データ匿名化(Data Anonymization) | Webクローラ | ScrapeStorm
摘要:データ匿名化とは、個人情報や機密情報を識別不可能な形に変換し、特定の個人やエンティティを特定できなくするプロセスです。これにより、プライバシーを保護しながらデータを分析や共有、研究に利用することが可能となります。匿名化されたデータは、特定の個人と結びつけることができなくなり、プライバシー侵害のリスクを軽減します。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データ匿名化とは、個人情報や機密情報を識別不可能な形に変換し、特定の個人やエンティティを特定できなくするプロセスです。これにより、プライバシーを保護しながらデータを分析や共有、研究に利用することが可能となります。匿名化されたデータは、特定の個人と結びつけることができなくなり、プライバシー侵害のリスクを軽減します。

適用シーン
患者の個人情報を匿名化することで、プライバシーを守りながら医療データを研究や分析に活用できる。顧客データや取引データを匿名化することで、社外の分析パートナーや第三者にデータを提供しつつ、顧客のプライバシーを保護する。GDPRやCCPAなどのデータ保護規制に対応するために、企業はデータを匿名化して個人情報の漏洩リスクを低減する。研究機関や公共機関がデータを公開する際、匿名化することで、プライバシー侵害のリスクを軽減しつつ、データを広く共有できる。
メリット:個人を特定できないようにすることで、プライバシーの侵害リスクを大幅に軽減できる。匿名化により、規制やプライバシーに関する懸念をクリアし、データを研究、分析、共有に安全に利用できる。各国や地域のプライバシー法規制を遵守しやすくなり、法的リスクを軽減できる。個人情報の漏洩があっても、匿名化されたデータであればリスクを最小限に抑えることができる。
デメリット:匿名化により、データの詳細や精度が失われ、分析や研究の結果に影響を及ぼす可能性がある。十分な匿名化が行われていない場合、他のデータセットと組み合わせることで、再び個人を特定できるリスクがある。効果的な匿名化には高度な技術とプロセスが必要であり、これがコストと実行の複雑さを増大させる。匿名化データが適切に管理されなかったり、再識別されるリスクが発覚した場合、法的・倫理的な問題が生じる可能性がある。
図例
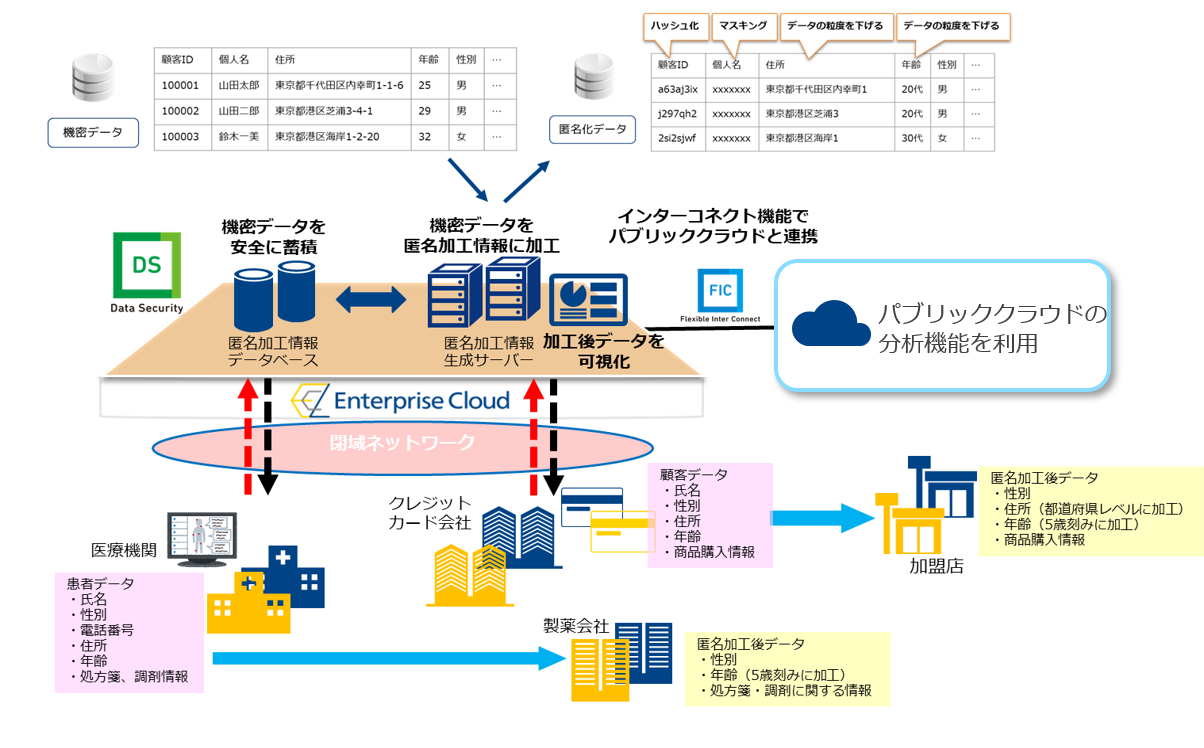
1. データ匿名化。
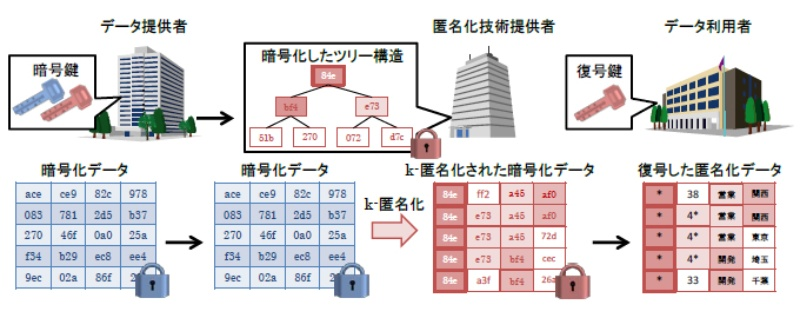
2. 個人データを暗号化したまま匿名化する暗号技術を開発。
関連記事
参考リンク
https://www.auriq.co.jp/blog/gdpr-anonymization/