【スマートモード】Webページのデータを逆順に収集する方法 | Webクローラ | ScrapeStorm
摘要:データ収集中、逆の順序で収集する必要があることがよくあります (最後のページから前へデータを収集します)。 本文では、ScrapeStormのスマートモードを使用して、Webページのデータを逆順に収集する方法を簡単に説明します。 ScrapeStorm無料ダウンロード
データ収集中、逆の順序で収集する必要があることがよくあります (最後のページから前へデータを収集します)。 本文では、ScrapeStormのスマートモードを使用して、Webページのデータを逆順に収集する方法を簡単に説明します。
状況一:ページをめくるとリンクが変わり、最終ページのリンクがある
処理方法一:リストページの最終ページのリンクを抽出リンクにする
最終ページのリンクを直接取得できる場合は、最終ページのリンクを直接コピーしてタスクを作成できます。
1. ブラウザの最後のページをクリックし、最終ページのリンクをコピーします。

2. スマートモードタスクを新規作成する。
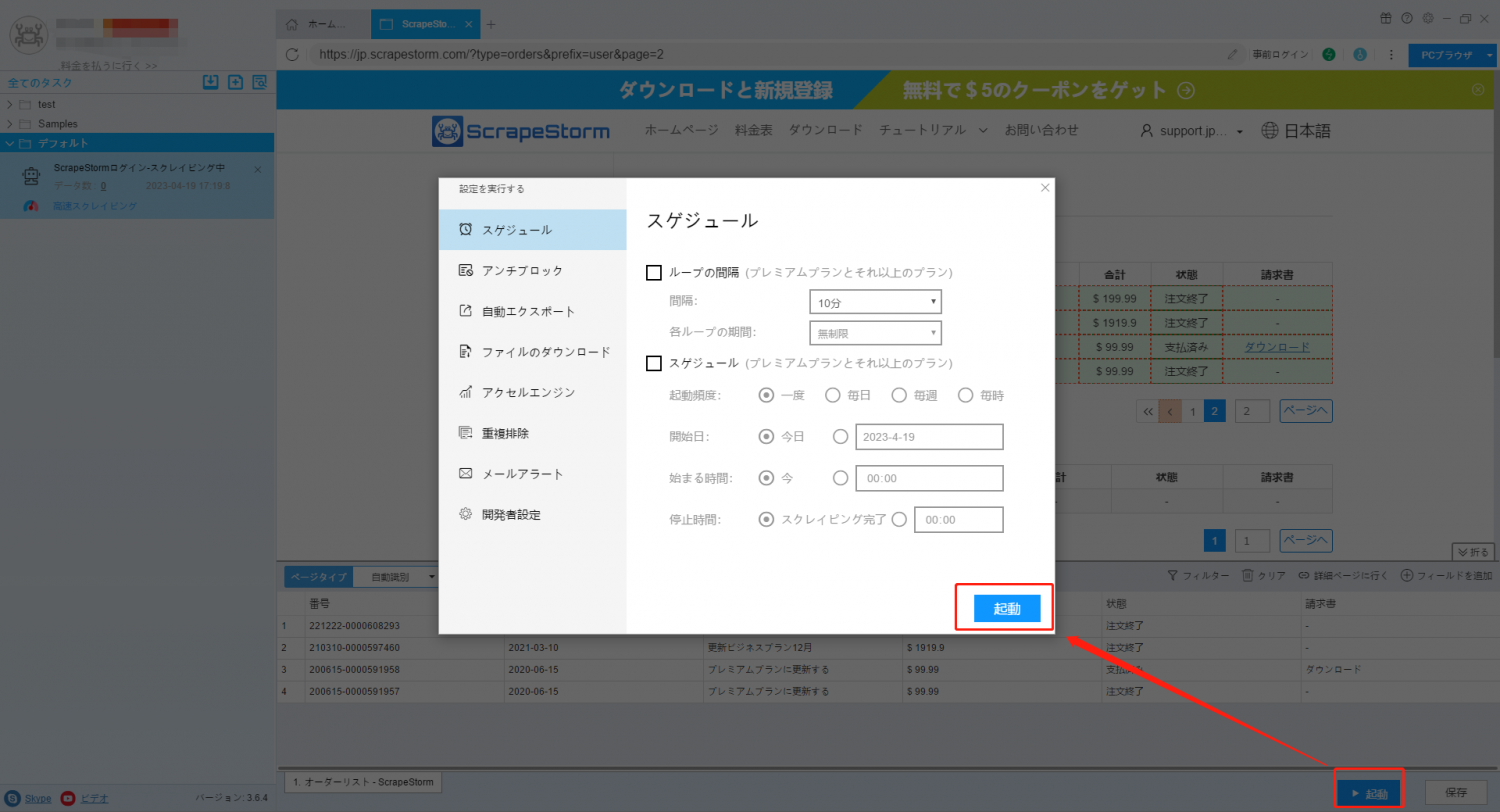
3. ページネーションボタンを設定し、「前のページ」ボタンを手動でクリックして認識し、ページをめくります。
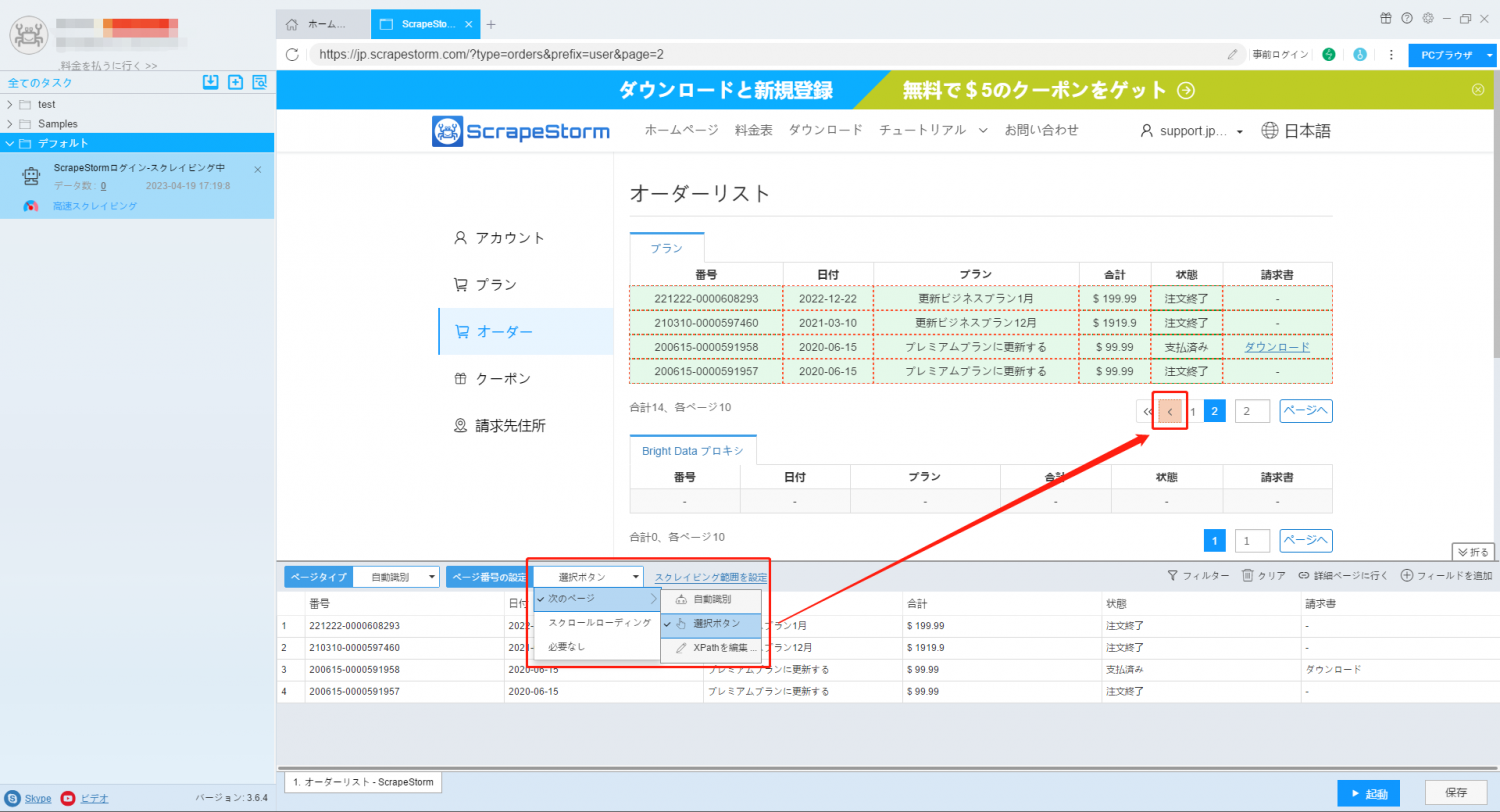
4. タスクを起動して、逆順で収集します。
処理方法二:ページ番号を逆順に設定する
ページめくりに合わせてウェブサイトのリンクが変化するが、ページめくりの操作を実現する「前のページ」ボタンがない場合、ページ番号を設定することで逆順収集を実現できます。
1. 2ページ目のリンクをコピーします。一般的に1ページ目のリンクは2ページ目、3ページ目のリンクとは異なる可能性があり、1ページ目のリンクを直接使って規則を探してリンクを生成することはできないかもしれませんから、2ページ目のリンクを直接コピーしてタスクを作成することをお勧めします。
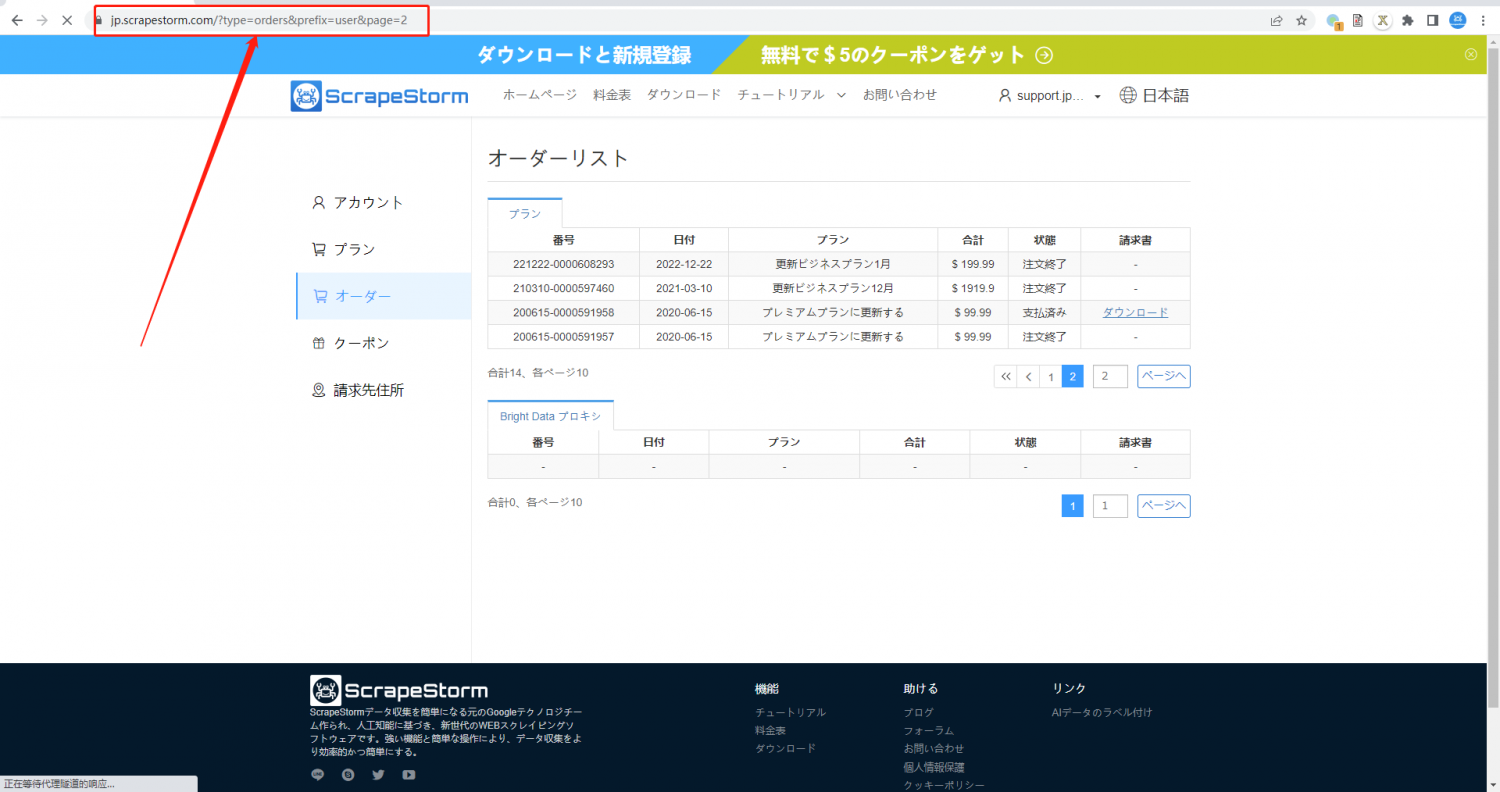
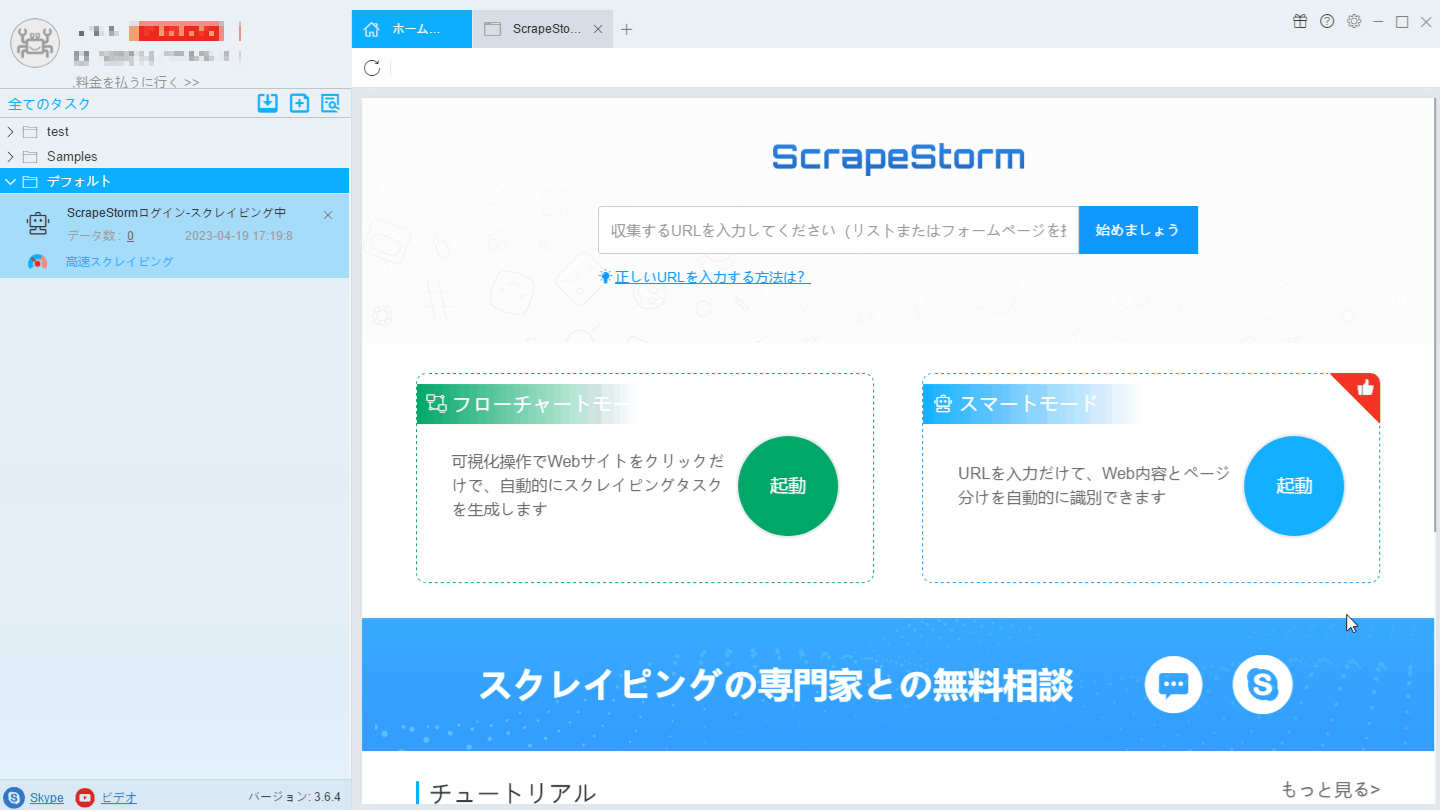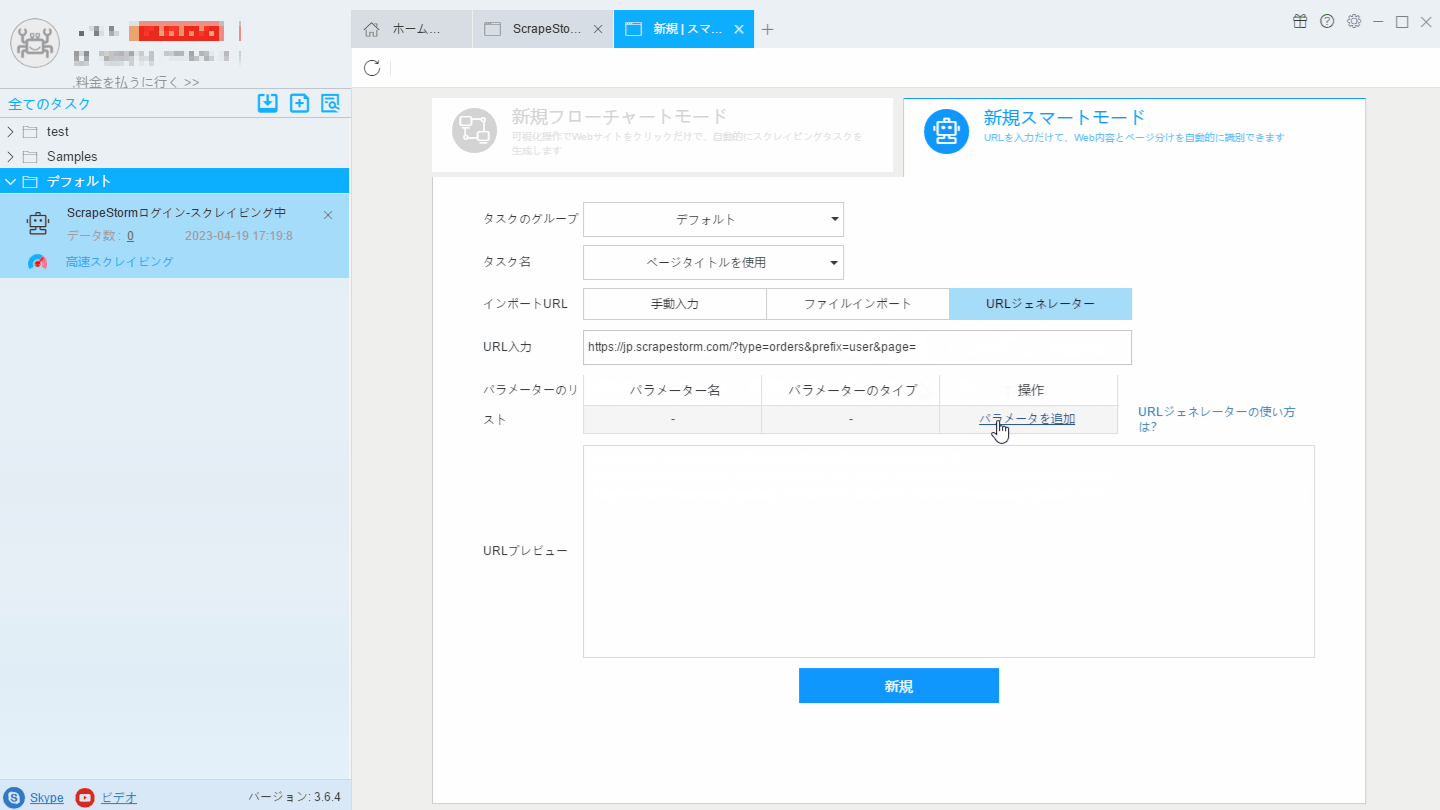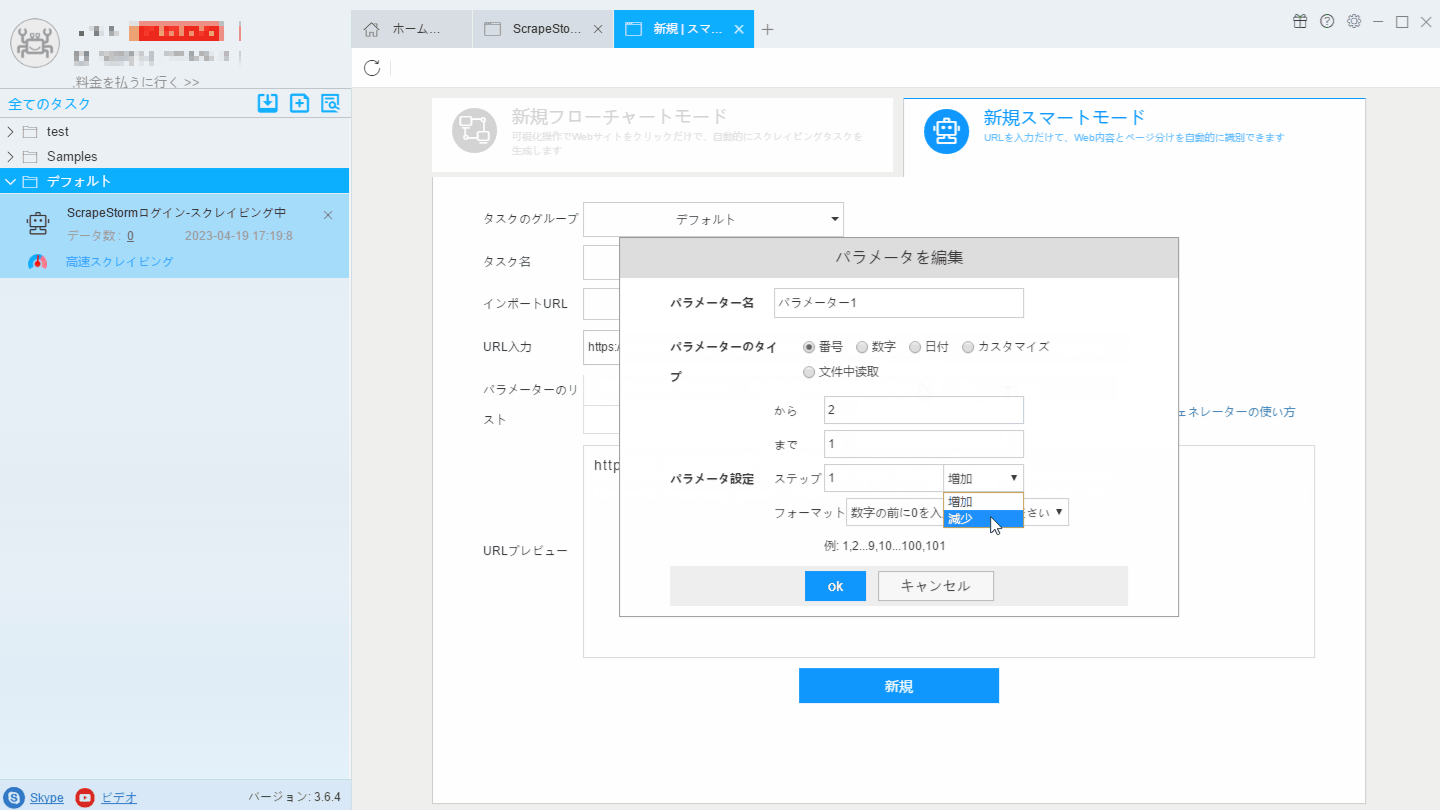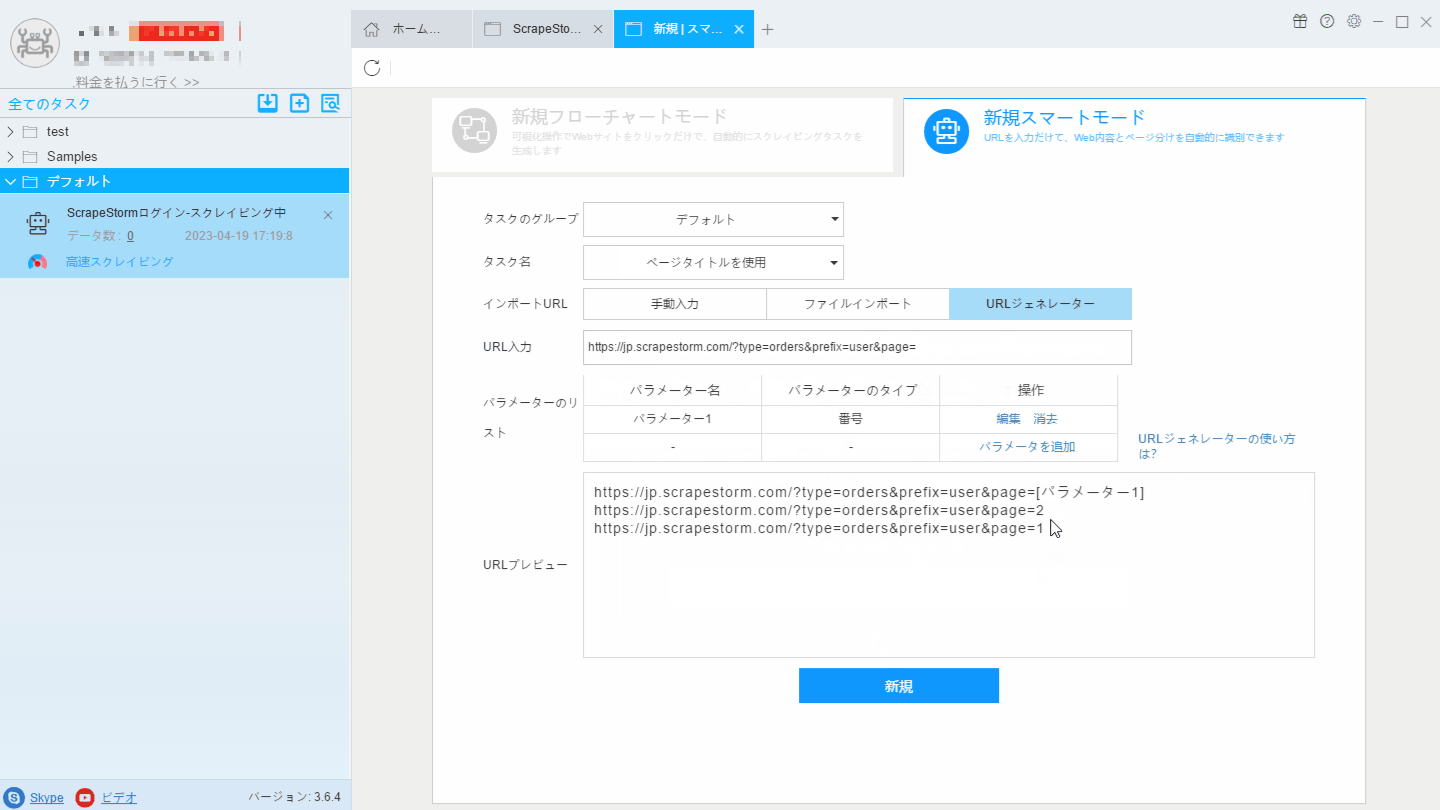
2. URLジェネレータ機能を利用しリンクを生成します。下記画像のように、「最終ページの番号」から、「第一ページの番号」まで、「ステップ」は「減少」に設定します。
詳細はチュートリアル「URLジェネレータの使い方」をご参照ください。
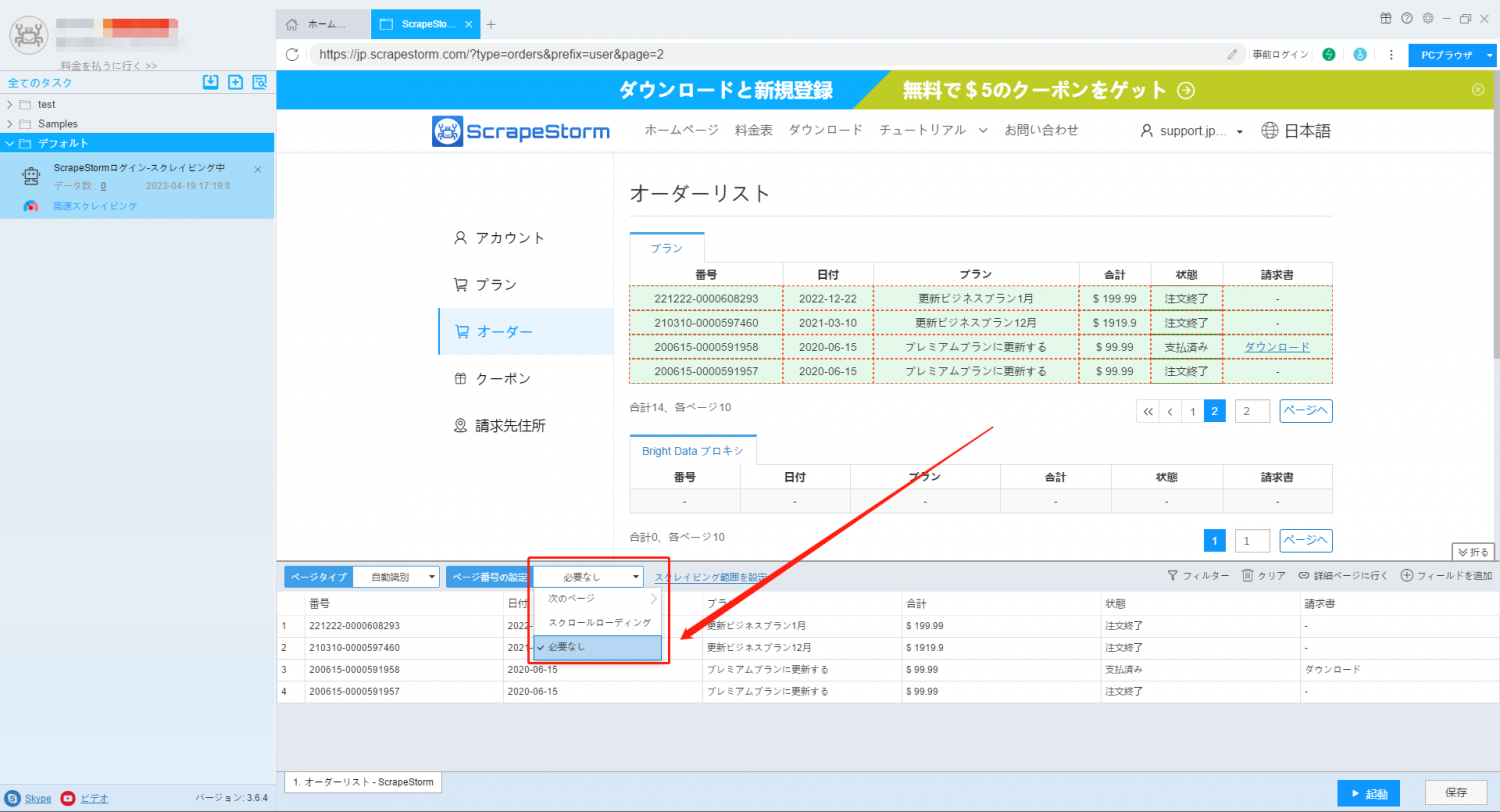
3. ページボタンを設定します。 URLが一括生成されている場合、ページボタンを設定する必要はありません。 ページボタンを「必要なし」に設定できます。 ページの内容が多い、より多くのデータを表示するためにスクロールが必要な場合は、「スクロールローディング」に設定することをお勧めします。
4. タスクを起動して、逆順で収集します。
状況二:ページをめくってもリンクは変わらず、最終ページのリンクはない
処理方法一:Webページに最終ページというボタンがある
ページめくりによってWebサイトのリンクが変わらず、最終ページのリンクを直接取得できない場合、最後のページのページめくりボタンを直接クリックすることで、最終ページにジャンプでき、逆順で収集できます。
1. スマートモードタスクを新規作成する。
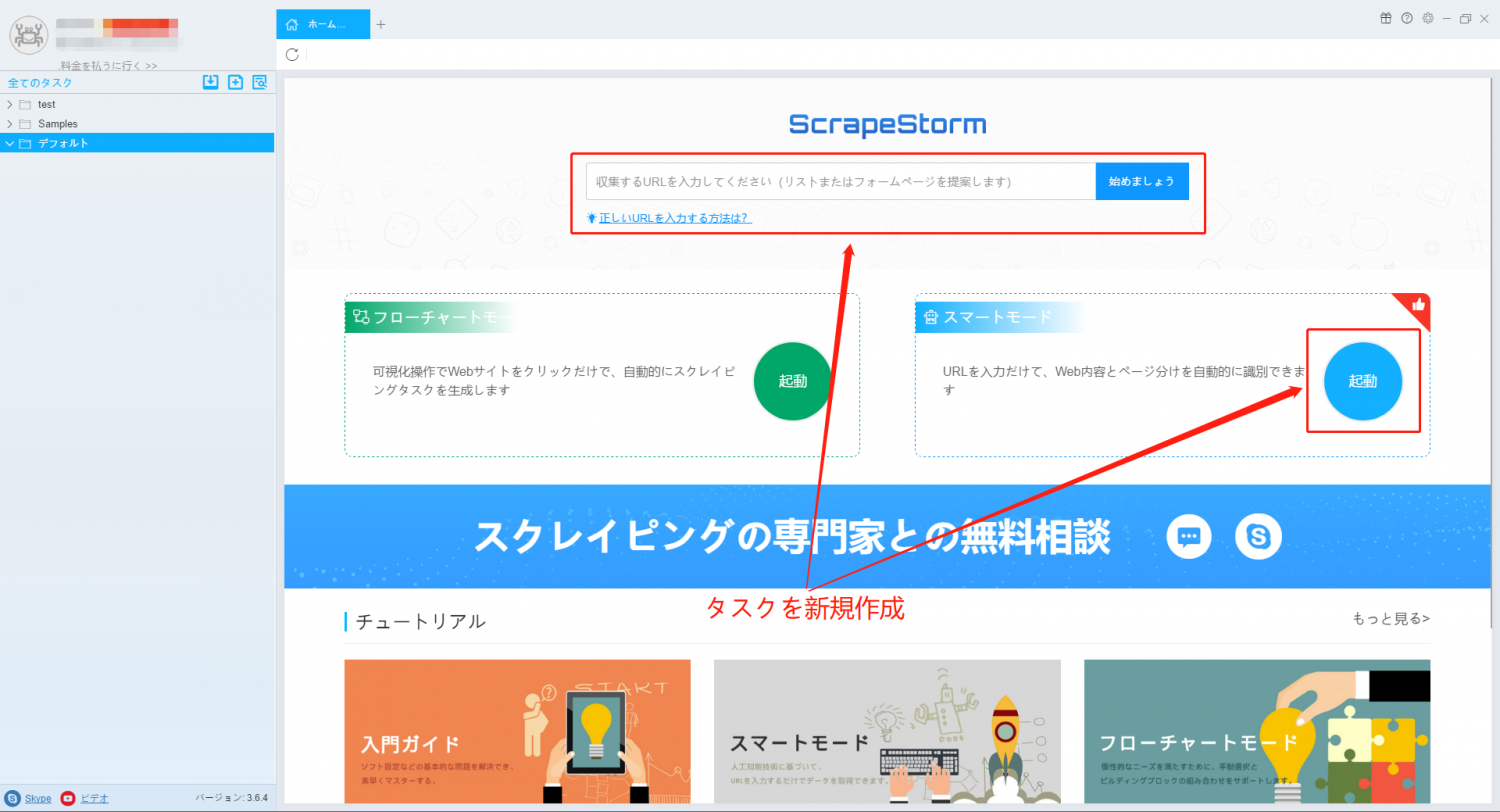
2. 事前操作画面に「クリック」コンポーネントを追加し、最終ページにジャンプします。
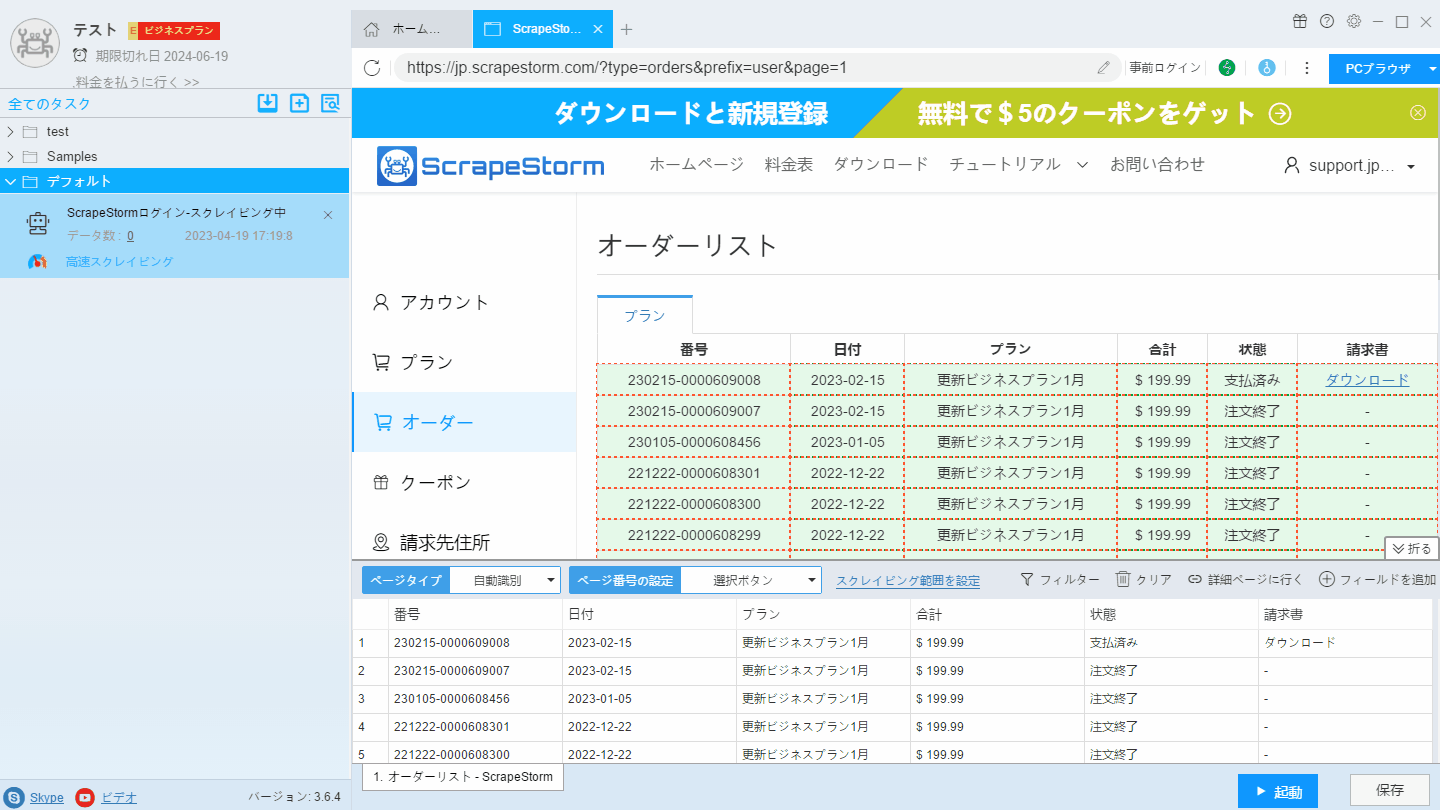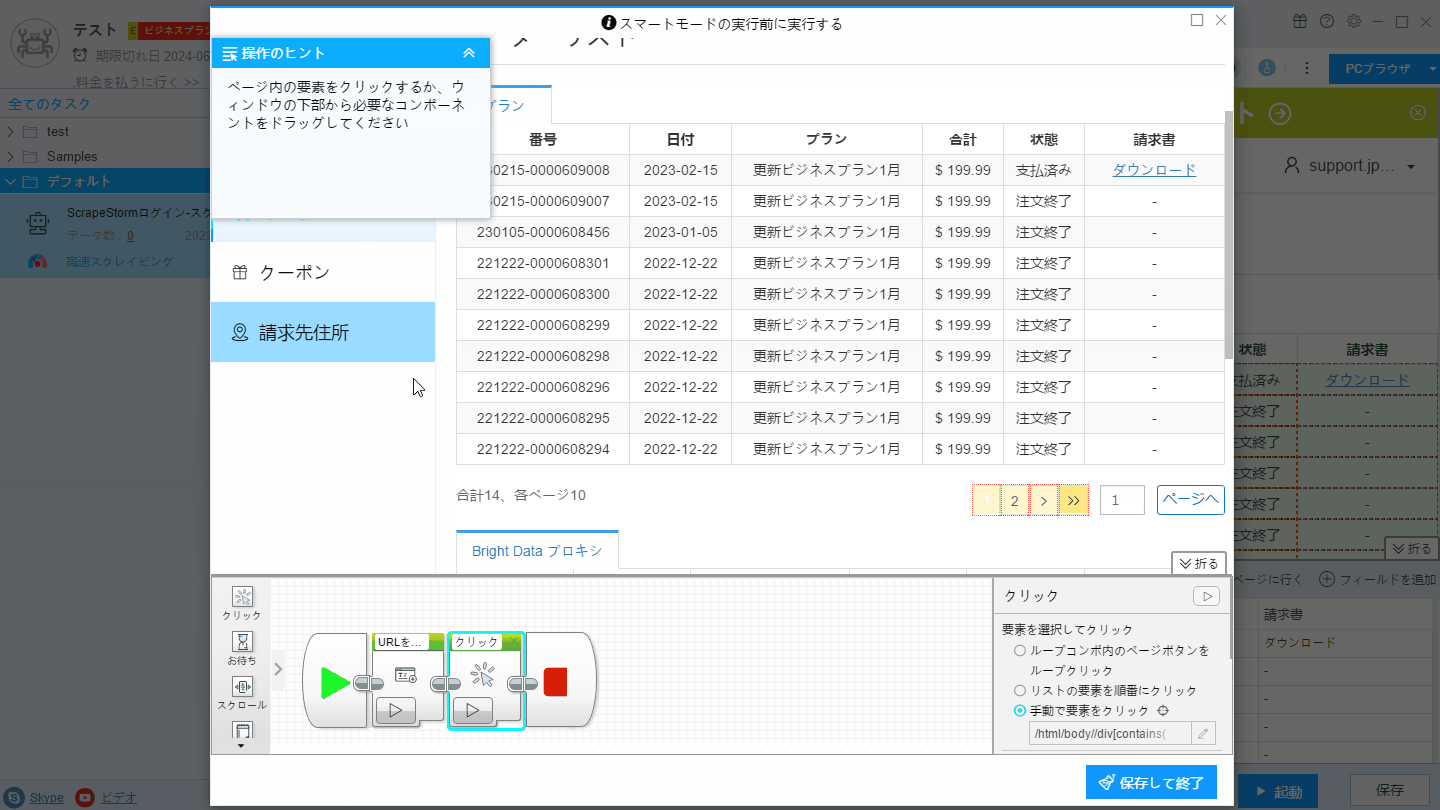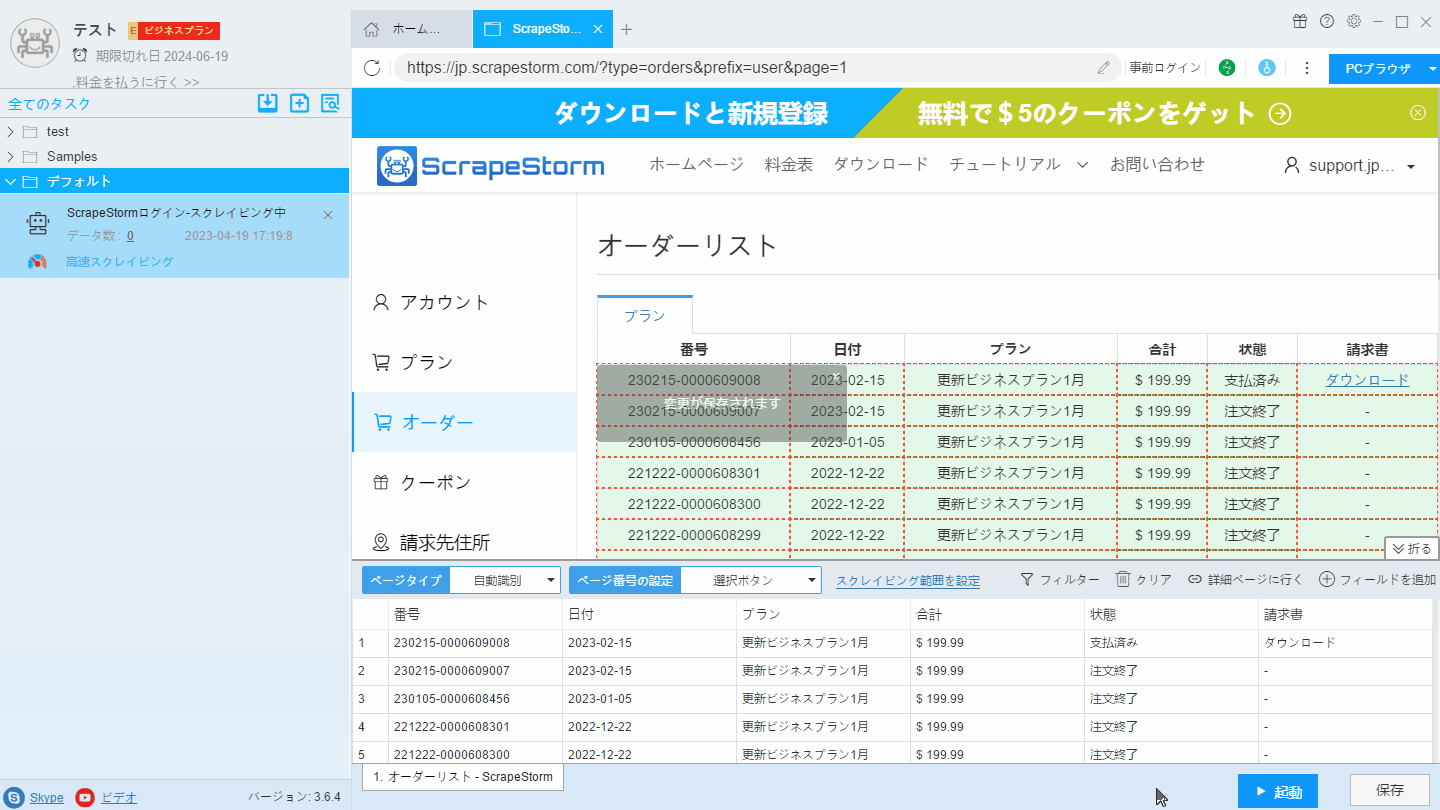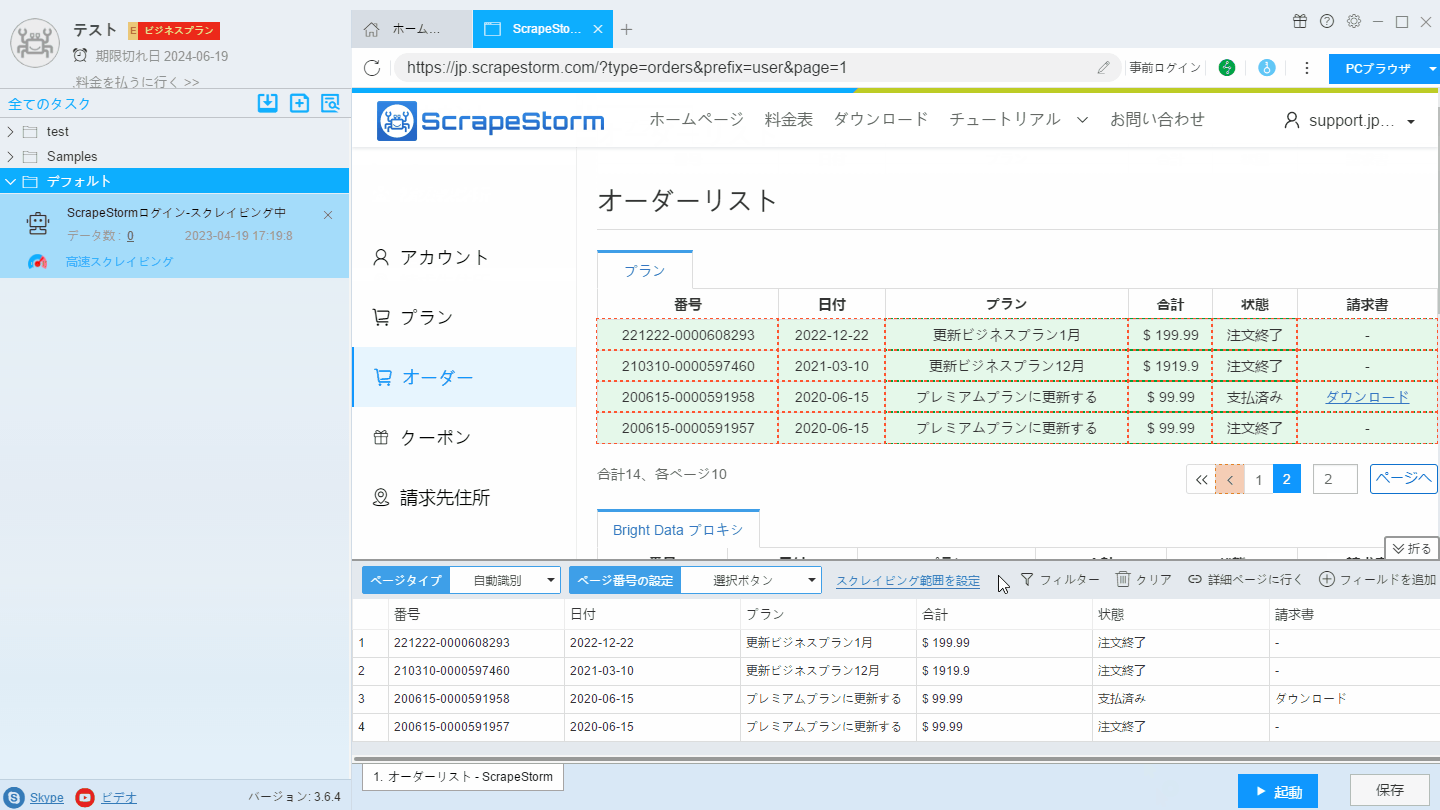
3. ページネーションボタンを設定し、「前のページ」ボタンを手動でクリックして認識し、ページをめくります。
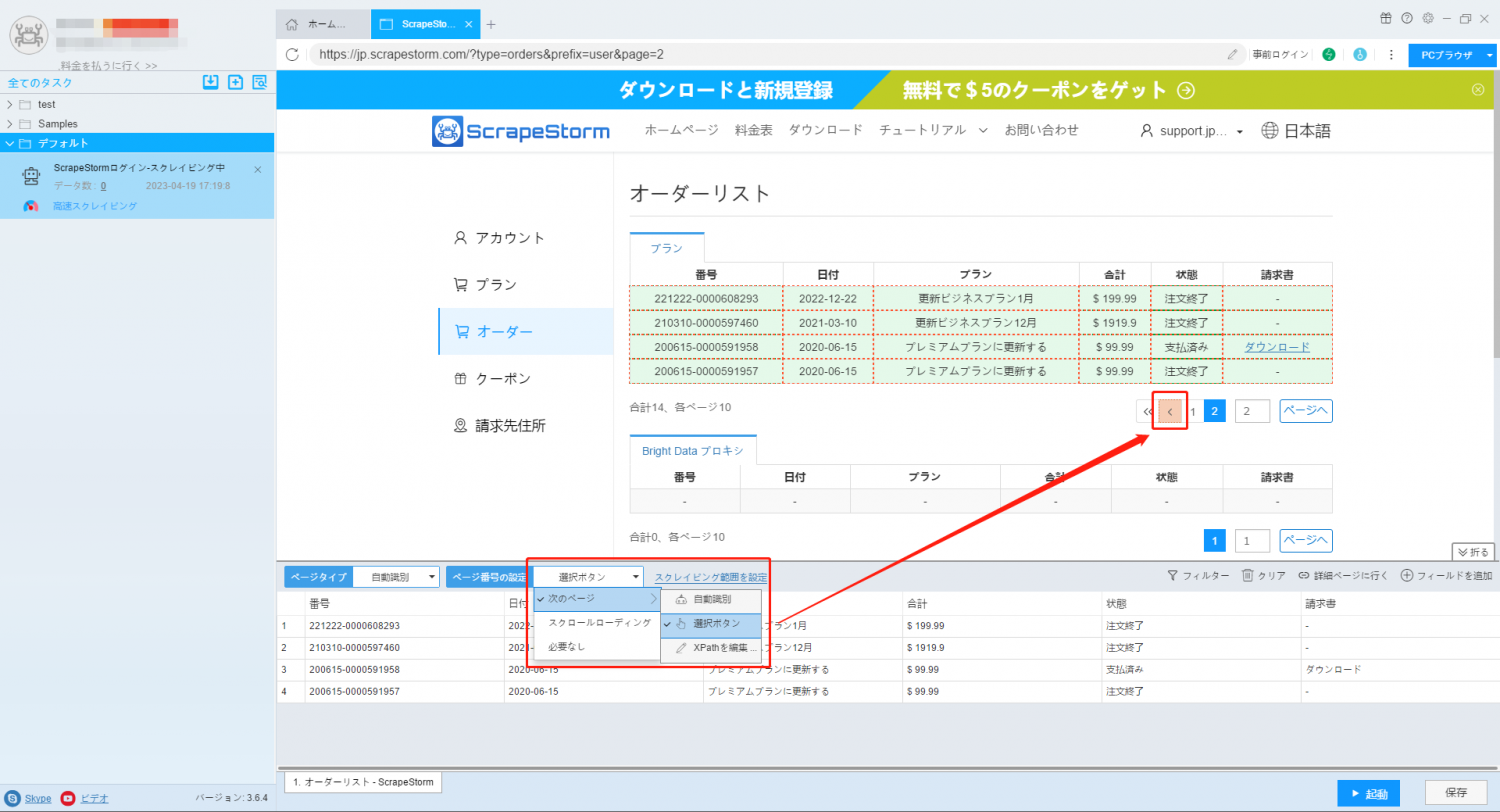
4. タスクを起動して、逆順で収集します。
処理方法二:Webページにページ番号の入力ボックスがある
ページをめくってもWebサイトのリンクが変わらず、最終ページのリンクを直接取得できない場合、最終ページのページ番号を直接入力することで最終ページにジャンプし、逆順で収集できます。
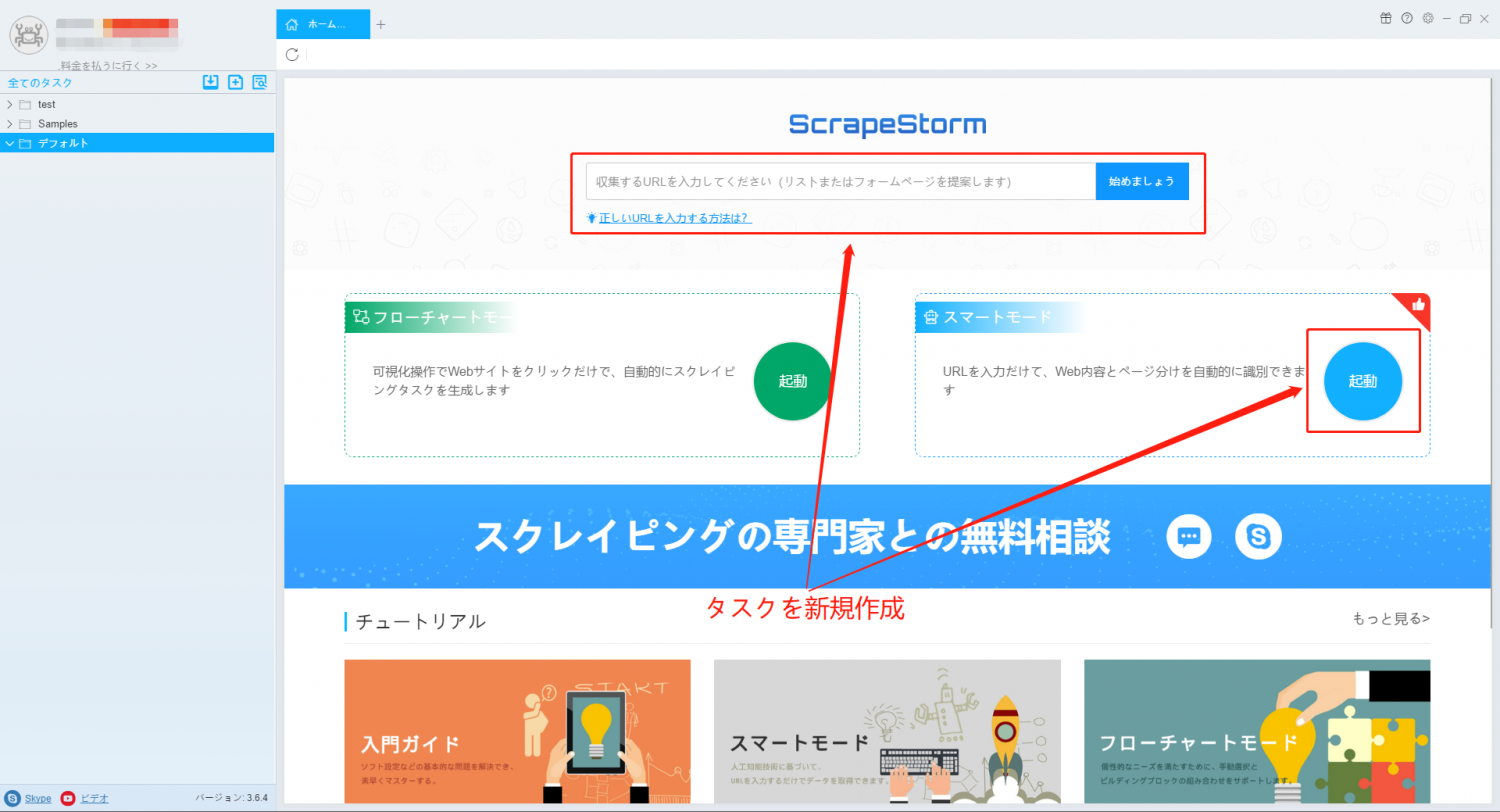
1. スマートモードタスクを新規作成する。
2. 事前操作画面に「テキストを入力」と「クリック」コンポーネントを追加し、最終ページにジャンプします。
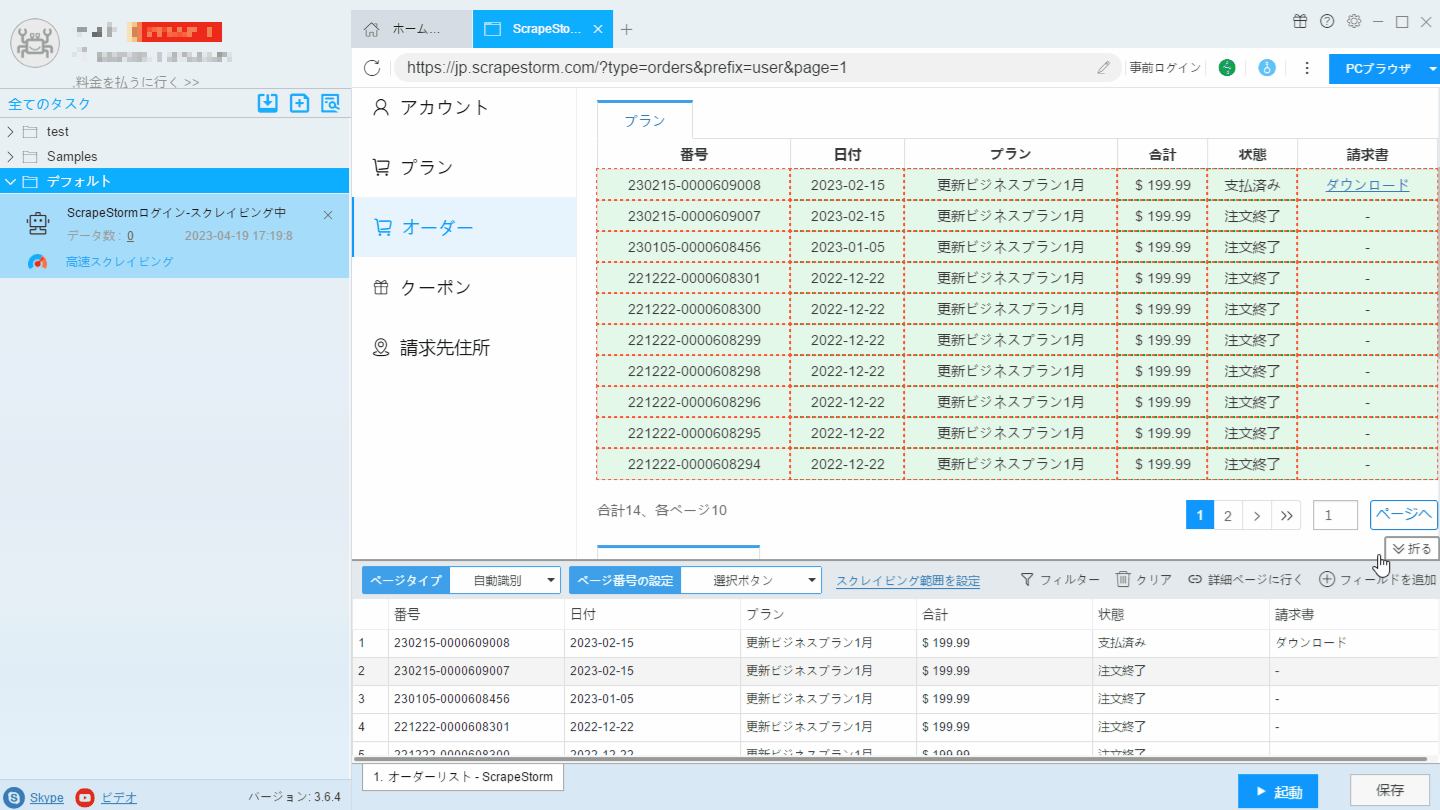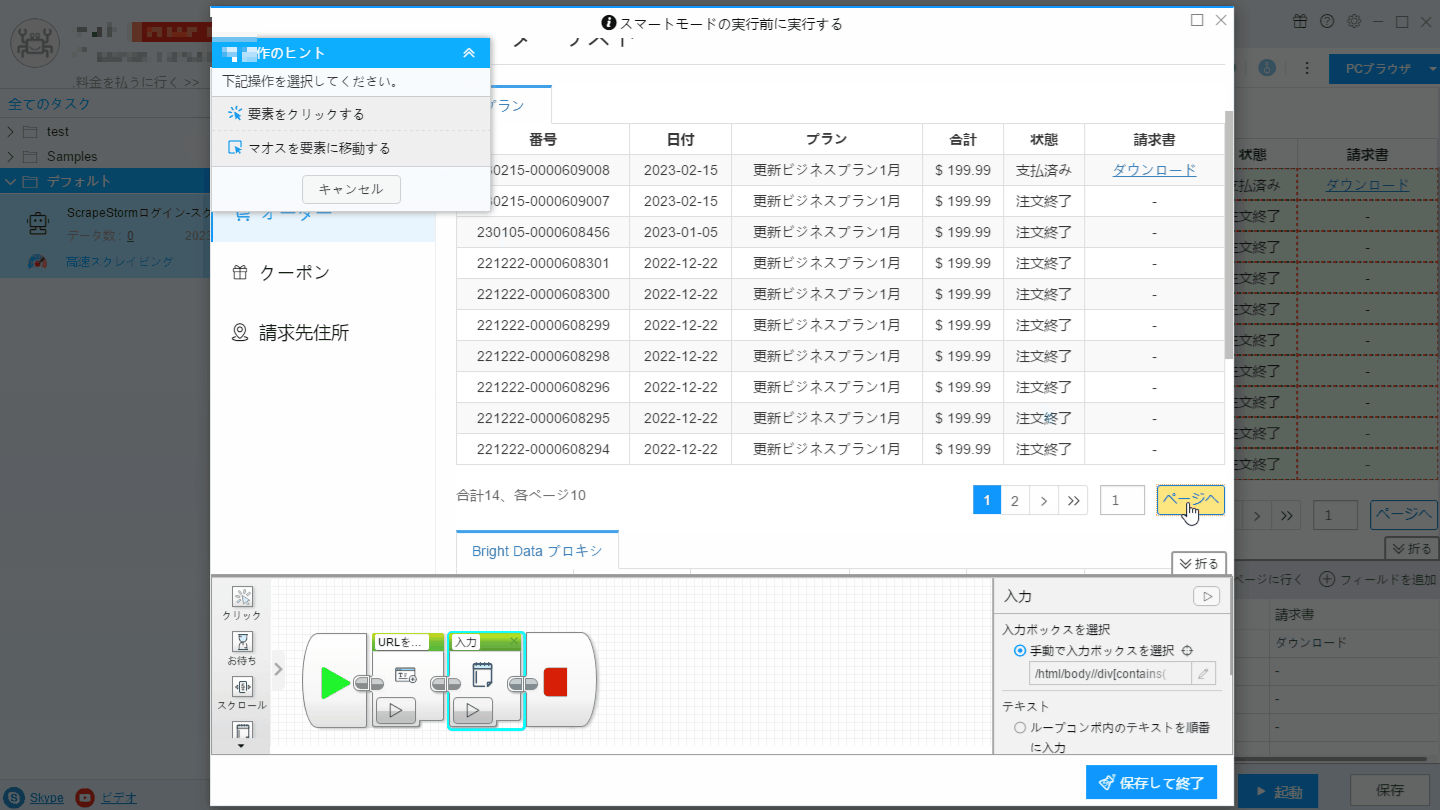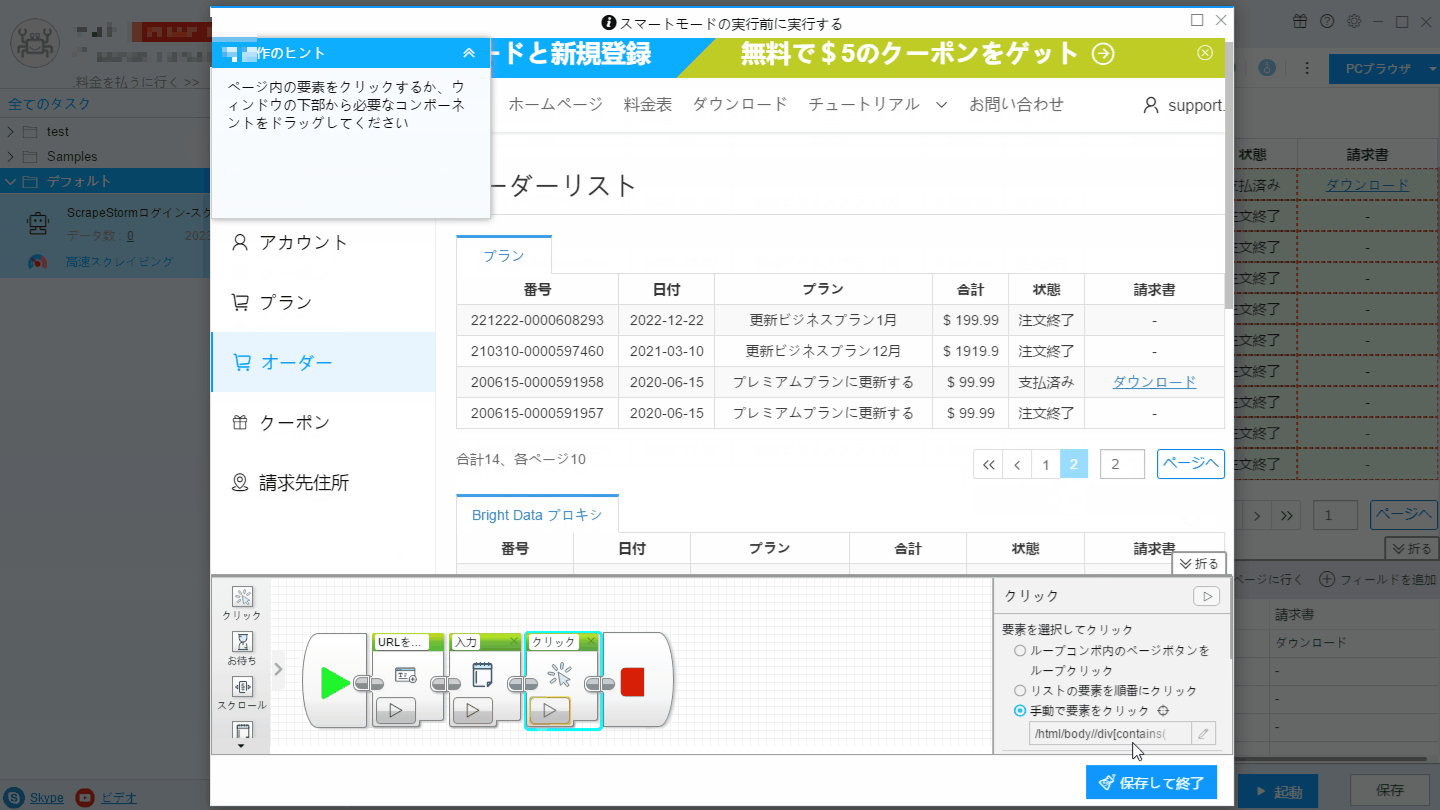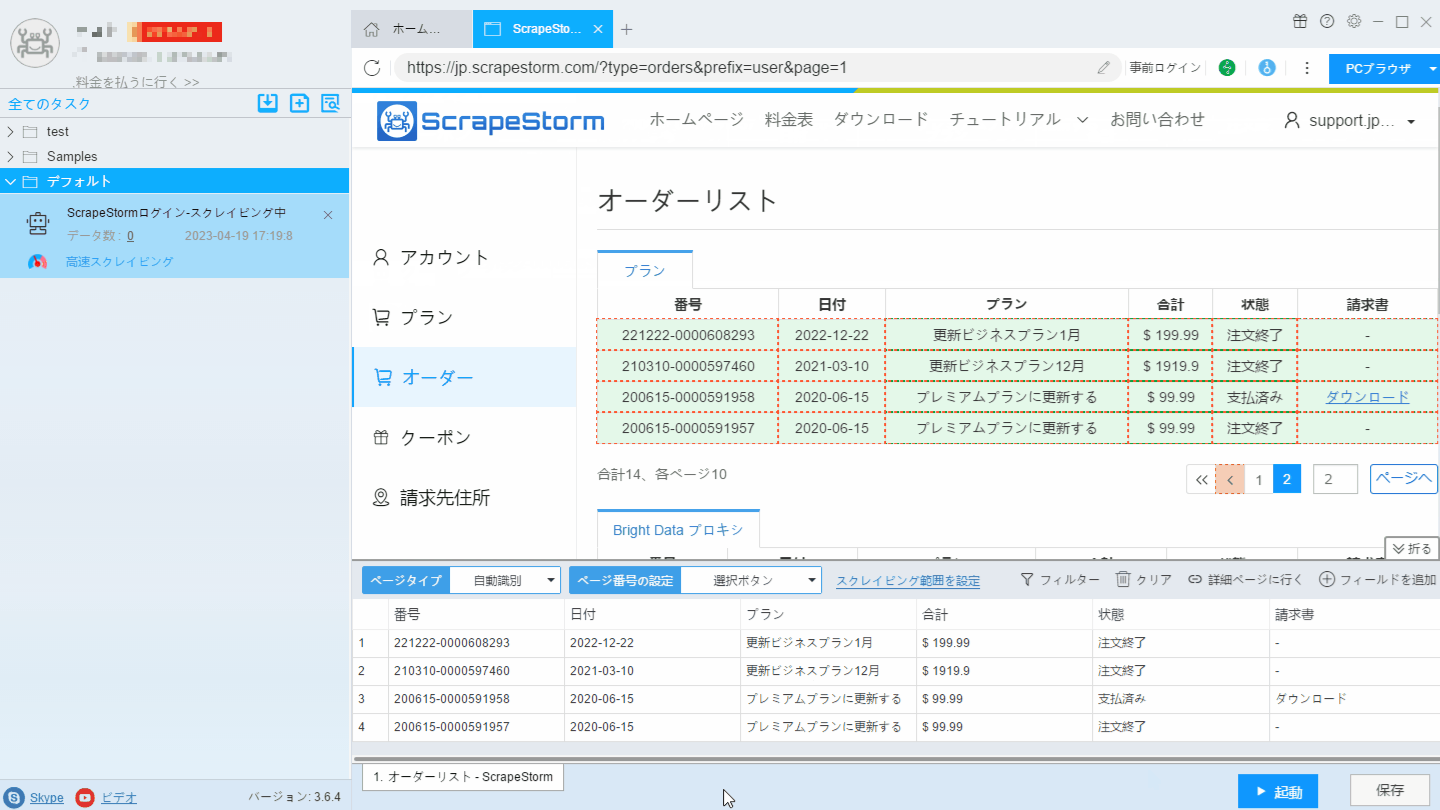
3. ページネーションボタンを設定し、「前のページ」ボタンを手動でクリックして認識し、ページをめくります。
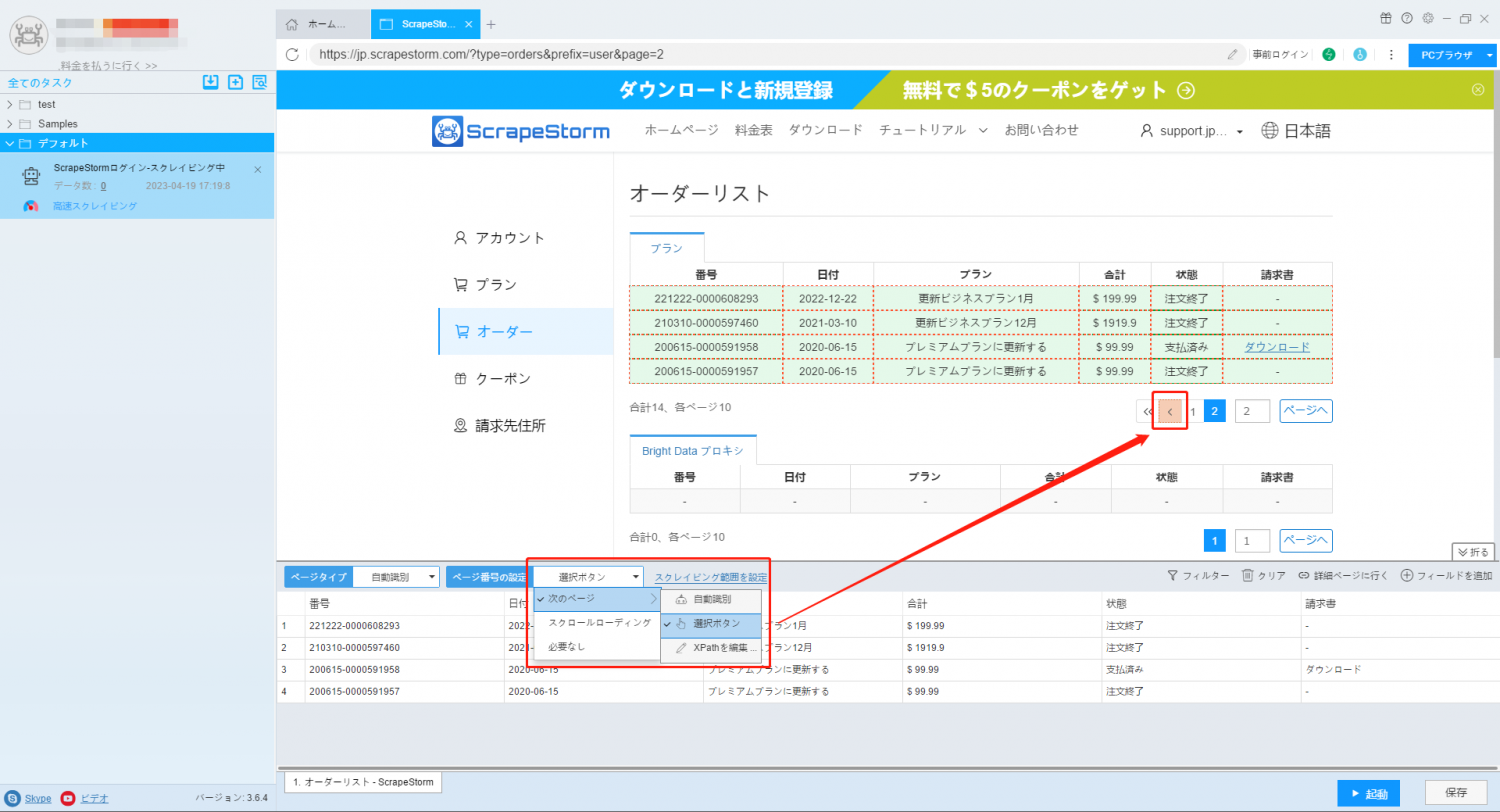
4. タスクを起動して、逆順で収集します。