データ統合(Data Integration) | Webクローラ | ScrapeStorm
摘要:データ統合とは、相互に関連する分散異種データソースを統合し、ユーザーがこれらのデータソースに透過的にアクセスできるようにすることです。その主な目的は、データの分散と異種性を解決し、情報の共有と利用の効率を向上させ、データの一貫性と均一性を確保し、データ分析、レポート作成、意思決定などのアプリケーションをサポートすることです。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データ統合とは、相互に関連する分散異種データソースを統合し、ユーザーがこれらのデータソースに透過的にアクセスできるようにすることです。その主な目的は、データの分散と異種性を解決し、情報の共有と利用の効率を向上させ、データの一貫性と均一性を確保し、データ分析、レポート作成、意思決定などのアプリケーションをサポートすることです。

適用シーン
データ統合は、意思決定、ビジネス プロセスの最適化、顧客サービスの改善、その他の目標をサポートするために、さまざまなソースや形式のデータを統合、分析、活用する必要があるさまざまなアプリケーション シナリオに適しています。
メリット:データ統合により、データの集中管理と統一されたビューを実現し、データの共有と利用の効率を向上させ、部門間およびシステム間のデータコラボレーションをサポートし、企業のデータ統合機能とビジネスインサイトを強化できます。
デメリット:データ統合プロセスでは、データ品質、データ同期、一貫性のないデータ形式や保存方法などの課題に直面する可能性があり、データの処理と調整に多くの人的資源、物的リソース、時間が必要となり、データのセキュリティとプライバシー保護にリスクが伴います。
図例
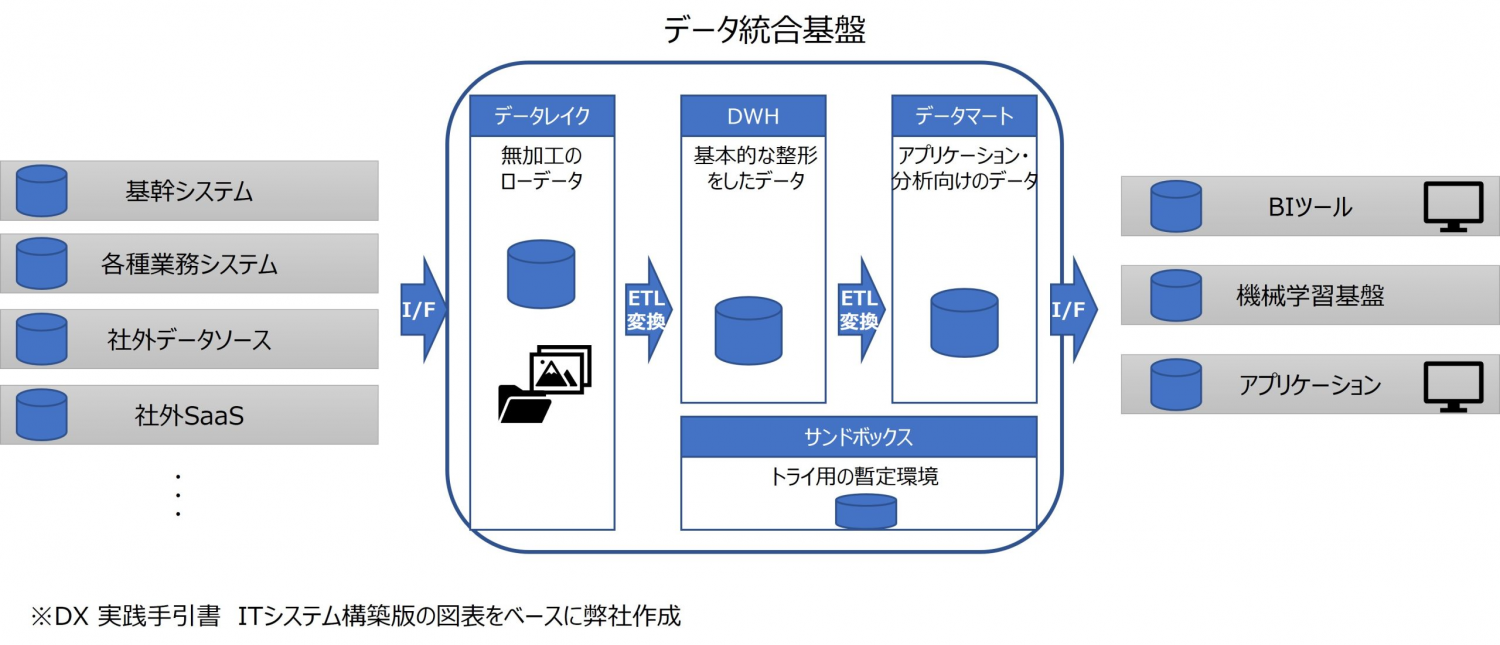
1. データ統合基盤。
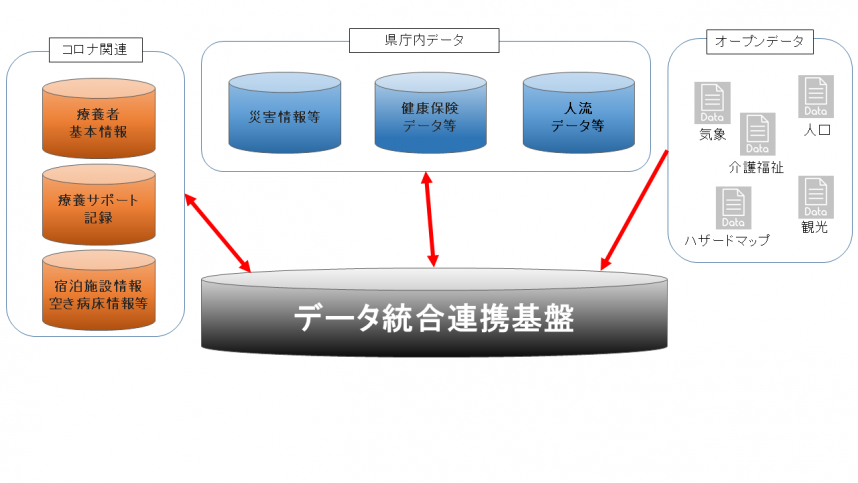
2. データ統合連携基盤。
関連記事
参考リンク
https://cloud.google.com/learn/what-is-data-integration?hl=ja