データ・ラベリング (Data Labeling) | Webクローラ | ScrapeStorm
摘要:データ・ラベリングとは、機械学習や人工知能の学習データに対して「正解情報(ラベル)」を付与する作業を指します。たとえば、画像に写っている物体が「犬」であると指定したり、文章が「ポジティブな感情を示している」と分類したりするなど、AIが正確に学習・予測するための基礎を築く重要な工程です。教師あり学習(supervised learning)を行う際には不可欠な前処理であり、AIの精度や性能に直結するため、極めて重要な役割を果たします。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データ・ラベリングとは、機械学習や人工知能の学習データに対して「正解情報(ラベル)」を付与する作業を指します。たとえば、画像に写っている物体が「犬」であると指定したり、文章が「ポジティブな感情を示している」と分類したりするなど、AIが正確に学習・予測するための基礎を築く重要な工程です。教師あり学習(supervised learning)を行う際には不可欠な前処理であり、AIの精度や性能に直結するため、極めて重要な役割を果たします。
適用シーン
データ・ラベリングは多岐にわたる分野で活用されています。医療現場ではCTスキャン画像の異常部位にラベルをつけて診断支援を行い、自動運転ではカメラ映像に対して車両・人・信号機などのオブジェクトに識別情報を与えます。また、チャットボットやSNS分析などの自然言語処理分野では、顧客の意図や感情を分類するために膨大なテキストにラベルを付ける必要があります。さらに音声認識では話者の言葉や感情を、映像解析では動きや行動を識別し、スポーツ解析や監視カメラの異常検知などにも応用されています。
メリット:データ・ラベリングの最大のメリットは、AIの学習精度を飛躍的に高められる点にあります。正確かつ一貫性のあるラベル情報があれば、学習データとしての信頼性が増し、より実用的なモデルの構築が可能になります。また、専門知識をもつ人が関与することで、高度な判断を必要とする分野においても有効なラベルデータを生成できます。さらに、ラベリング済みのデータは資産化され、他プロジェクトや将来の再学習にも活用できるため、長期的なAI戦略にとっても価値があります。
デメリット:一方で、データ・ラベリングにはコストと時間が大きくかかるというデメリットがあります。特に大量のデータを扱う場合、手動でラベルを付ける作業は膨大で、人件費も無視できません。また、ラベルの質にばらつきがあると、モデルの精度が落ちたり、偏った学習を引き起こしたりするリスクもあります。さらに、ラベル作業には専門知識が必要なケースも多く、適切な人材の確保も課題となります。自動ラベリング技術の導入によって部分的な負担軽減は可能ですが、完全な代替には至っていないのが現状です。
図例
- ラベル付きデータとラベルなしデータ。
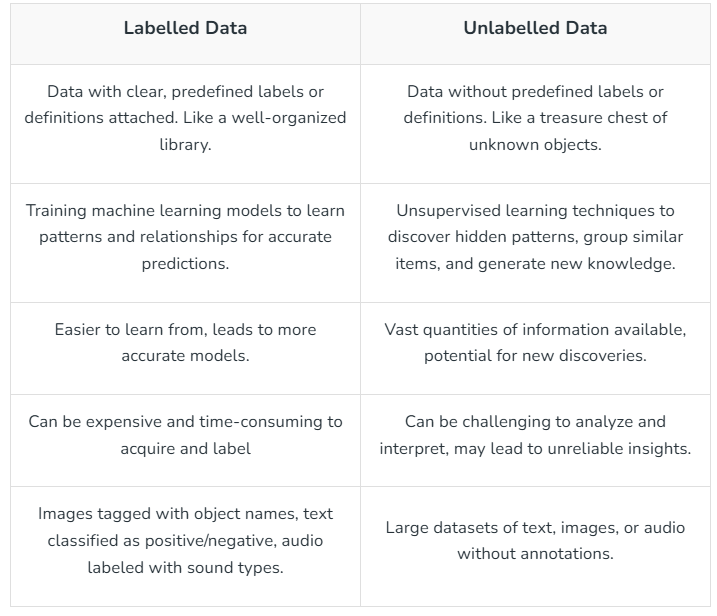
2. データラベルの種類。

関連記事
参考リンク
https://www.ibm.com/jp-ja/topics/data-labeling