データパイプライン(Data Pipeline) | Webクローラ | ScrapeStorm
摘要:データ パイプラインとは、ソースからデータを抽出し、変換、処理し、最終的にデータ システム内のターゲットの場所にロードするために使用される一連のデータ処理ステップとツールを指します。 通常、データ抽出、クリーニング、変換、ロード (ETL) などの段階が含まれます。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データ パイプラインとは、ソースからデータを抽出し、変換、処理し、最終的にデータ システム内のターゲットの場所にロードするために使用される一連のデータ処理ステップとツールを指します。 通常、データ抽出、クリーニング、変換、ロード (ETL) などの段階が含まれます。

適用シーン
データ パイプラインは、後続のデータ分析とマイニングのために複数のデータ ソースからデータを収集および統合するために使用されます。 リアルタイムまたはストリーミング データ システムでは、データ パイプラインを使用してデータを迅速に処理し、リアルタイムまたはほぼリアルタイムで分析および操作します。 データ パイプラインは、データの移行と同期だけでなく、異なるアプリケーション間のデータ転送と統合にも使用できます。
メリット:データ パイプラインはデータ処理を自動化し、一貫した標準に従ってデータが変換およびロードされるようにし、データ品質を向上させることができます。 データ パイプラインは、ニーズに応じて調整し、新しいステップを追加したり、データ処理プロセスを変更したりできるため、柔軟性と拡張性が高くなります。 データ パイプラインにより、ソースから宛先までのデータの信頼性の高い送信と処理が可能になり、データの損失とエラーが軽減されます。
デメリット:データ パイプラインの設計とメンテナンスには、技術的な専門知識と慎重な計画が必要であり、多大な時間とリソースが必要となる場合があります。 データの送信および処理中にデータ漏洩やセキュリティ上の問題が発生する可能性があるため、データを保護するためにセキュリティ対策を講じる必要があります。 大量のデータを処理する場合、パフォーマンスのボトルネックや処理速度の低下が発生する可能性があります。
図例
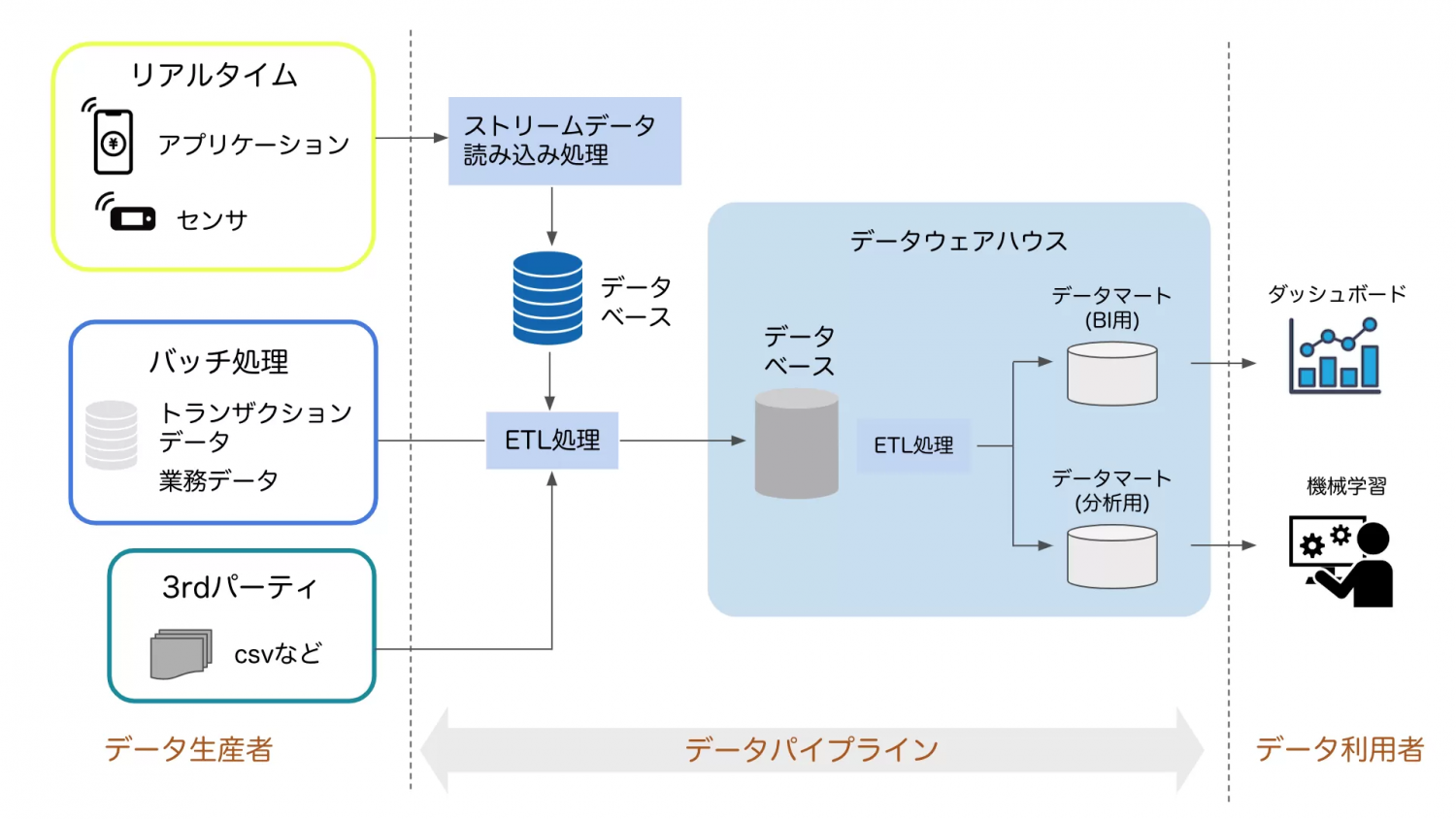
1. データパイプライン。
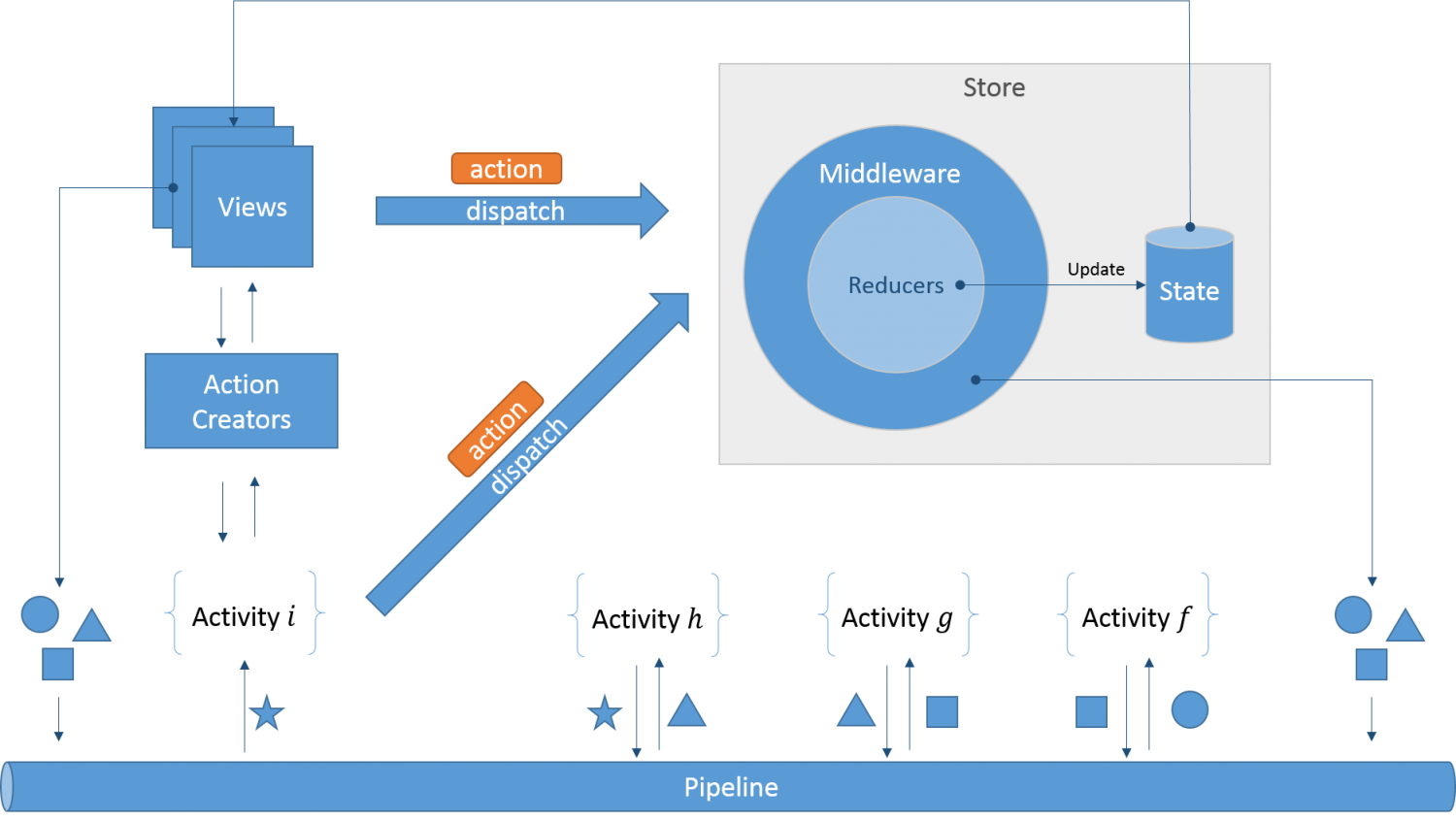
2. データパイプライン。
関連記事
参考リンク
https://www.talend.com/jp/resources/what-is-a-data-pipeline/