データ抽出器(Data Extractor) | Webクローラ | ScrapeStorm
摘要:データ抽出器(Data Extractor)とは、膨大なデータセットから必要な情報だけを自動的に抽出・加工するためのツールや仕組みを指します。対象となるデータは、テキスト、数値データ、ログ、地理空間データ、画像など多岐にわたり、抽出器はこれらを特定の条件やルールに従って整理し、統一された形式で取り出す役割を果たします。多くの場合、フィルタリング、正規化、クリーニング、再構造化などの前処理機能も備えており、分析や可視化、機械学習モデルの入力として利用できる形に整形します。データの多様化と量の増大に伴い、Data Extractor は業務効率化や自動化の基盤として不可欠な存在となっています。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データ抽出器(Data Extractor)とは、膨大なデータセットから必要な情報だけを自動的に抽出・加工するためのツールや仕組みを指します。対象となるデータは、テキスト、数値データ、ログ、地理空間データ、画像など多岐にわたり、抽出器はこれらを特定の条件やルールに従って整理し、統一された形式で取り出す役割を果たします。多くの場合、フィルタリング、正規化、クリーニング、再構造化などの前処理機能も備えており、分析や可視化、機械学習モデルの入力として利用できる形に整形します。データの多様化と量の増大に伴い、Data Extractor は業務効率化や自動化の基盤として不可欠な存在となっています。
適用シーン
データ抽出器は、日常的な業務処理から高度なデータ解析まで幅広い分野で活用されています。企業の業務システムでは、ログデータや取引履歴から特定条件のレコードを取り出すことで、経営分析や顧客動向の把握に役立ちます。また、研究分野では、センサー計測値や観測データの前処理として頻繁に使用され、ノイズ除去やデータ整形により解析の精度を高めることができます。Webスクレイピングに基づく情報収集や、GIS分野での地理空間データの抽出にも適しており、必要な地域・属性のみを取り出すことで効率的な可視化やモデル構築が可能になります。さらに、機械学習やAI開発においては、複数のデータソースから入力データを統合し、学習に適した形式へ加工する工程において、Data Extractor は不可欠な役割を担っています。
メリット:データ抽出器の最大の利点は、大規模データの処理を自動化することで、作業時間と人的コストを大幅に削減できる点にあります。明確なルールに基づいて抽出や整形を行うため、作業の再現性と精度が高く、ミスの少ないデータセットを安定して生成することができます。また、複数の異なるデータ形式を統一的に扱えるため、システム間の連携を容易にし、データ分析や可視化の前段階を効率化します。分析者は前処理にかかる時間を減らし、本来の解析業務に集中できるようになります。さらに、定期的なデータ抽出を自動化することで、最新データに基づくレポート更新や監視システムの構築も可能になります。
デメリット:一方で、データ抽出器にはいくつかの課題も存在します。抽出ルールや正規化条件が複雑になると設定作業が難しくなり、適切な設計を行わないと誤抽出や欠落が生じる可能性があります。また、非構造化データや品質にばらつきのあるデータに対しては、抽出精度が安定しない場合があり、追加のクリーニングや手動補正が必要となることがあります。データソースが更新された結果、構造変更やフィールド名の変更が発生すると、抽出器が正常に機能しなくなることもあり、定期的な保守が不可欠です。さらに、抽出処理が大量データに対して負荷となる場合、実行時間やサーバーリソースを圧迫し、全体の処理フローに影響を与えることがあります。
図例
1. Azure portal の [監視] メニューの [データ収集ルール] オプション。
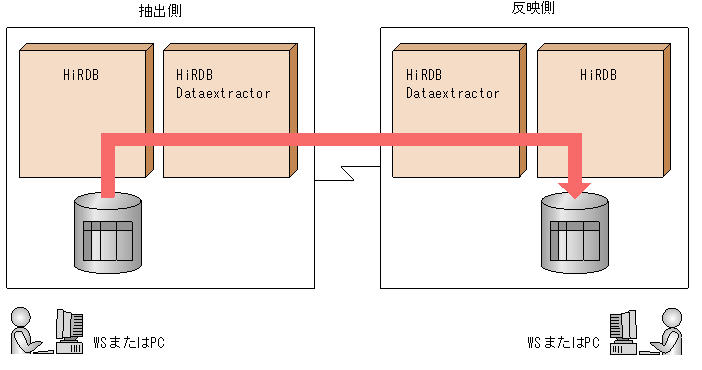
2. データ抽出器ーScrapeStorm。
関連記事
参考リンク
https://itpfdoc.hitachi.co.jp/manuals/3020/3020636230/W3620006.HTM
https://itpfdoc.hitachi.co.jp/manuals/3020/3020636230/W3620007.HTM