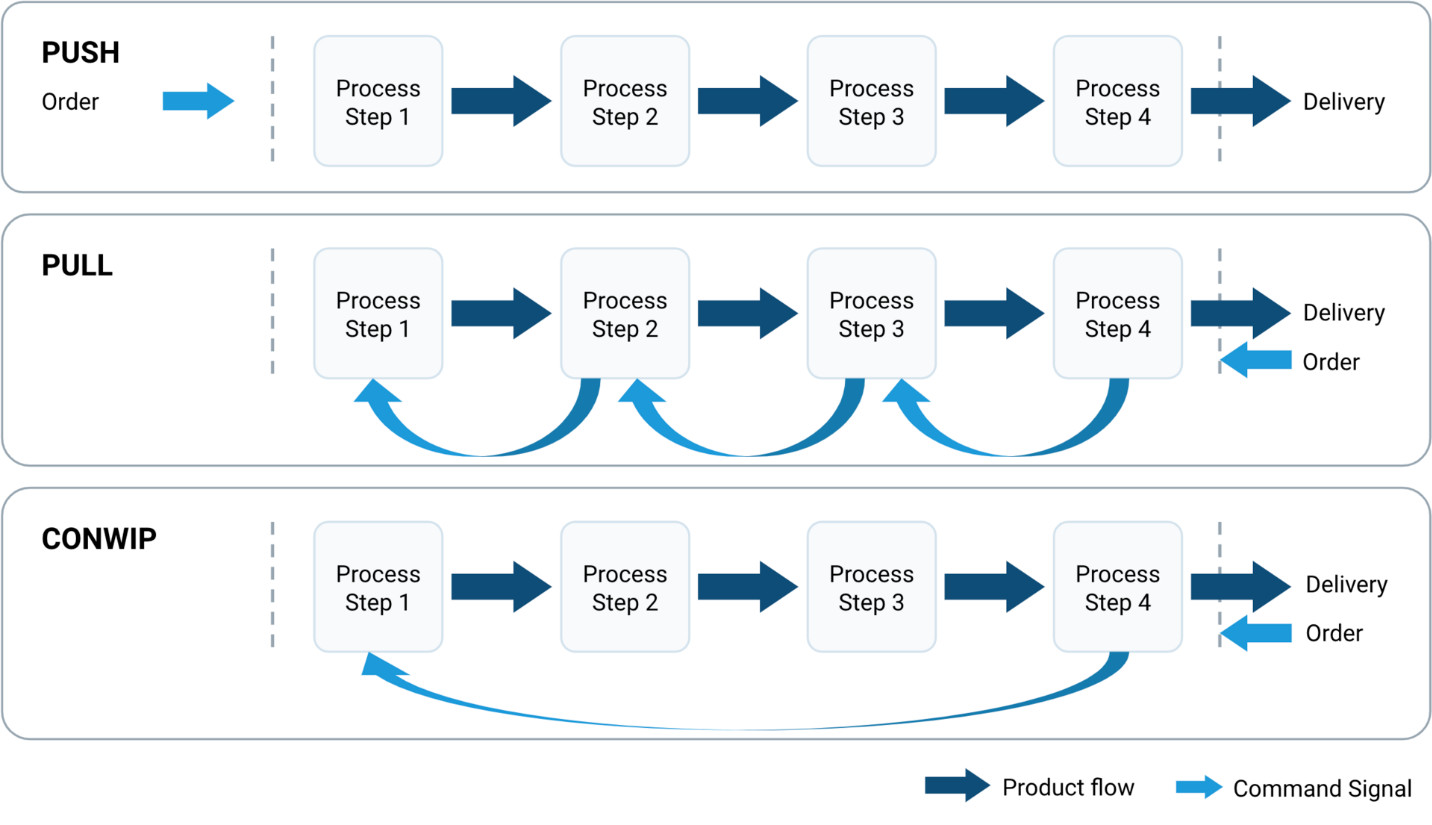
プッシュ・プルモデル(Push-Pull Model) | Webクローラ | ScrapeStorm
摘要:プッシュ・プルモデル(Push-Pull Model)は、システムコンポーネント間におけるデータ伝送メカニズムを記述するアーキテクチャパターンであり、データ生成者(ソース)とデータ消費者(ターゲット)との相互作用を定義します。Push モードでは、データソースがターゲットへ能動的にデータを送信します。一方、Pull モードでは、データ消費者がソースに対して能動的にデータを要求または取得します。実際のシステムでは、業務要件、ネットワーク状況、リアルタイム性の要求、システム負荷などに応じて両方式を動的または静的に組み合わせるハイブリッド方式、すなわち Push-Pull Model が採用されることが一般的です。これにより、データフローの効率性、信頼性、リソース利用率を最適化します。本モデルは、メッセージキューシステム、データ同期機構、ストリーム処理プラットフォーム、分散キャッシュ環境などで広く利用されています。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
プッシュ・プルモデル(Push-Pull Model)は、システムコンポーネント間におけるデータ伝送メカニズムを記述するアーキテクチャパターンであり、データ生成者(ソース)とデータ消費者(ターゲット)との相互作用を定義します。Push モードでは、データソースがターゲットへ能動的にデータを送信します。一方、Pull モードでは、データ消費者がソースに対して能動的にデータを要求または取得します。実際のシステムでは、業務要件、ネットワーク状況、リアルタイム性の要求、システム負荷などに応じて両方式を動的または静的に組み合わせるハイブリッド方式、すなわち Push-Pull Model が採用されることが一般的です。これにより、データフローの効率性、信頼性、リソース利用率を最適化します。本モデルは、メッセージキューシステム、データ同期機構、ストリーム処理プラットフォーム、分散キャッシュ環境などで広く利用されています。
適用シーン
Push-Pull Model は、異なるシステムコンポーネント間で効率的なデータ伝送を必要とするさまざまなアーキテクチャに広く適用されます。メッセージキューシステムでは、プロデューサーがキューへ Push し、コンシューマーが Pull によって処理を行うことで、疎結合化とピーク負荷の平準化を実現します。データ同期の場面では、ソースシステムが変更データを Push し、ターゲットシステムが定期的に全量データを Pull して整合性を検証します。ストリーム処理基盤では、データソースがリアルタイムストリームを継続的に Push し、処理エンジンが必要に応じてバッチデータを Pull してウィンドウ計算を行います。分散キャッシュ環境では、キャッシュノードが無効化通知を Push し、アプリケーションサーバーが最新データを Pull します。IoT 環境では、センサーがリアルタイム監視データを Push し、中央制御システムが履歴データを Pull してトレンド分析を行います。本モデルは、リアルタイム応答性とシステム負荷のバランスが求められる分散システム、処理能力が非対称な環境、不安定なネットワーク条件下での運用に特に適しています。
メリット:Push-Pull データモデルの最大の利点は、その高い柔軟性とリソース最適化能力にあります。Push モードは高リアルタイム性が求められる場面で迅速なデータ配信を可能にし、Pull モードはターゲット側の継続的ポーリングによる負荷や、ソース側の過負荷リスクを回避します。両方式を組み合わせることで、きめ細かな負荷管理が可能になります。また、本モデルはプロデューサーとコンシューマーの疎結合性を強化し、互いの内部状態を意識せずに独立して拡張・運用できます。耐障害性の面では、Pull モードはコンシューマー側の再開処理を支援し、Push モードは確認応答メカニズムと組み合わせることで信頼性の高い配信を実現します。さらに、ノード間の処理能力差、変動するネットワーク帯域、動的に変化する業務負荷といった異種環境にも適応可能であり、複雑な条件下でもデータ伝送の安定性と効率性を維持できます。
デメリット: Push-Pull Model の主な課題は、そのアーキテクチャ的複雑性に起因するシステム的リスクにあります。Push と Pull の両機構を同時に実装するには、高度な協調ロジック、状態管理、モード切替戦略の設計が必要となり、開発・運用コストが増大します。データ整合性の観点では、ハイブリッドモデルはデータ到着順序の乱れ、重複処理、タイミング競合といった問題が発生しやすく、バージョン管理や冪等性設計など追加的な対策が不可欠です。遅延特性の不確実性も顕著であり、Pull モードのポーリング間隔による遅延と、Push モードのネットワーク混雑時のバックログが重なることで、エンドツーエンド遅延の予測と最適化が困難になります。また、モード選択、状態同期、フロー制御に伴う追加通信オーバーヘッドが、高頻度通信環境では性能ボトルネックとなる可能性があります。さらに、多様化したデータフロー経路は問題特定や障害解析を複雑化させ、特に複数コンポーネントが関与するハイブリッド連鎖におけるデータ欠損や重複の追跡を困難にします。
図例
1. Push–Pull モデル。
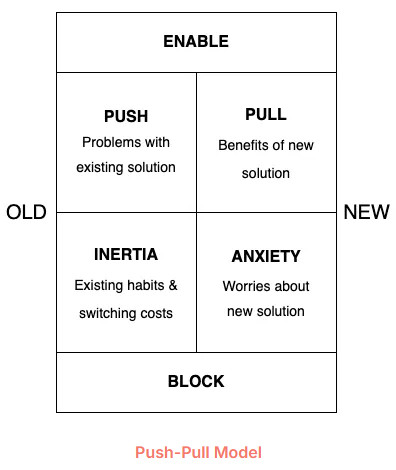
2. Push–Pull 戦略。