データのインデックス(Data Indexing) | Webクローラ | ScrapeStorm
2025-04-29 09:58:10
392 ビュー
摘要:データインデックスは、データ検索を高速化するために使用されるデータ構造です。キーワードとデータの保存場所の間にマッピング関係を確立することで、クエリの効率を向上させます。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データインデックスは、データ検索を高速化するために使用されるデータ構造です。キーワードとデータの保存場所の間にマッピング関係を確立することで、クエリの効率を向上させます。
適用シーン
これは、データベース システム、検索エンジン、データ分析プラットフォームなどの大規模なデータ ストレージ システムで頻繁かつ高速なクエリ、並べ替え、グループ化が必要なシナリオに適しています。
メリット:インデックス構造を通じてデータを素早く見つけ、テーブル全体のスキャンのコストを削減し、ディスク I/O 操作の頻度を減らし、全体的なデータ処理効率を向上させます。
デメリット:インデックスは追加のストレージスペースを必要とし、データ更新時にインデックス構造を同期的に維持する必要があります。データの挿入、更新、または削除操作が頻繁に行われると、インデックスの再構築が発生し、システムの応答速度に影響を及ぼします。
図例
- データのインデックス。
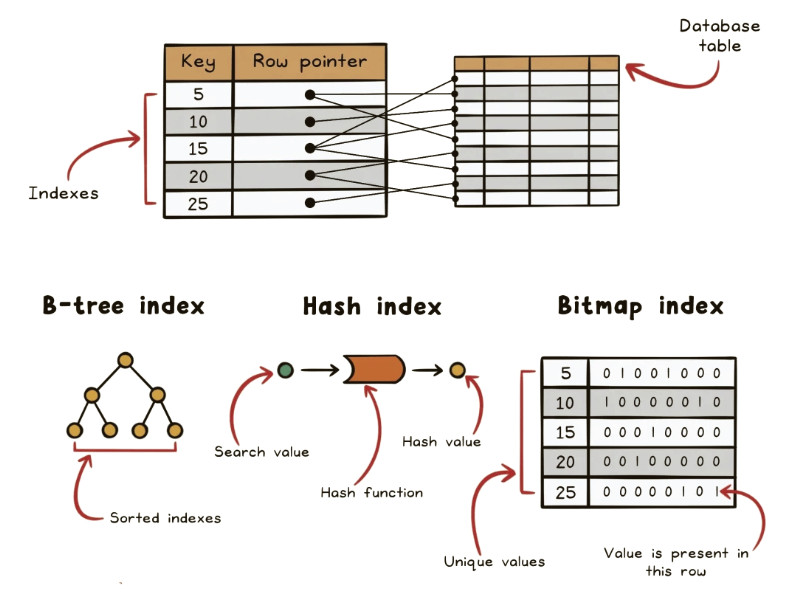
2. データのインデックス。
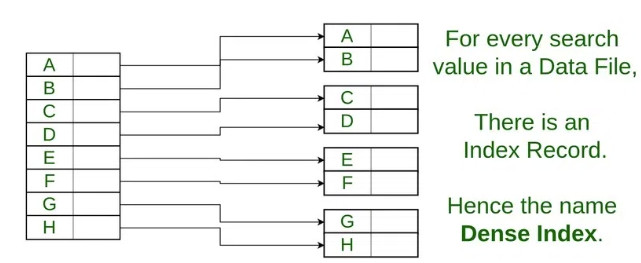
関連記事
参考リンク
https://zenn.dev/tm35/articles/f9d17c593d7766