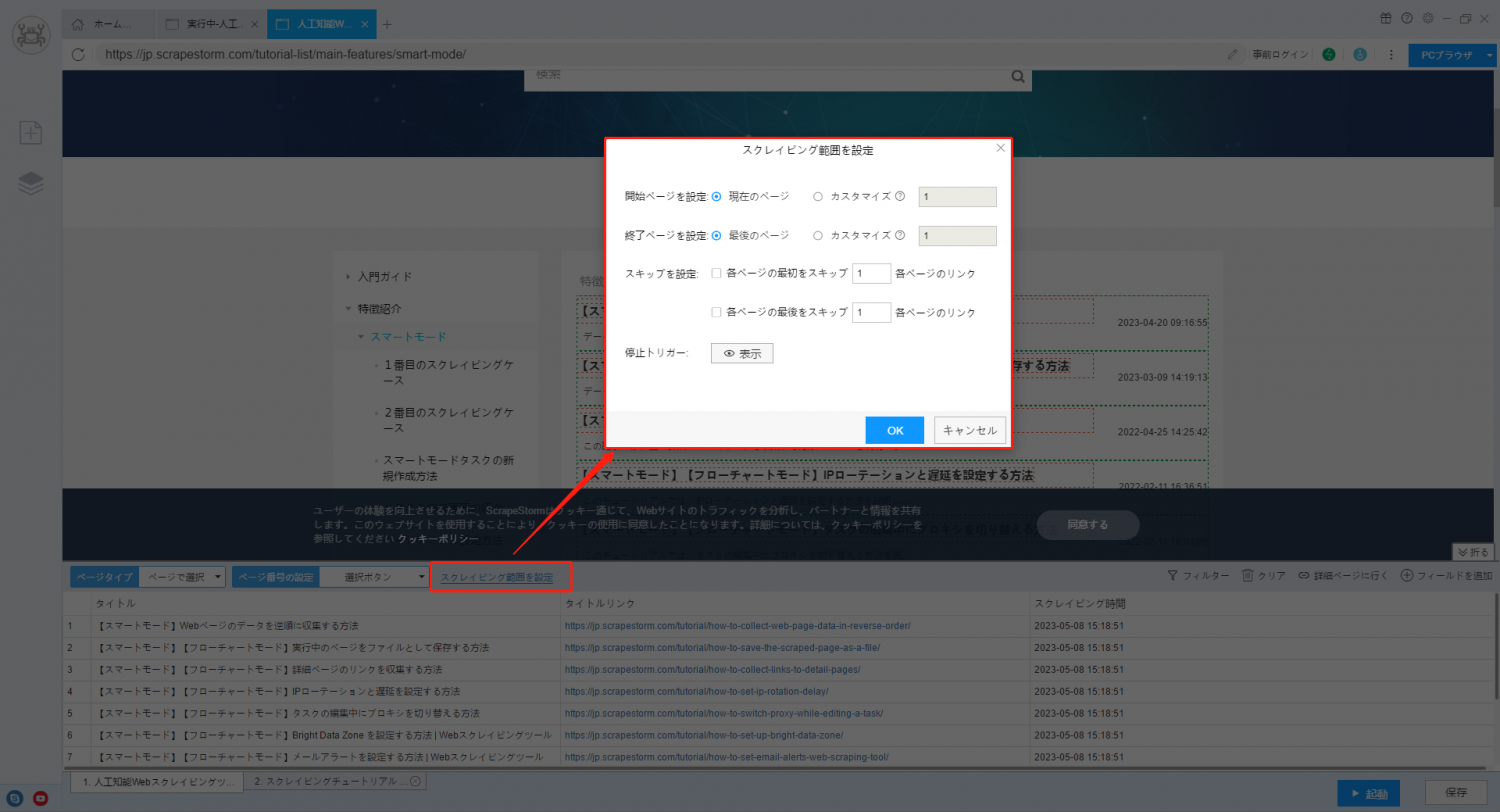
②重複データは中間ページのデータであり、この場合は直接結論を出すことはできません。
上記の2つのケースでは、収集タスクを提供してください。テストと分析をお手伝いします。
ScrapeStorm日本チームの連絡先は下記のようにご覧ください。
メール:support.jp@scrapestorm.com
Skype ID: ScrapeStorm.jp
https://join.skype.com/invite/jDLhZt1EC3Dz
Line ID:scrapestorm-jp
https://line.me/ti/p/U3g4r6fI4a
お問い合わせ:https://jp.scrapestorm.com/?type=contact