データ重複排除 (Data Deduplication) | Webクローラ | ScrapeStorm
摘要:データ重複排除 (Data Deduplication) は、データセット内のデータの重複コピーを識別して排除し、データの一意のコピーとその参照のみを保持するデータ最適化テクノロジです。これにより、ストレージスペースの使用量を削減し、データ転送量を削減し、データ管理の効率を向上させます。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データ重複排除 (Data Deduplication) は、データセット内のデータの重複コピーを識別して排除し、データの一意のコピーとその参照のみを保持するデータ最適化テクノロジです。これにより、ストレージスペースの使用量を削減し、データ転送量を削減し、データ管理の効率を向上させます。
適用シーン
データ重複排除は、データセット内のデータの重複コピーを識別して排除し、データの一意のコピーとその参照のみを保持するデータ最適化テクノロジです。これにより、ストレージスペースの使用量を削減し、データ転送量を削減し、データ管理の効率を向上させます。
メリット:データ重複排除により、ストレージスペースを大幅に節約し、データ転送効率を向上させ、データ管理プロセスを簡素化できます。
デメリット:データ重複排除により、システムのコンピューティング オーバーヘッドが増加し、データの回復に影響する可能性があり、技術的な実装が複雑になります。
図例
1.データ重複排除。
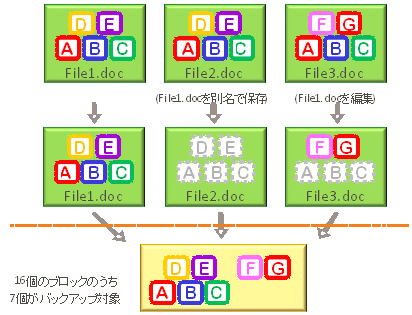
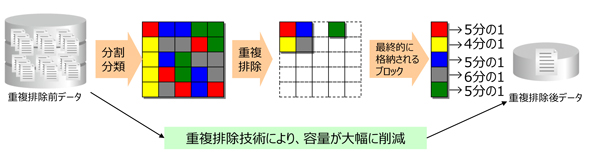
2. 重複排除の仕組み。
関連記事
参考リンク
https://atmarkit.itmedia.co.jp/fserver/articles/dedupe/01/01.html
https://techtarget.itmedia.co.jp/tt/news/1703/23/news02.html