クローラーを学ぶ前に知るべき基礎 - ScrapeStorm
摘要:今回は、クローラーを学ぶ前にクローラーの基礎を簡単に紹介します。 ScrapeStorm無料ダウンロード
SEOを担当されている方ならクローラー、クローリングやスクレイピングといった言葉をよく耳にするのではないでしょう。今回は、クローラーを学ぶ前にクローラーの基礎を簡単に紹介します。
1.クローラーとスクレイピングの区別
クローラ(Crawler)とは、ウェブ上の文書や画像などを周期的に取得し、自動的にデータベース化するプログラムです。「ボット(Bot)」、「スパイダー」、「ロボット」などとも呼ばれ、主に検索エンジンのデータベース、インデックス作成に用いられているほか、統計調査などの目的にも利用されます。
スクレイピングとは、「特定のニーズに合わせた」Webクローラーの一種です。検索エンジンクローラーとの違いは、スクレイピングがコンテンツを処理およびフィルターし、要件に関連するWebページ情報のみをクロールするようにすることです。
2.HTTPステータスコード
(1)ブラウザにhttpリクエストを送信する
誰でも知っているように、クローラーの前提は、さまざまな「403禁止される」、「404Webページを見つけられない」のようなHTTPステータスコードを出現しない、Webサイトに正常にアクセスできることです。では、なぜHTTPステータスコードがよく見つけられますか?
ます、ブラウザにhttpリクエストを送信するプロセスを紹介します。
httpリクエストを送信するには二種類の方法があります。
Get
Getリクエストは主にWebページにデータを取得するために使われます。取得したデータはWebサイトが展示されるデータです。例えば、Yahoo!ショッピングに展示された商品情報はGetリクエストでアクセスしてくれます。
Post
Postリクエストは主にWebページにデータを送信するために使われます。例えば、Yahoo!ショッピングにアカウントとパスワードを入力、ログインをクリックして、Yahoo!ショッピングにPostリクエストを送信します。Webサイトはアカウントとパスワードに基づき、ログインを許可します。
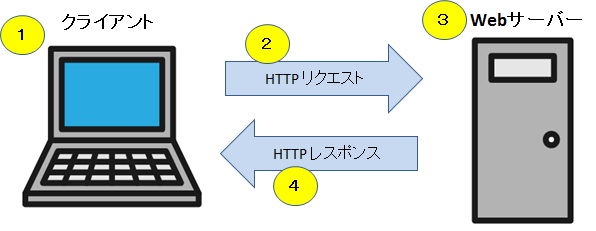
(2)ヘッダーデータ
httpリクエストが分かりましたなら、リクエストのヘッダーデータを紹介します。まず、Webサイトを開きます。今回は、Googleを例として紹介します。キーボードのF12をクリックして、バックグラウンドを開き、ヘッダーデータが表示されます。
違うサイトのヘッダーデータが違います。偶にデータがクローラーできないの場合、その原因は、Webサイトは送信したリクエストのヘッダーデータを検証しました。もし、送信したヘッダーデータが足りないの場合、情報が取得できませんになりました。例えば、Webサイトがcookieを検証しましたが、ちょうとう送信したリクエストにcookieがないなら、Webサイトが「403」コードを報告して、データが取得できなくなります。
クローラーを学ぶ前に知るべき基礎は大体以上になります。データ分析がより大切になる今は、クローラー、スクレイピングなどの情報収集がどんどん重要になる一方だ。より良いWebスクレイピングツールがあれば、手数がかからずにデータを収集できます。ScrapeStormは、AIを使用した視覚的なWebスクレイピングツールです。プログラミングが必要なく、ほぼすべてのWebサイトからデータを抽出できます。強い機能を持って、使いやすいです。 URLを入力だけで、自動的に抽出するデータと次のページボタンを識別できます。複雑なルール設定が必要ないし、1-clickだけでスクレイピングをできます。
免責事項: 本文はユーザーが提供して、侵害がありましたら、ご連絡してすぐに削除します。ScrapeStormは、ユーザーが本ソフトウェアを使って行うすべての行為に対して、一切責任を負いません。