データ冗長性(Data Redundancy ) | Webクローラ | ScrapeStorm
摘要:データの冗長性とは、データ保存プロセス中に同じデータが複数回保存される状況を指します。これらの重複データは、同じデータセット内の異なる場所に出現したり、異なるデータ保存システムに散在したりする場合があります。これは、システム設計上の欠陥などによって意図されない場合もあれば、データの信頼性やパフォーマンスを向上させるために意図的な場合もあります。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データの冗長性とは、データ保存プロセス中に同じデータが複数回保存される状況を指します。これらの重複データは、同じデータセット内の異なる場所に出現したり、異なるデータ保存システムに散在したりする場合があります。これは、システム設計上の欠陥などによって意図されない場合もあれば、データの信頼性やパフォーマンスを向上させるために意図的な場合もあります。
適用シーン
これは、データの可用性とフォールトトレランスに対する要件が極めて高いシナリオに適しています。例えば、銀行システムでは、データ冗長化技術を用いて重要なデータを複数のストレージデバイスや地理的に離れた場所にバックアップすることで、ハードウェア障害や自然災害などによるデータ損失を防いでいます。大規模なeコマースプラットフォームでは、高い同時アクセスに対応するため、人気商品情報などのデータをキャッシュすることで、メインデータベースからの頻繁な読み取りを回避し、システムの応答速度を向上させています。
メリット:データの信頼性を向上してビジネスの継続性を確保し、システム パフォーマンスを向上して応答を高速化し、データ アクセスを簡素化して運用の効率を高めます。
デメリット:ストレージ コストが増加し、データの不整合の問題が発生し、データ保守の効率が低下します。
図例
1.データ冗長性。
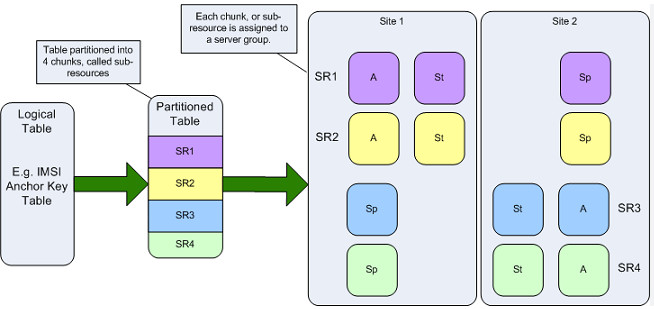
2. データ冗長性。
関連記事
参考リンク
https://en.wikipedia.org/wiki/Data_redundancy
https://www.ibm.com/think/topics/data-redundancy
https://www.techtarget.com/searchstorage/definition/redundant