データ源識別(Data Source Identification) | Webクローラ | ScrapeStorm
摘要:データ源識別(Data Source Identification)とは、組織やシステム内外に存在する多様なデータの発生源・所在・形式・更新頻度・所有者などを体系的に特定し、分類・整理するプロセスを指します。その核心的な目的は、後続のデータ統合、分析、ガバナンス、セキュリティ管理を円滑に進めるための基盤を確立することにあります。データウェアハウス構築、データパイプライン設計、マスターデータ管理、AI モデル開発などにおいて、最初に実施すべき重要工程と位置付けられます。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データ源識別(Data Source Identification)とは、組織やシステム内外に存在する多様なデータの発生源・所在・形式・更新頻度・所有者などを体系的に特定し、分類・整理するプロセスを指します。その核心的な目的は、後続のデータ統合、分析、ガバナンス、セキュリティ管理を円滑に進めるための基盤を確立することにあります。データウェアハウス構築、データパイプライン設計、マスターデータ管理、AI モデル開発などにおいて、最初に実施すべき重要工程と位置付けられます。
適用シーン
データ源識別は、新規システム導入時の現状分析、データ統合プロジェクト、クラウド移行計画、データガバナンス強化、BI 基盤構築など、組織横断的なデータ活用シナリオに適しています。特に、部門ごとに分散したデータベース、外部 API、ログファイル、IoT センサー、SaaS アプリケーションなどが混在する環境において、その全体像を可視化し、依存関係を明確にするために不可欠です。
メリット:データ源識別を実施することで、データ資産の所在と責任範囲が明確になり、重複データやサイロ化の問題を把握できます。また、後続の ETL/ELT 設計やメタデータ管理が効率化され、データ品質向上やセキュリティポリシー策定の基盤が整います。結果として、データ活用の透明性が高まり、組織全体の意思決定精度と運用効率が向上します。
デメリット:初期調査に多くの時間と人的リソースを要する場合があり、特に大規模組織では関係部署間の調整が複雑化します。また、動的に変化するシステム環境では、識別結果を継続的に更新しなければ情報が陳腐化するリスクがあります。十分なメタデータ管理体制が整っていない場合、成果物が形式的な一覧表に留まり、実運用に活用されない可能性もあります。
図例
1. ネットワークトラフィック分析の実装データソースの識別。

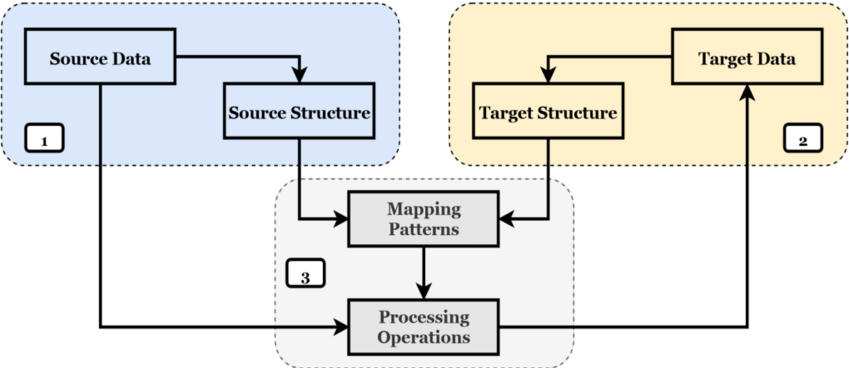
2. データ マッピング プロセス: ソースの識別、ターゲットの識別、およびマッピング パターンによる 2 つの構造のリンク。
関連記事
参考リンク
https://fastercapital.com/topics/identifying-data-sources-and-types.html/1