【スマートモード】ページタイプの設定方法 | Webクローラ | ScrapeStorm
摘要:本文には、ページタイプの設定方法を紹介します。プライミング必要なし、使いやすいです。 ScrapeStorm無料ダウンロード
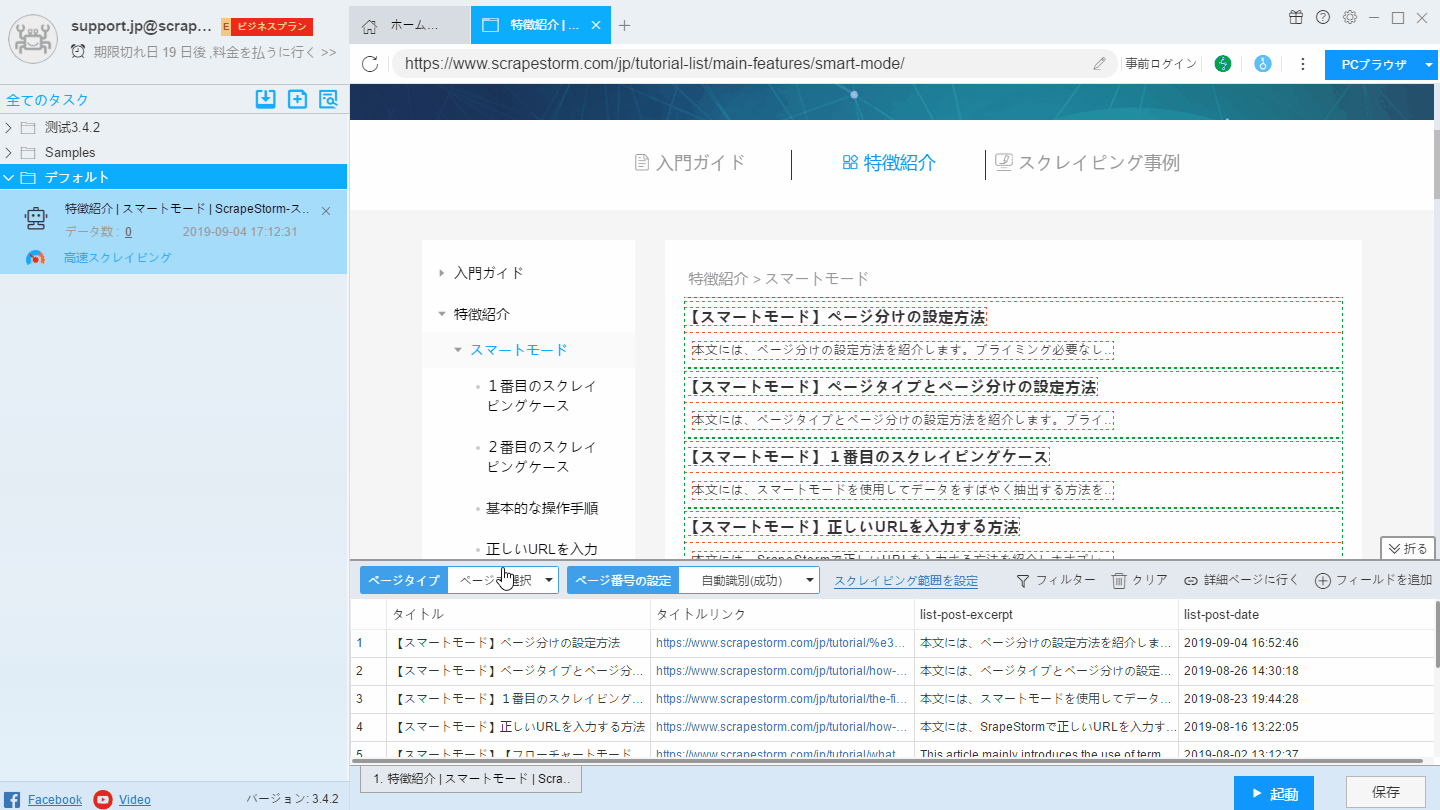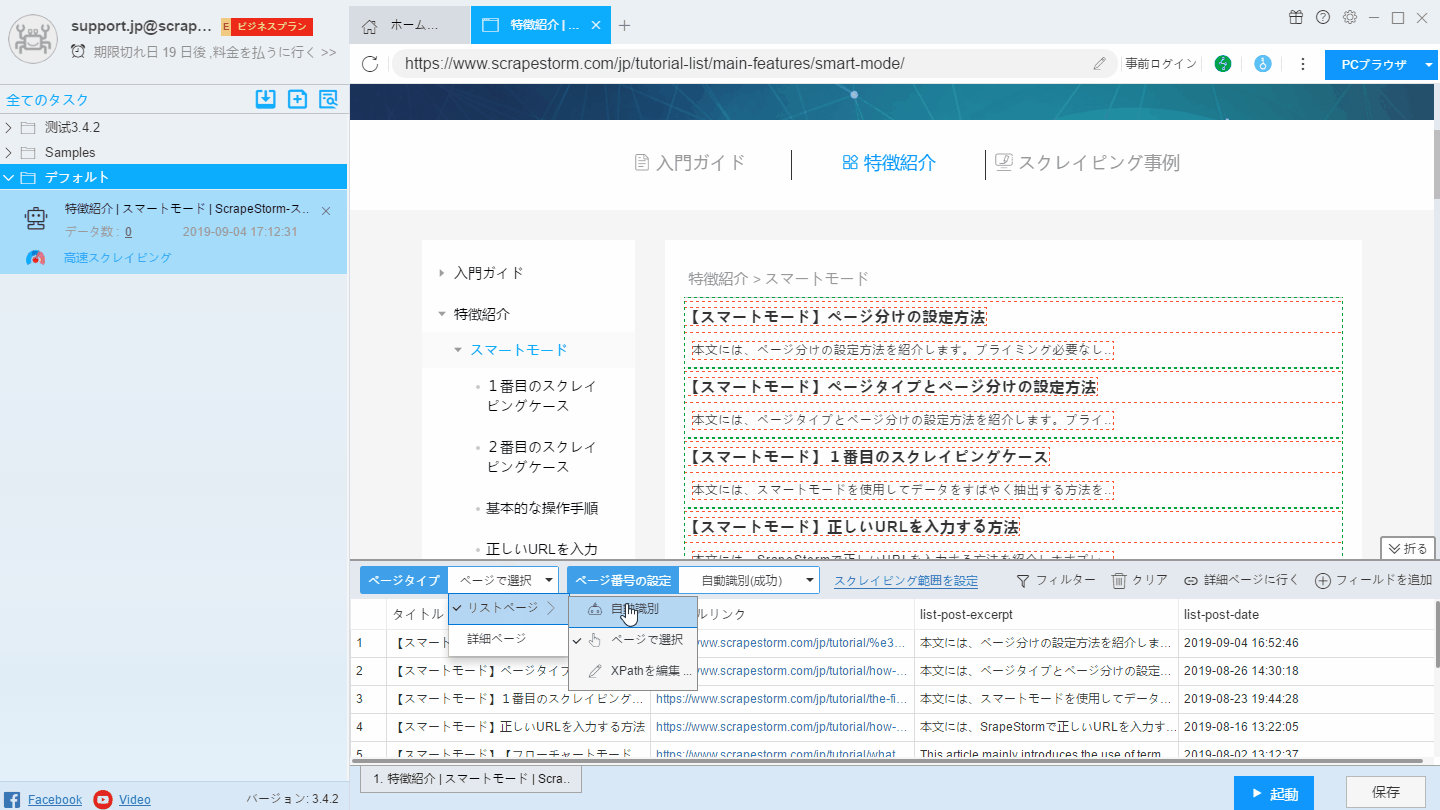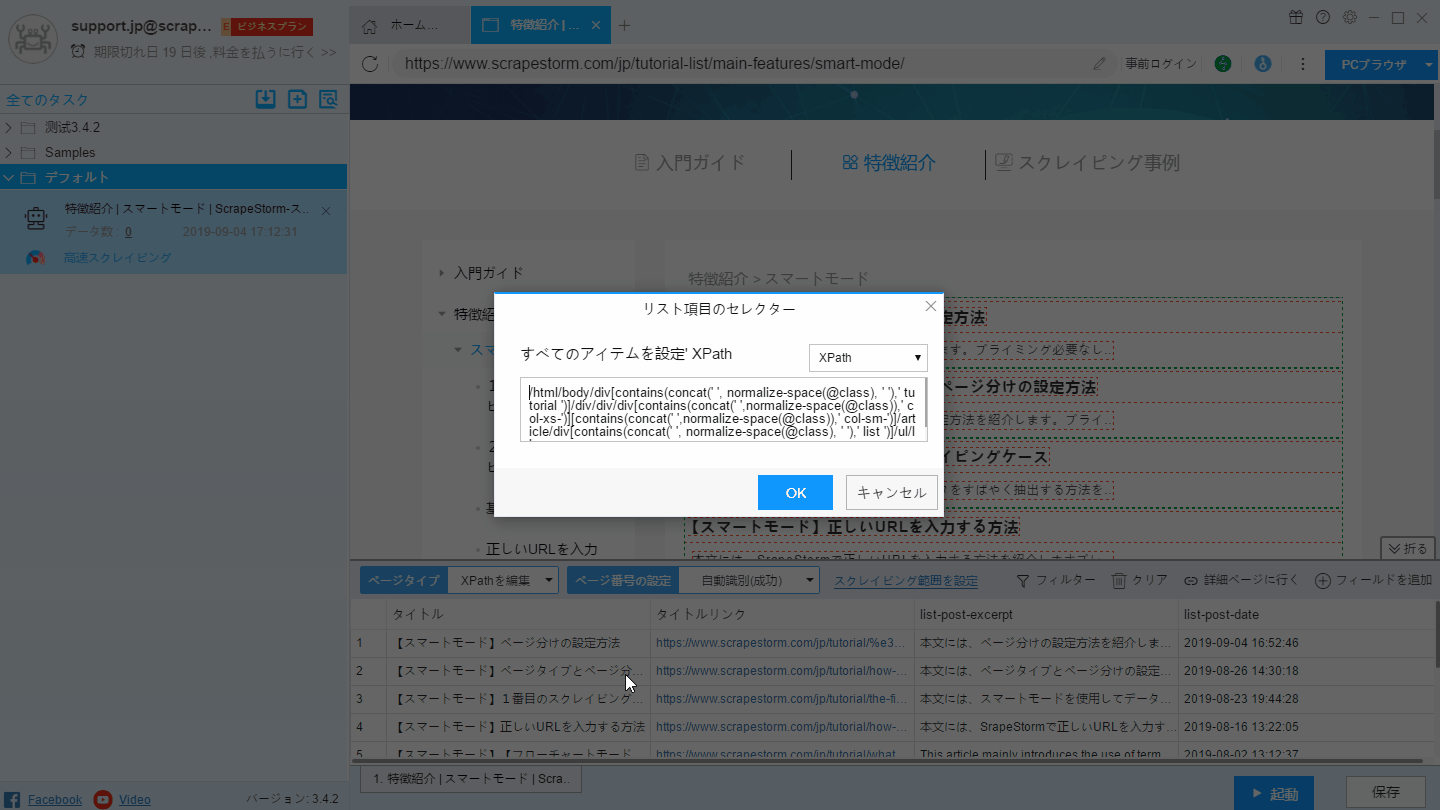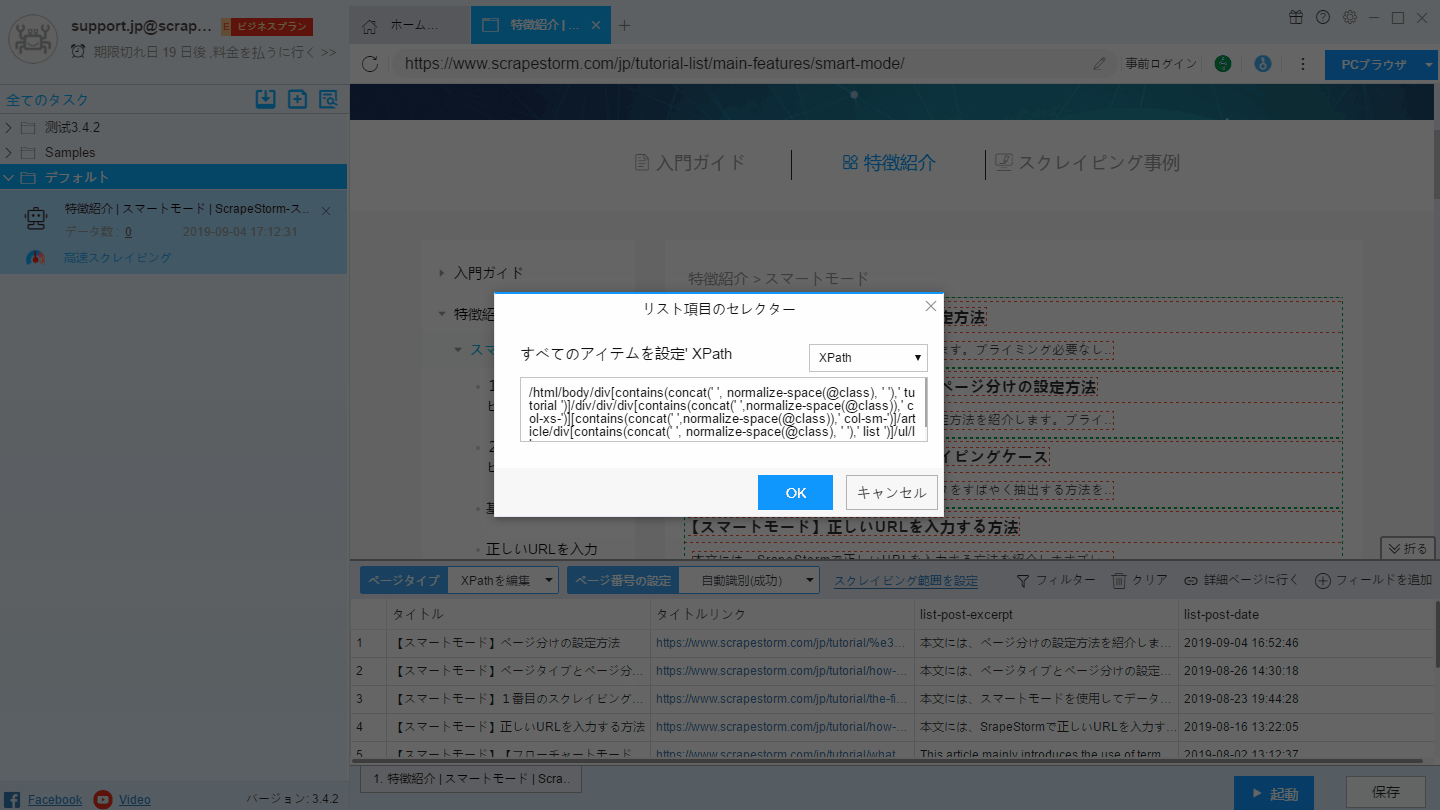
リストページはスマートモードのデフォルトタイプです。単一ページを入力すると、識別エラーが発生するかもしれません。 また、リストページであっても、インテリジェント識別にランダム誤差の可能性もあります(テリジェント識別機能は常に最適化されています)。この時点でページタイプを手動で選択し、ページネーションを設定して、ScrapeStormが正しい結果を識別できるようにすることができます。
リストページと詳細ページの詳しく説明は下記のチュートリアルにご参照ください。
具体的な設定方法は下記のようにご覧ください。
ページタイプの設定は次の図の通り: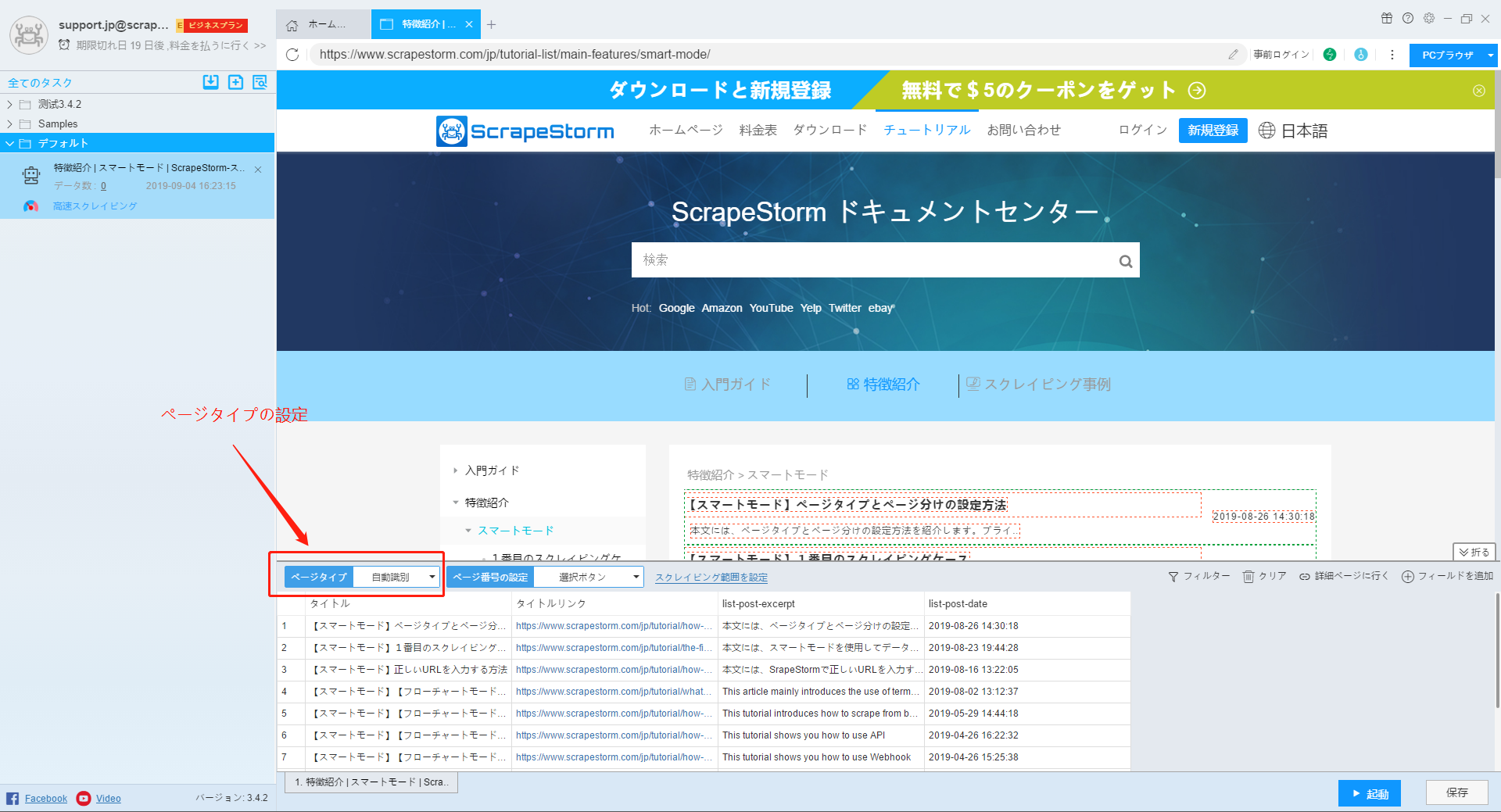
詳細ページには「詳細ページ」ボタンを選択してください。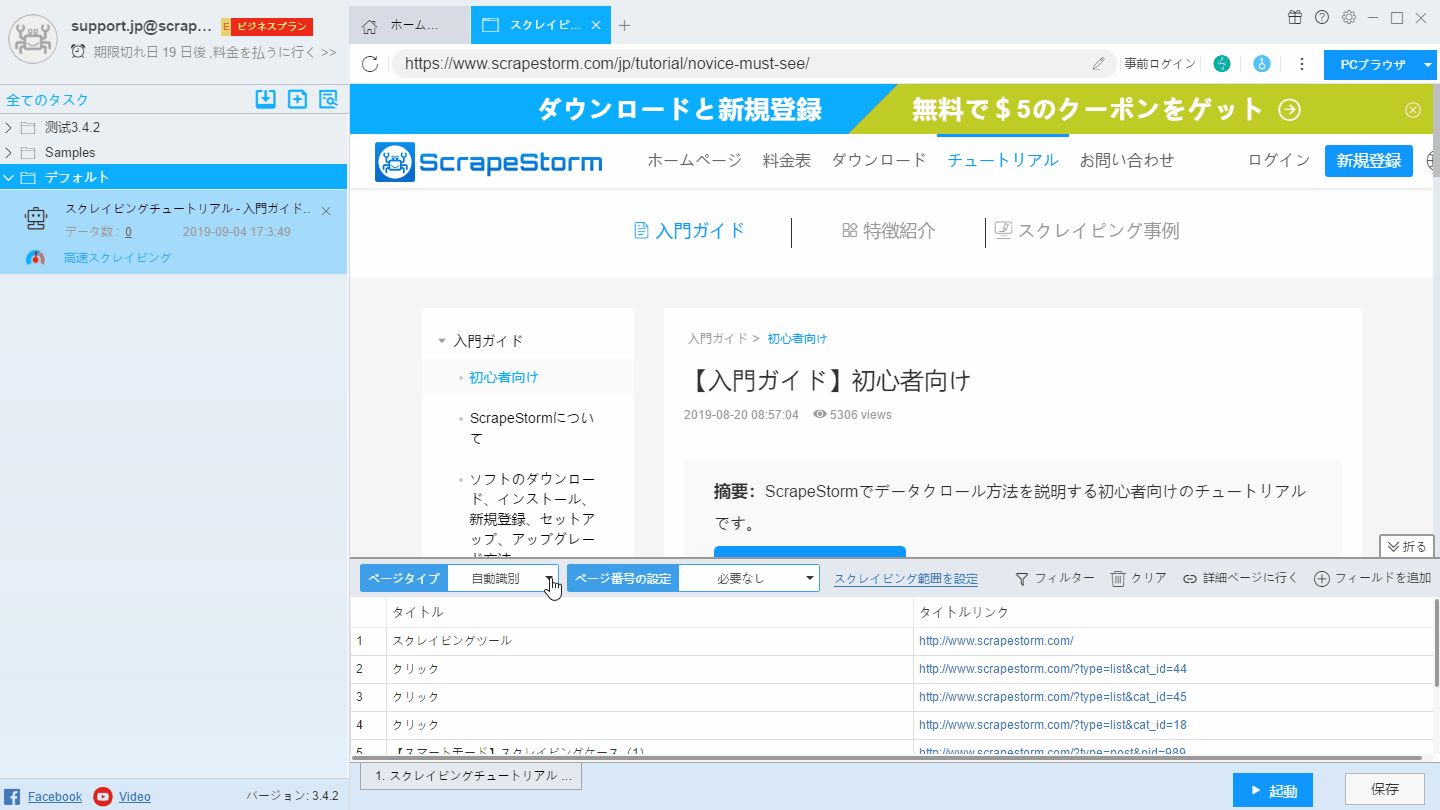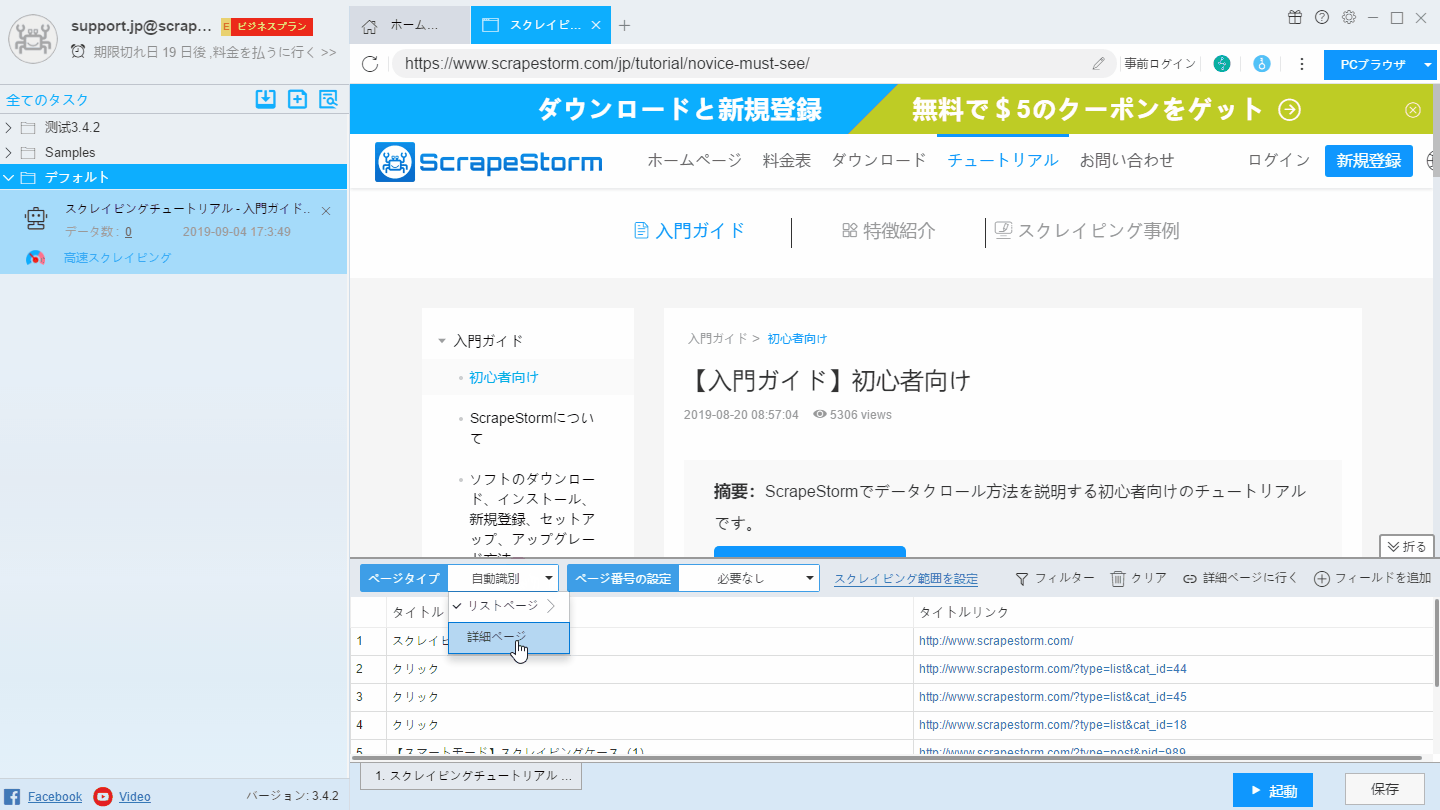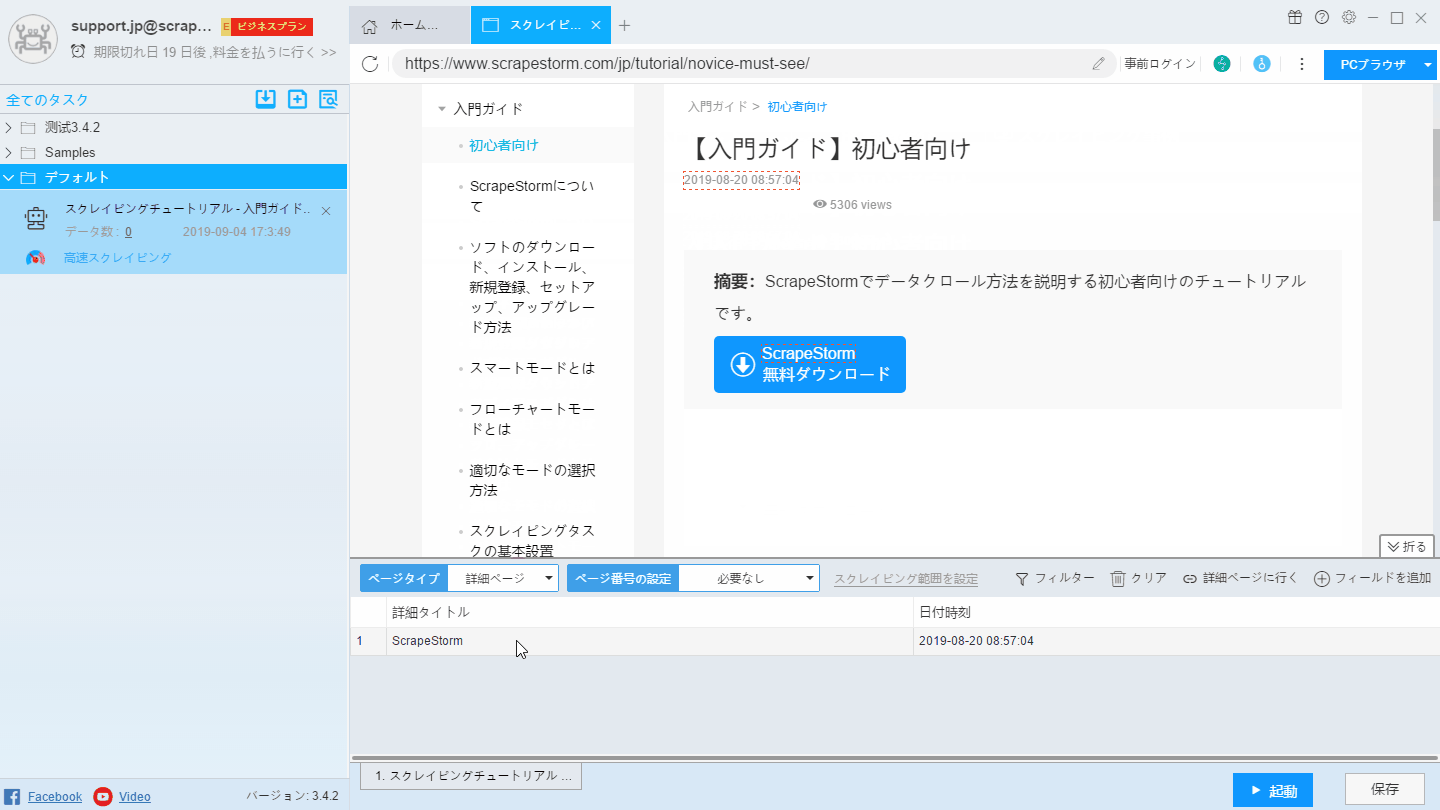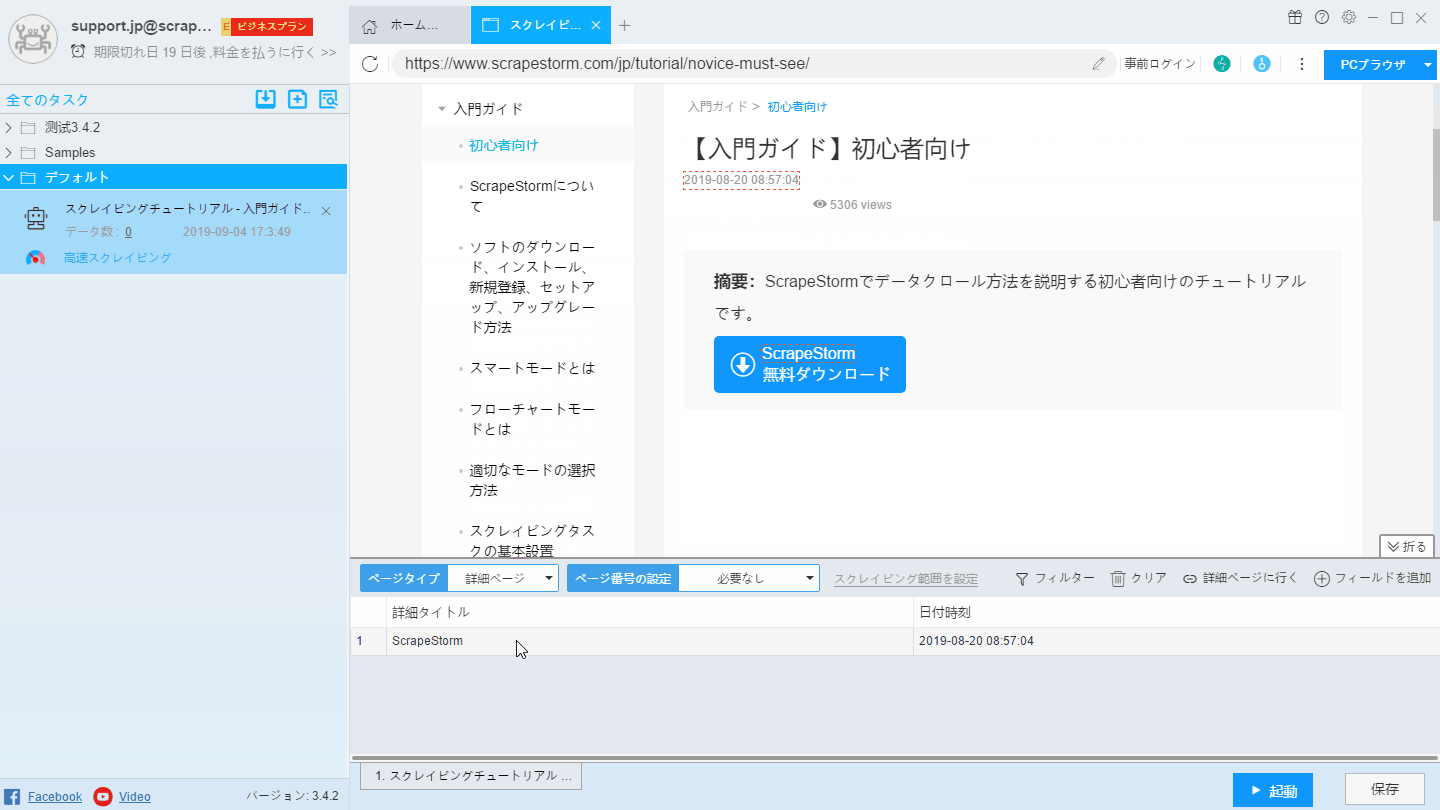
リストページには「自動識別」ボタンをクリックして、ScrapeStormには、再びリストの識別します。
リスト内の各要素は、ページ内で緑色のワイヤフレームで選択され、各フィールドは赤色のワイヤフレームで選択されます。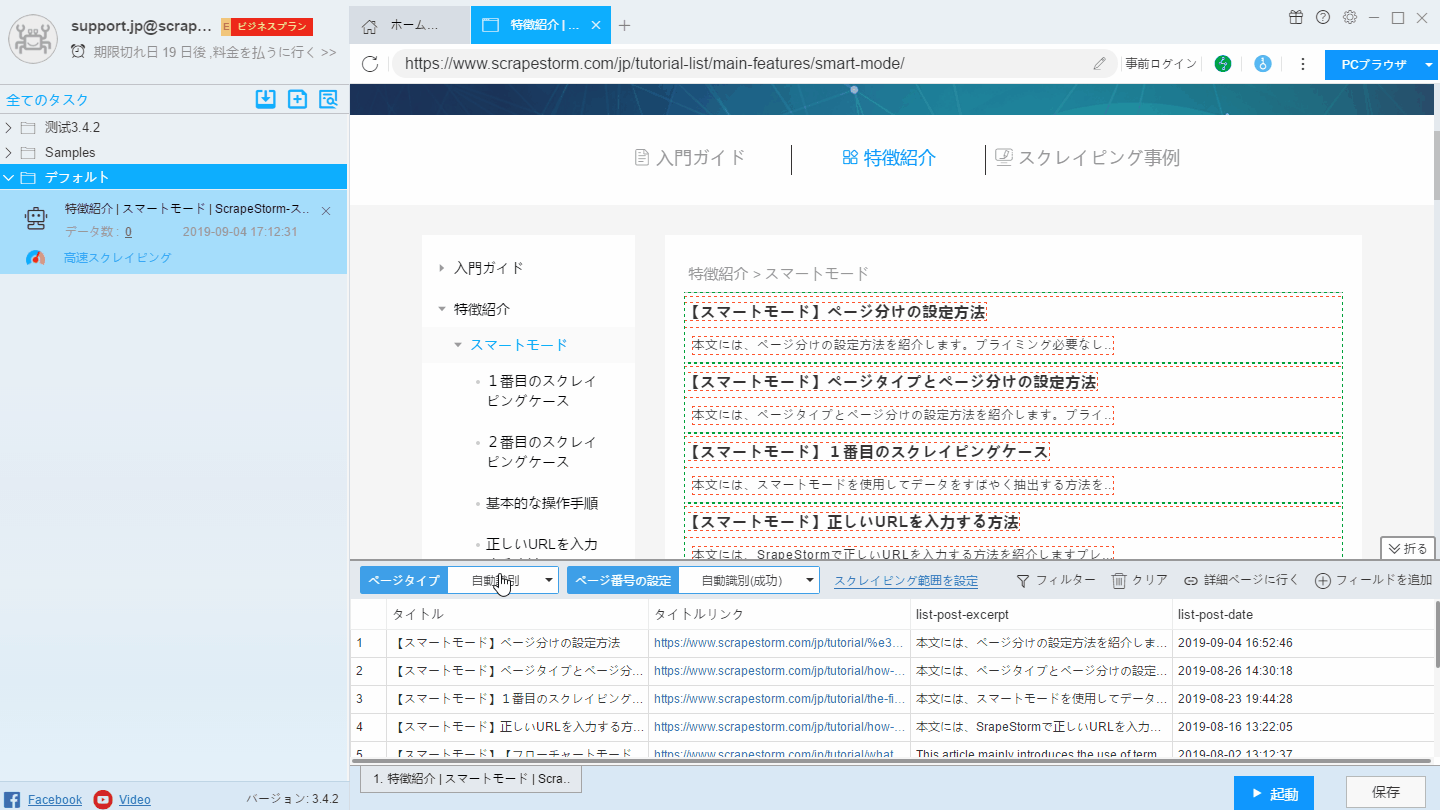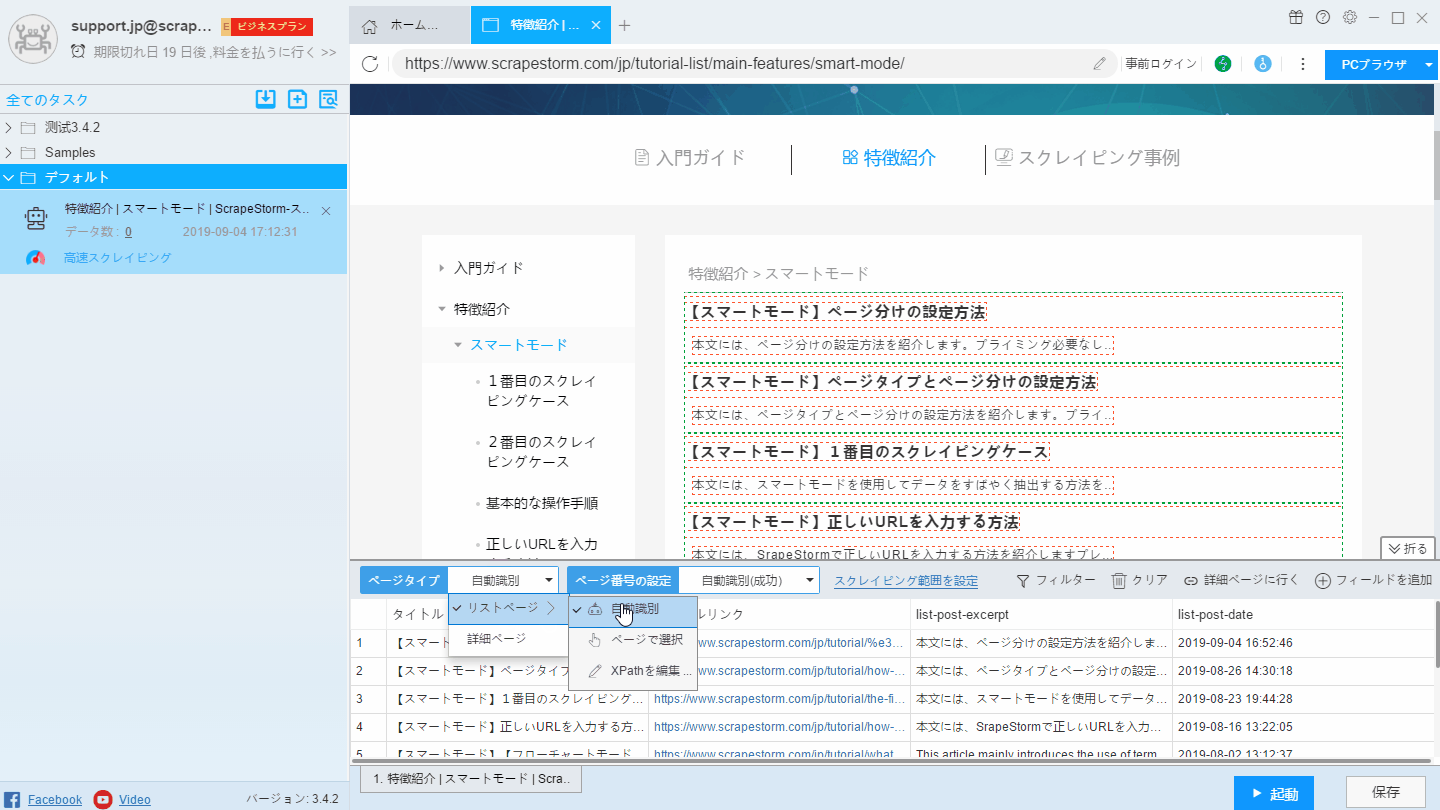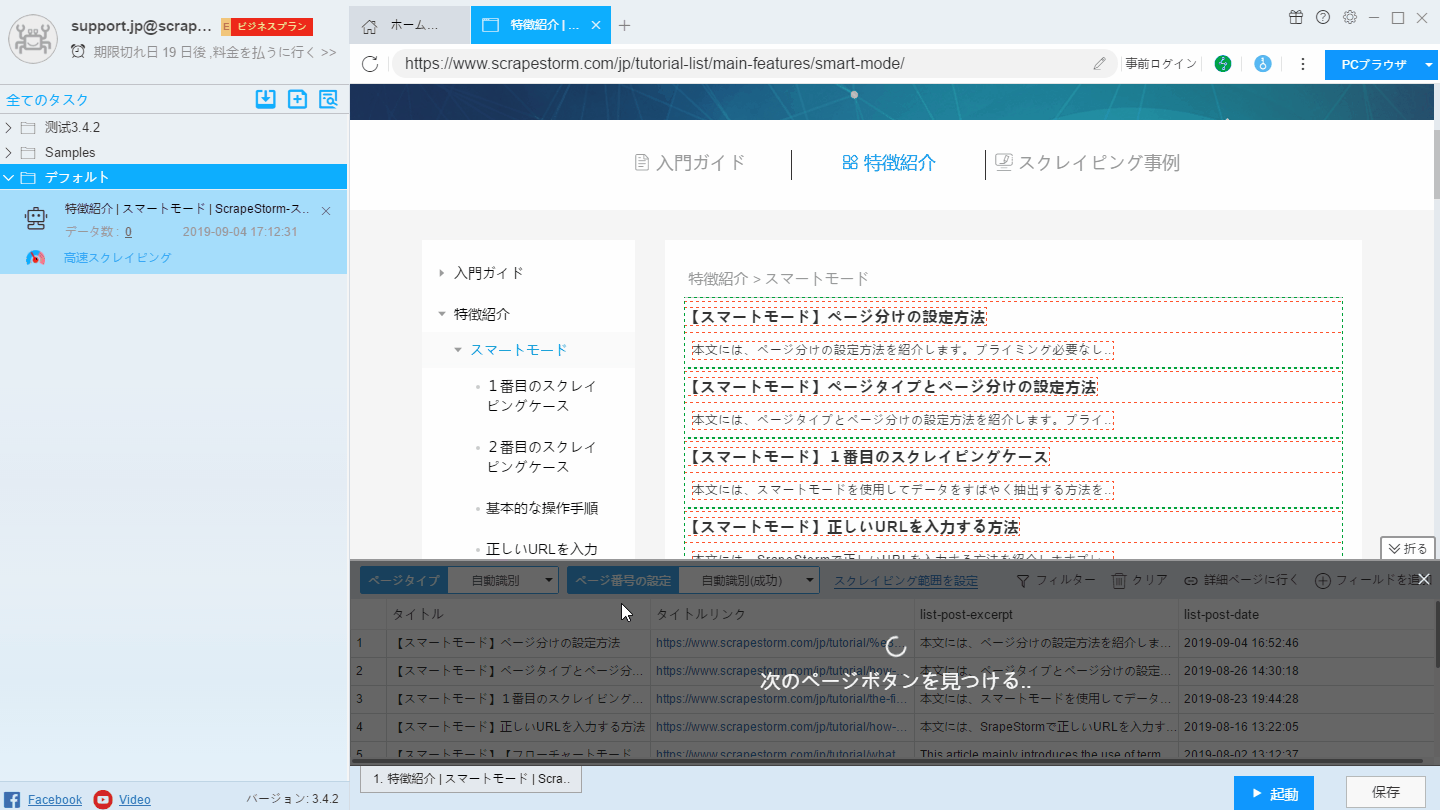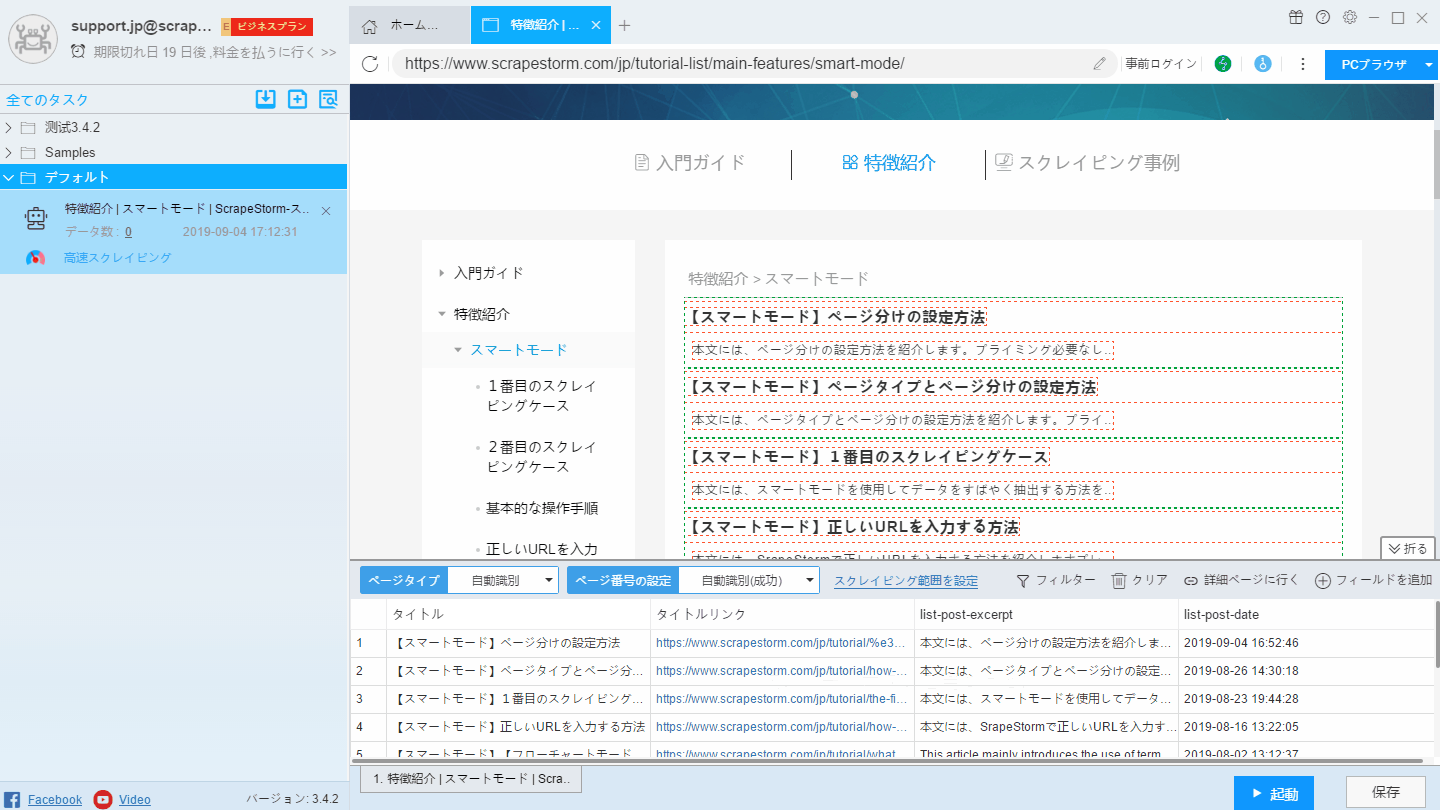
自動認識効果が要件を満たしていない場合は、「リストを手動で選択する」および「リストXpathを編集する」ことで認識結果を変更できます。手動で選択する方法は下記のようにご覧ください。
(1)「ページで選択」をクリックします。
(2)リストの第一行目の一番目の要素をクリックします。
(3)リストの第二行目の一番目の要素をクリックします。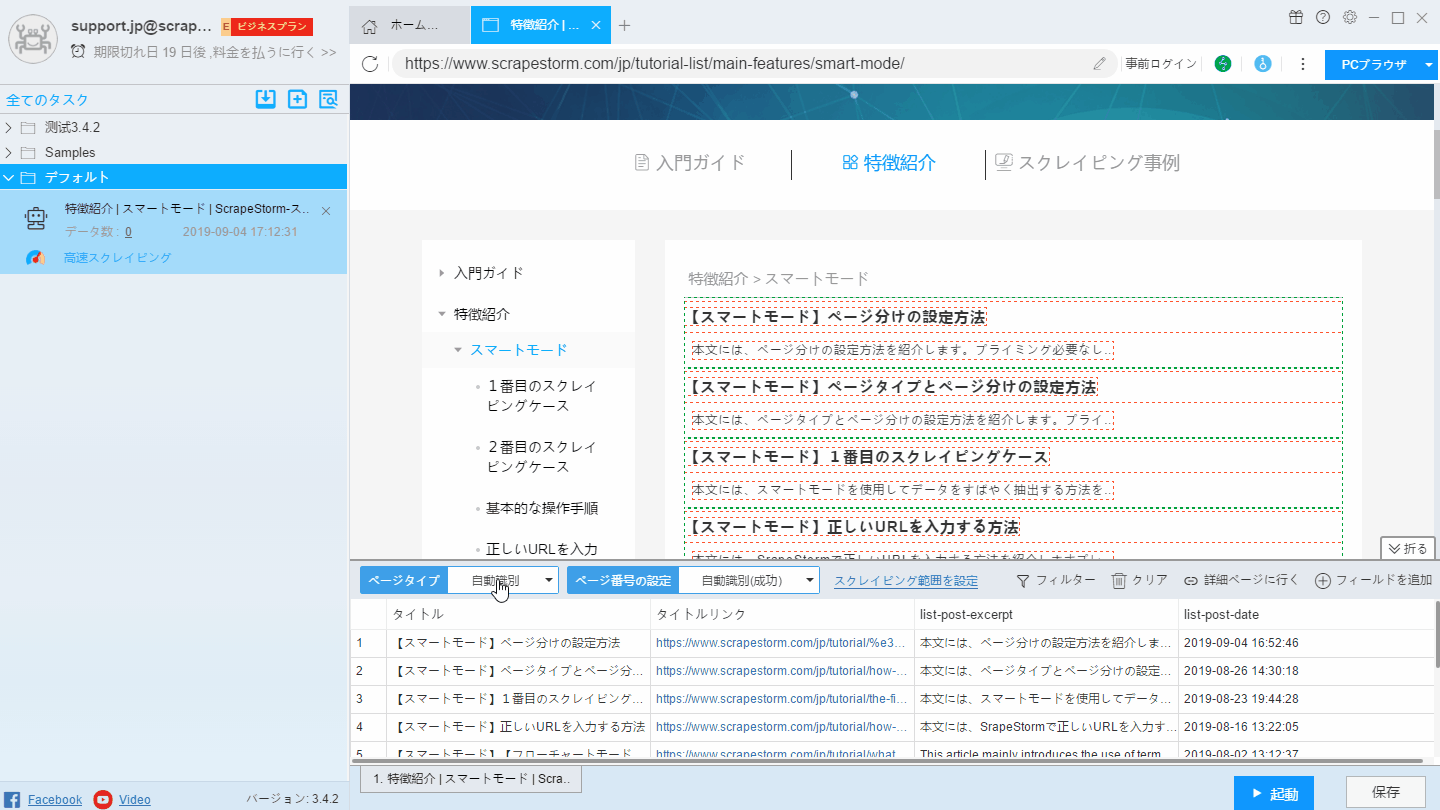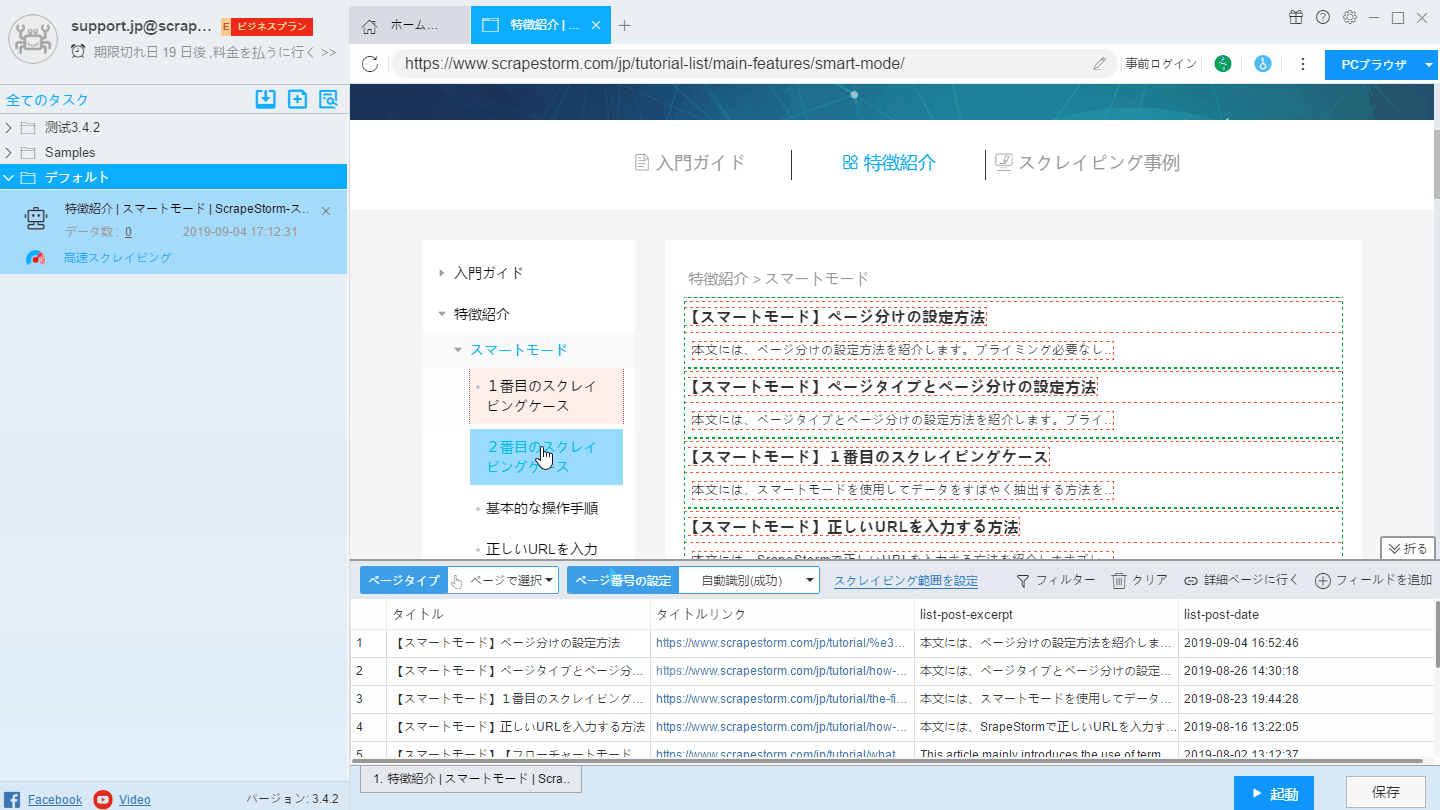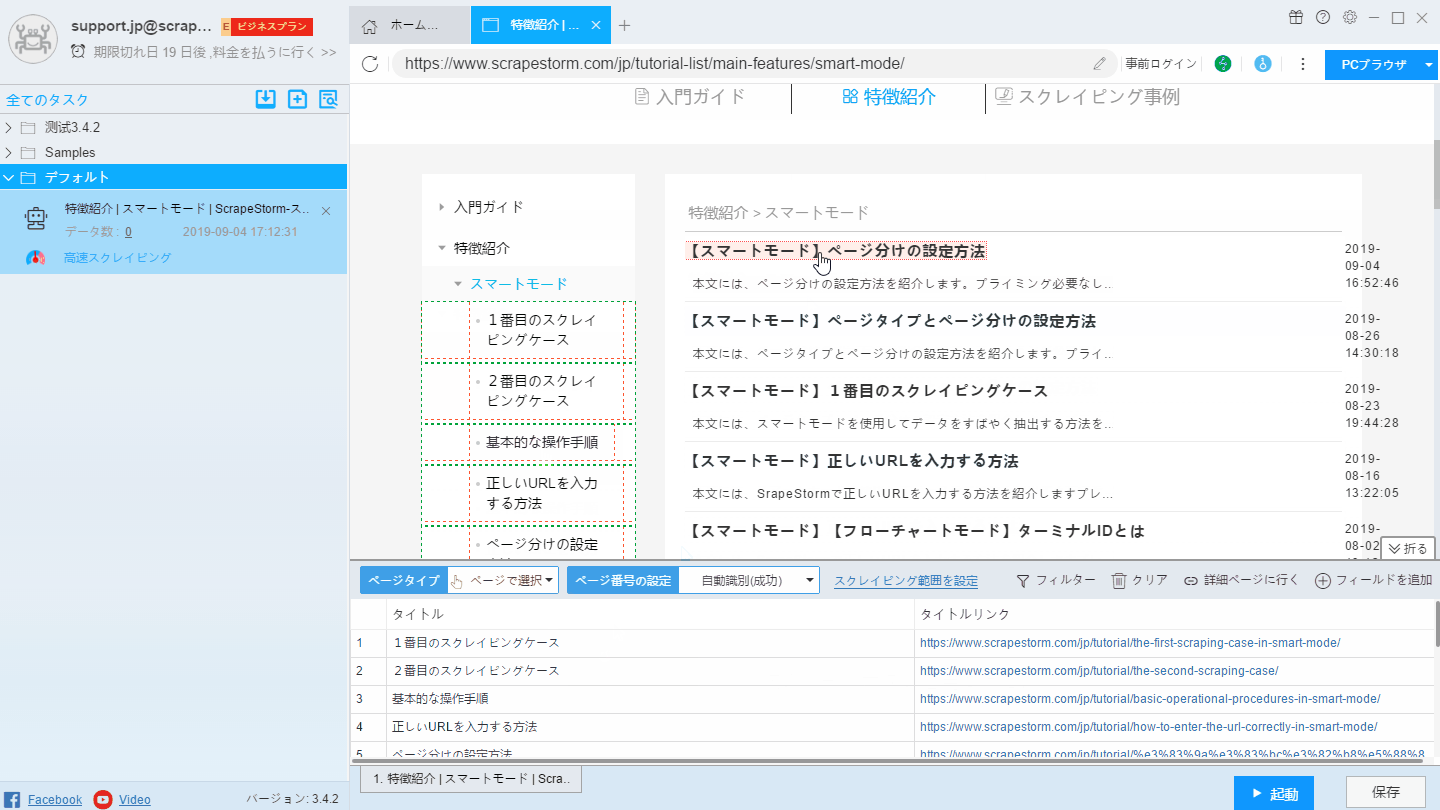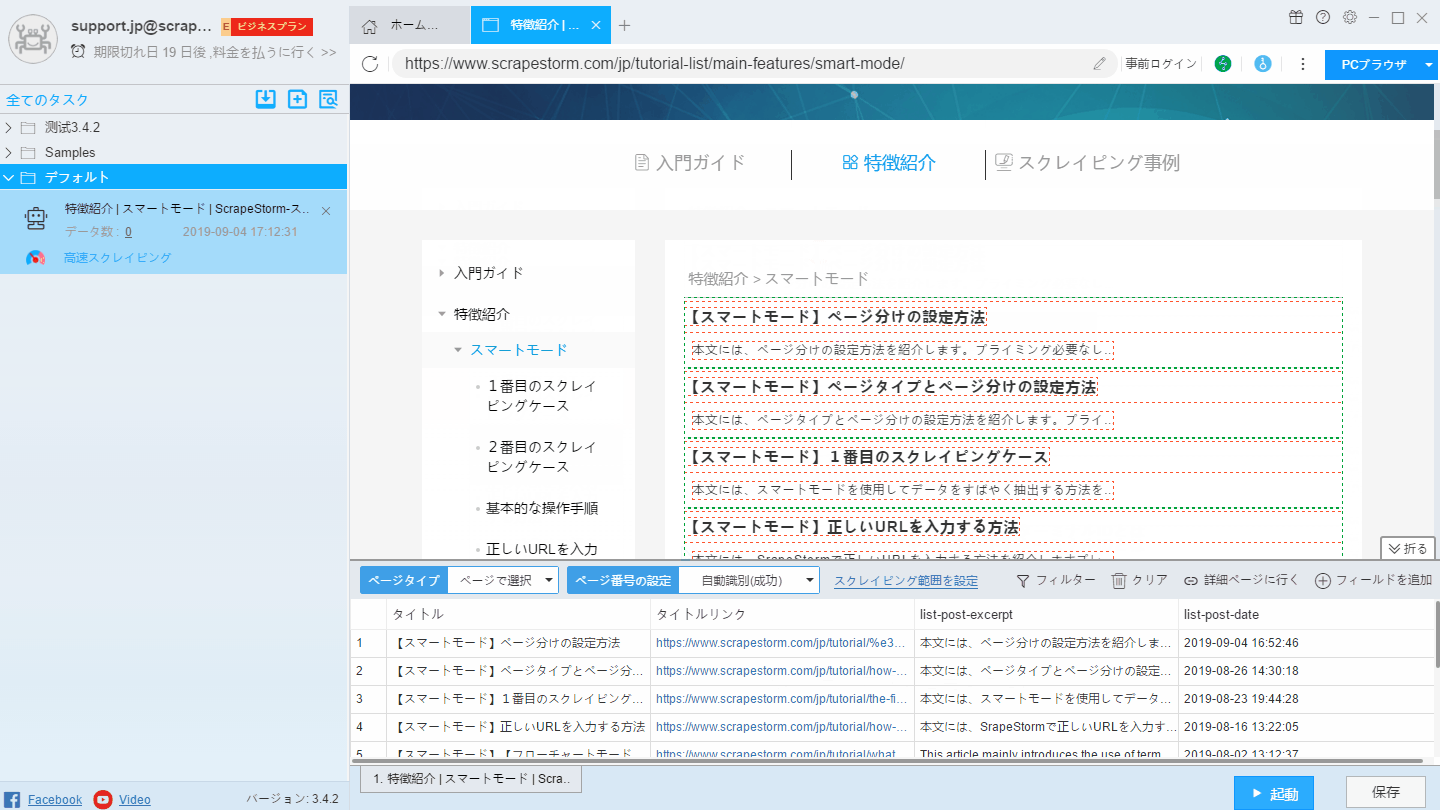
PS.上記には二つの変更があり、一回目は認識結果が左側のリストに変更され、2回目に認識結果が右側のリストに変更されました。
Xpathの編集は次の図の通り: