データ ランディング(Data Landing) | Webクローラ | ScrapeStorm
摘要:データランディング(Data Landing)とは、多様なシステムやデータソースから収集したデータを、まず一時的に蓄積・保管するための領域またはプロセスを指します。これは「着陸地点」という名称の通り、データが本格的に分析や加工に利用される前に、安全かつ効率的に集約される段階です。データレイクやデータウェアハウスに投入する前の中間工程として活用されることが多く、データ品質のチェックや形式変換、セキュリティ上のフィルタリングなどが実行されます。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データランディング(Data Landing)とは、多様なシステムやデータソースから収集したデータを、まず一時的に蓄積・保管するための領域またはプロセスを指します。これは「着陸地点」という名称の通り、データが本格的に分析や加工に利用される前に、安全かつ効率的に集約される段階です。データレイクやデータウェアハウスに投入する前の中間工程として活用されることが多く、データ品質のチェックや形式変換、セキュリティ上のフィルタリングなどが実行されます。
適用シーン
データランディングは、企業のデータ統合基盤やDX(デジタルトランスフォーメーション)推進において重要な役割を果たします。たとえば、IoTセンサーからの大量データを一旦受け入れて整形する、クラウドサービスや外部APIから取得した情報を安全に保管する、といった場面で利用されます。また、金融業界ではログやトランザクションデータを一度ランディングエリアに置くことで、規制遵守のための監査やフィルタリングを実現できます。さらに、データサイエンスや機械学習の現場では、学習用データを整備する前段階として必須の工程です。
メリット:データランディングの最大のメリットは、異なる形式や精度で収集されたデータを効率的に整理・標準化できる点です。これにより、後続の分析や可視化、AI活用のプロセスがスムーズになり、データ品質を高いレベルで維持できます。また、セキュリティ面でも利点があり、外部からのデータを直接コアシステムに流さず、一時的に隔離することでリスクを低減できます。さらに、ストリーミングデータやバッチ処理データを同時に受け入れられる柔軟性も大きな強みです。
デメリット:データランディングには課題も存在します。まず、一時的な保管領域を確保するためのインフラコストがかかる点です。また、適切に運用しなければ「データのたまり場」と化し、不要な情報が積み上がることで管理コストや検索効率の低下を招きます。さらに、ランディング段階での処理フローが複雑化すると、全体のデータパイプラインに遅延が発生する恐れがあります。そのため、適切なガバナンスと自動化ツールの導入が不可欠となります。
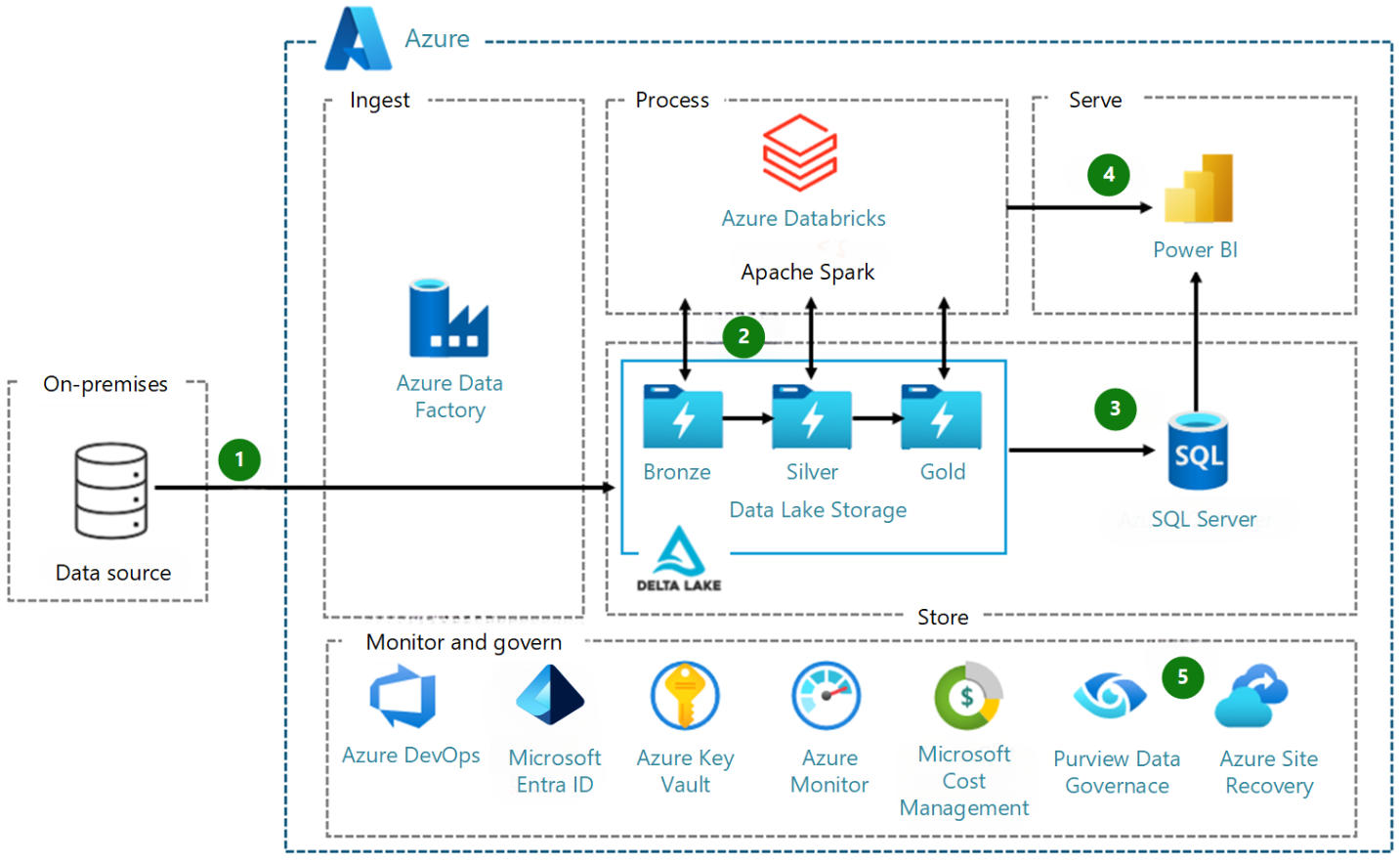
図例
1. データ ランディング ゾーン。
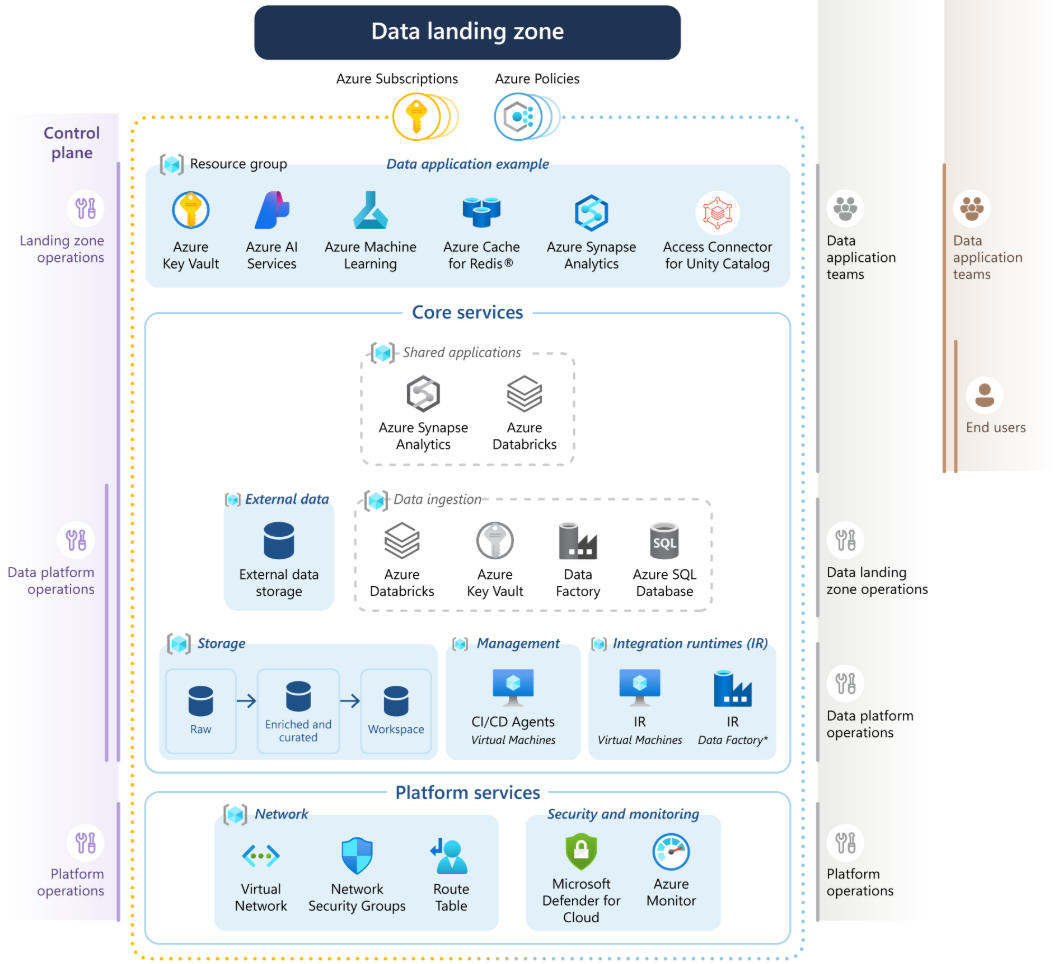
2.アーキテクチャ。