データサンプリング(DataSampling) | Webクローラ | ScrapeStorm
摘要:データサンプリングとは、大規模なデータセットから一部のデータを選び出して、全体を推測・分析する手法です。目的は、データの全体を解析するのに必要な計算リソースを削減し、効率的に分析を行うことです。サンプリングされたデータは、元のデータセットを代表するものである必要があり、適切にサンプリングすることで、全体の傾向や特徴を正確に把握することができます。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データサンプリングとは、大規模なデータセットから一部のデータを選び出して、全体を推測・分析する手法です。目的は、データの全体を解析するのに必要な計算リソースを削減し、効率的に分析を行うことです。サンプリングされたデータは、元のデータセットを代表するものである必要があり、適切にサンプリングすることで、全体の傾向や特徴を正確に把握することができます。
適用シーン
大量のデータを扱う場合、すべてのデータを使って分析を行うと、計算時間やリソースが膨大になることがあります。例えば、ビッグデータの解析や機械学習モデルのトレーニングなどで、データサンプリングがよく用いられます。データの全体像をつかむために、まず一部のデータをサンプリングして簡易的な分析を行うことがあります。この段階で重要な特徴や傾向を把握し、その後の詳細な解析に活用します。製品の品質検査などで、全数検査が不可能な場合にサンプリングを行い、そのサンプルから全体の品質を推定することがあります。
メリット:サンプリングにより、計算時間やメモリの使用量を大幅に削減できます。これにより、より迅速な分析が可能になります。データ全体を解析する前に、サンプリングによってデータの主要な傾向や特徴を掴むことができます。サンプリングによって、分析において不要な冗長なデータを除外し、より重要なデータに焦点を当てることができます。
デメリット:サンプリングが不適切だと、データ全体を正確に反映しない結果が得られる可能性があります。特に、サンプルが偏っている場合には、誤った結論に至るリスクがあります。サンプリングによって、データセット全体に比べてサンプルサイズが小さくなるため、分析結果の精度が低下する可能性があります。特に、稀な事象や異常値の検出には、サンプルサイズが不十分だと対応できないことがあります。適切なサンプリング手法が用いられていない場合、サンプルが母集団を正しく代表していない可能性があります。これにより、分析結果が誤って解釈される可能性があります。
図例
1. サンプリングのしくみ。
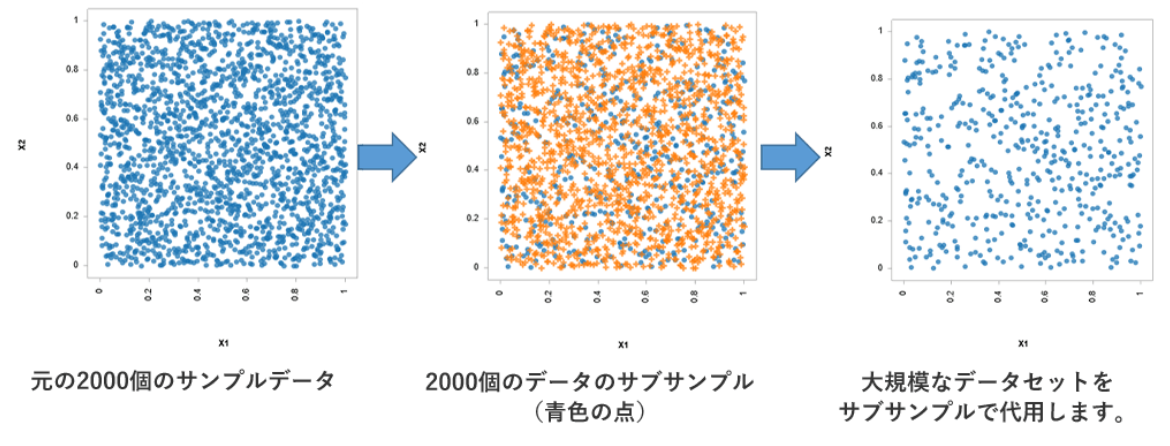
2. スライスサンプリングのプロセス。
関連記事
参考リンク
https://kesco.co.jp/smartuq/data-sampling/
https://www.ibm.com/docs/ja/cognos-analytics/12.0.0?topic=metadata-data-sampling