XPath | Webクローラ | ScrapeStorm
摘要:XPath (XML Path Language) は、XML ドキュメント内のデータの移動とクエリに使用されるクエリ言語です。 これは W3C (World Wide Web Consortium) によって定義された標準であり、特に Web 開発やデータ スクレイピングの分野で、XML ドキュメントから情報を抽出するためによく使用されます。 XPath は、XML ドキュメント内の要素と属性を見つけてアクセスするための構造化された方法を提供します。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
XPath (XML Path Language) は、XML ドキュメント内のデータの移動とクエリに使用されるクエリ言語です。 これは W3C (World Wide Web Consortium) によって定義された標準であり、特に Web 開発やデータ スクレイピングの分野で、XML ドキュメントから情報を抽出するためによく使用されます。 XPath は、XML ドキュメント内の要素と属性を見つけてアクセスするための構造化された方法を提供します。

適用シーン
XPath は、JavaScript、Python、Java などの多くのプログラミング言語とツールだけでなく、データ スクレイピングや XML 処理用のツールでも広く使用されています。 これは、XML データを解析し、XML ドキュメントから有用な情報を抽出するための強力なツールです。
メリット:XPath は、文書構造が複雑であっても、XML 文書内の要素と属性を正確に見つけることができる柔軟な構文を提供します。 また、XPath 標準は広く採用されており、XPath をサポートするパーサーとライブラリは複数のプログラミング言語とプラットフォームで見つかるため、クロスプラットフォームおよびクロス言語ツールとなります。
デメリット:大規模な XML ドキュメントを処理する場合、一致するノードを見つけるためにドキュメント全体を解析する必要があるため、XPath のパフォーマンスが低下する可能性があります。 XPath の機能も、複雑な計算やデータ変換を必要とするタスクに対しては比較的制限されています。 この場合、タスクを完了するには、他のプログラミング言語やツールを組み合わせることが必要になる場合があります。
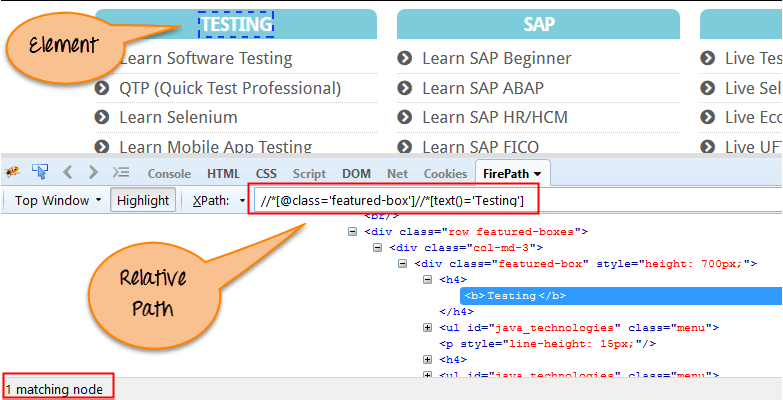
図例
1. Xpathの基本構造。
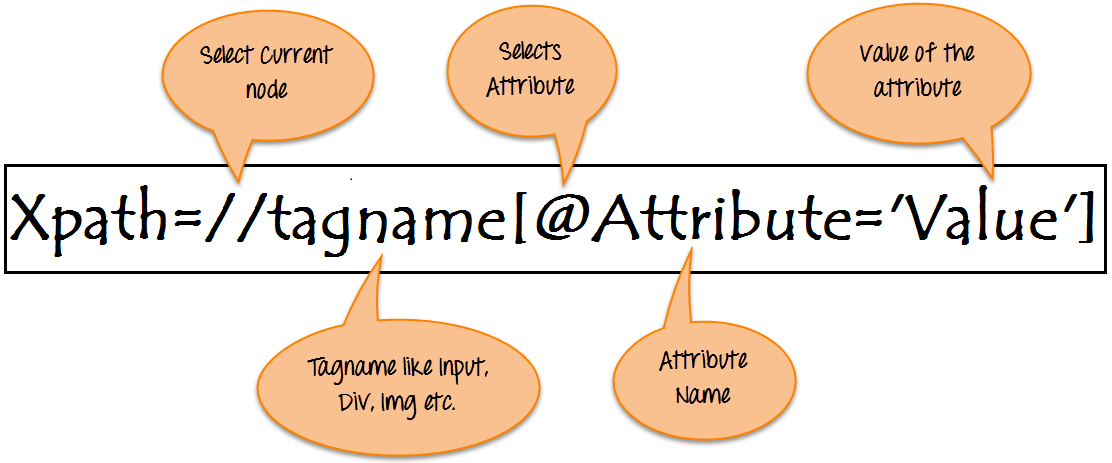
2. Xpath。