【フローチャートモード】画像をダウンロードする方法 | Webクローラ | ScrapeStorm
摘要:本文では、データをスクレイピング中の画像をダウンロードする方法を紹介します。プライミング必要なし、使いやすいです。 ScrapeStorm無料ダウンロード
Webスクレイピングに、E-コマースWebサイトの画像など、Webページの画像をスクレイピングする必要があります。 この時、イメージのダウンロード機能を使用する必要があります。
1.一つずつダウンロードする
ページでダウンロードする画像をクリックし、プロンプトに従って「要素を抽出する」をクリックします。 ScrapeStormは「データ抽出」コンポーネントを自動的に生成し、画像フィールドを追加します。 (フィールドのスクレイピングを続けると、ScrapeStormは毎回新しいコンポーネントを生成せず、新しいフィールドのみが追加されます。)
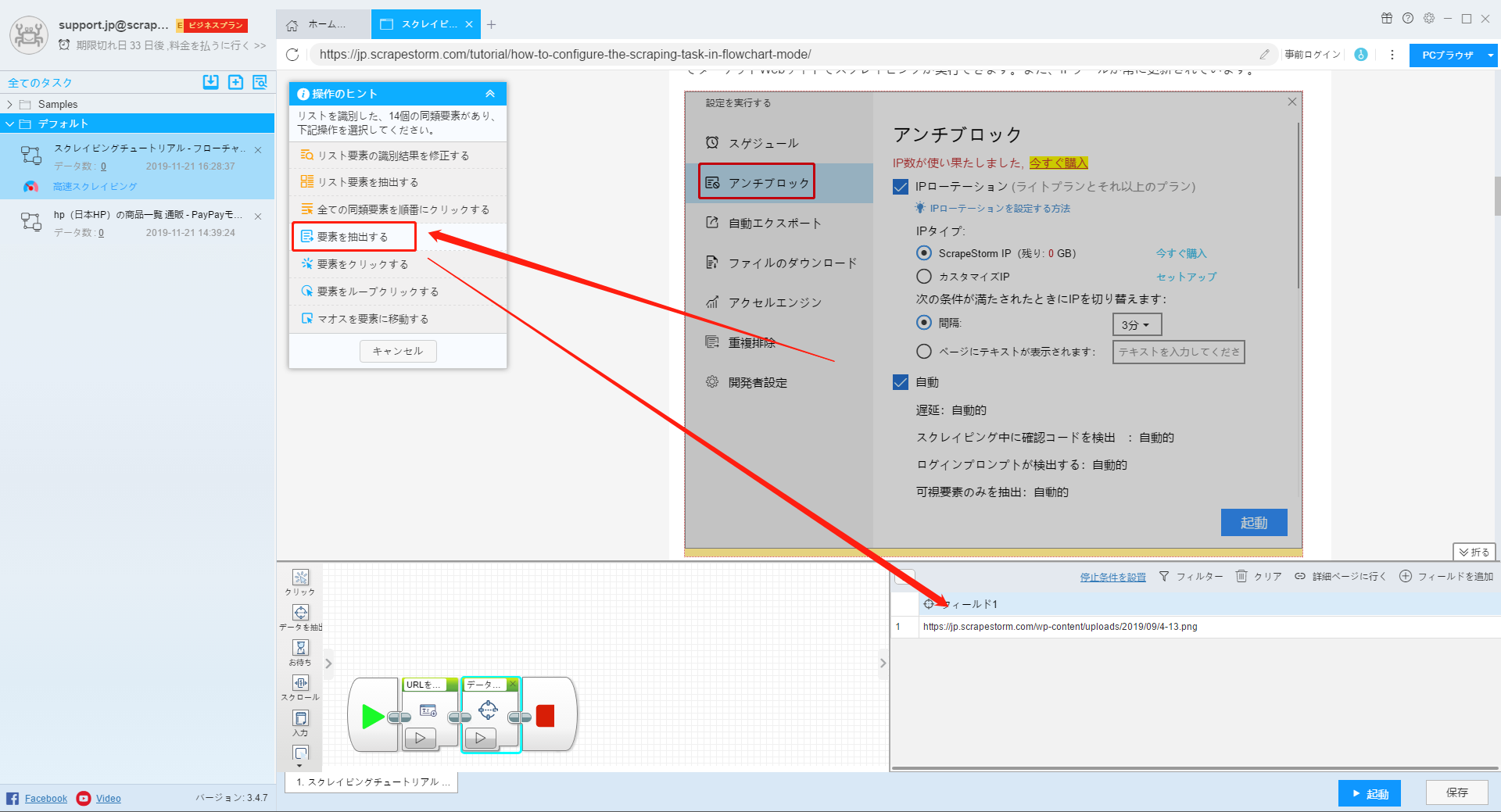
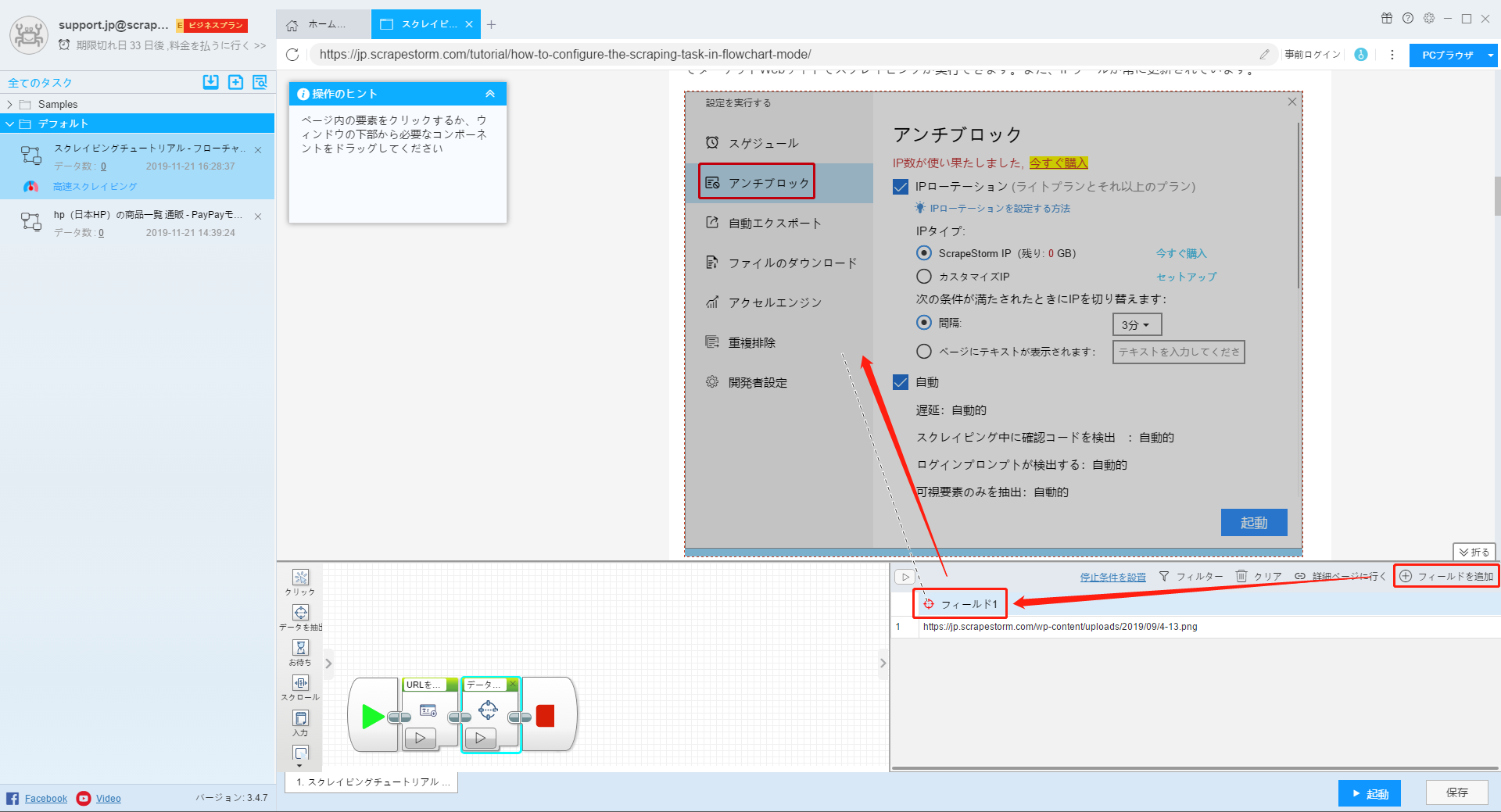
または、「フィールドを追加」をクリックして、ページでダウンロードする画像をクリックして選択します。
2.複数の画像をダウンロードする
この場合、写真をグループ化する必要があり、すべての写真を一度に選択できます。
画像領域全体を直接クリッククリックすると、ScrapeStormは黄色の選択領域が表示され、ダウンロードするすべての画像が選択されていることが確認できます。 次に、プロンプトに従って「要素を抽出する」をクリックすると、ScrapeStormは抽出されたデータコンポーネントを自動的に生成し、画像フィールドを追加します。

次に、フィールドを右クリックして、抽出タイプを「内部HTML」に変更します。
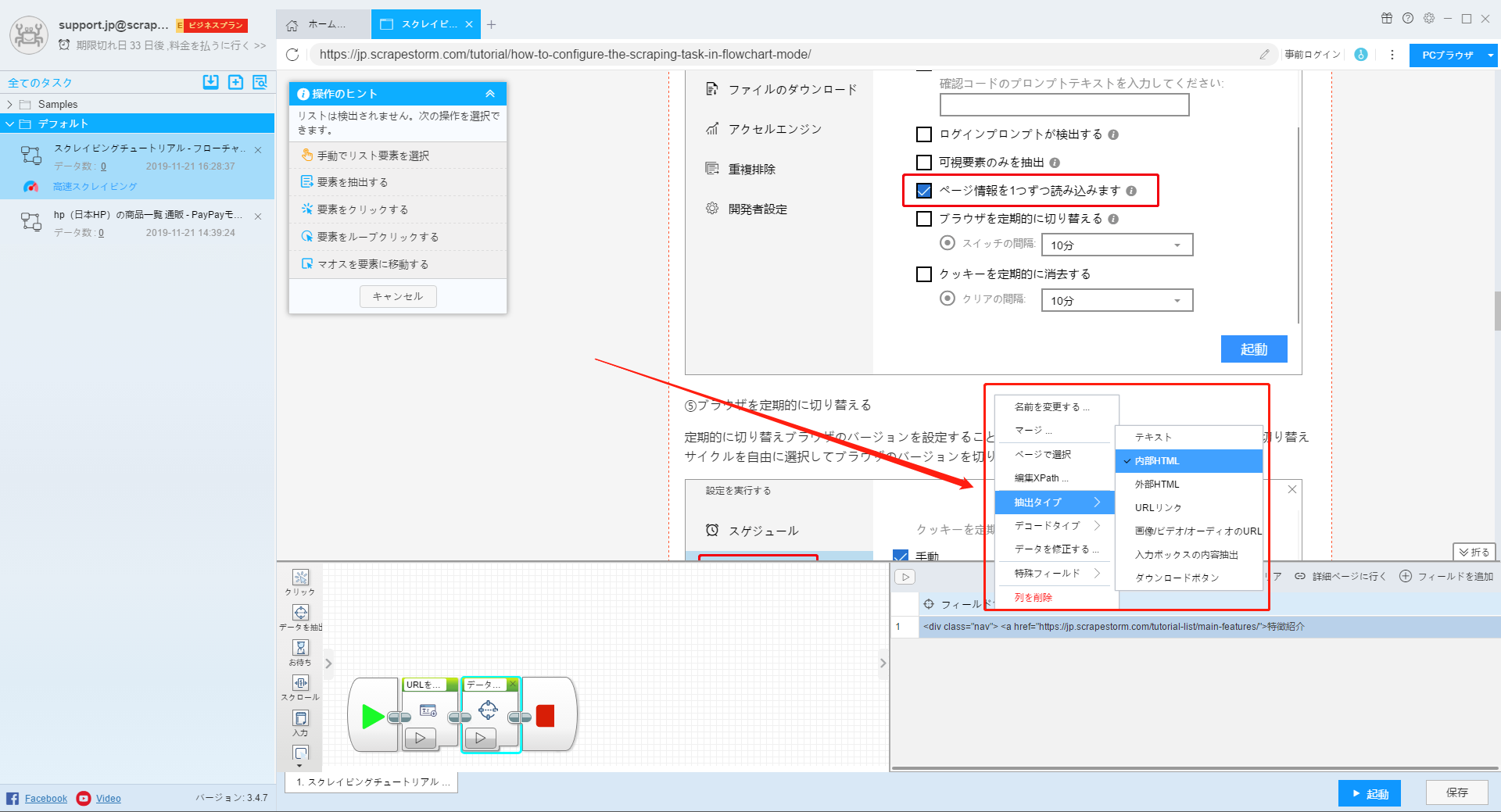
または、「フィールドの追加」をクリックし、ページ上の画像領域全体をクリックして、ダウンロードするすべての画像が選択されていることを確認します。
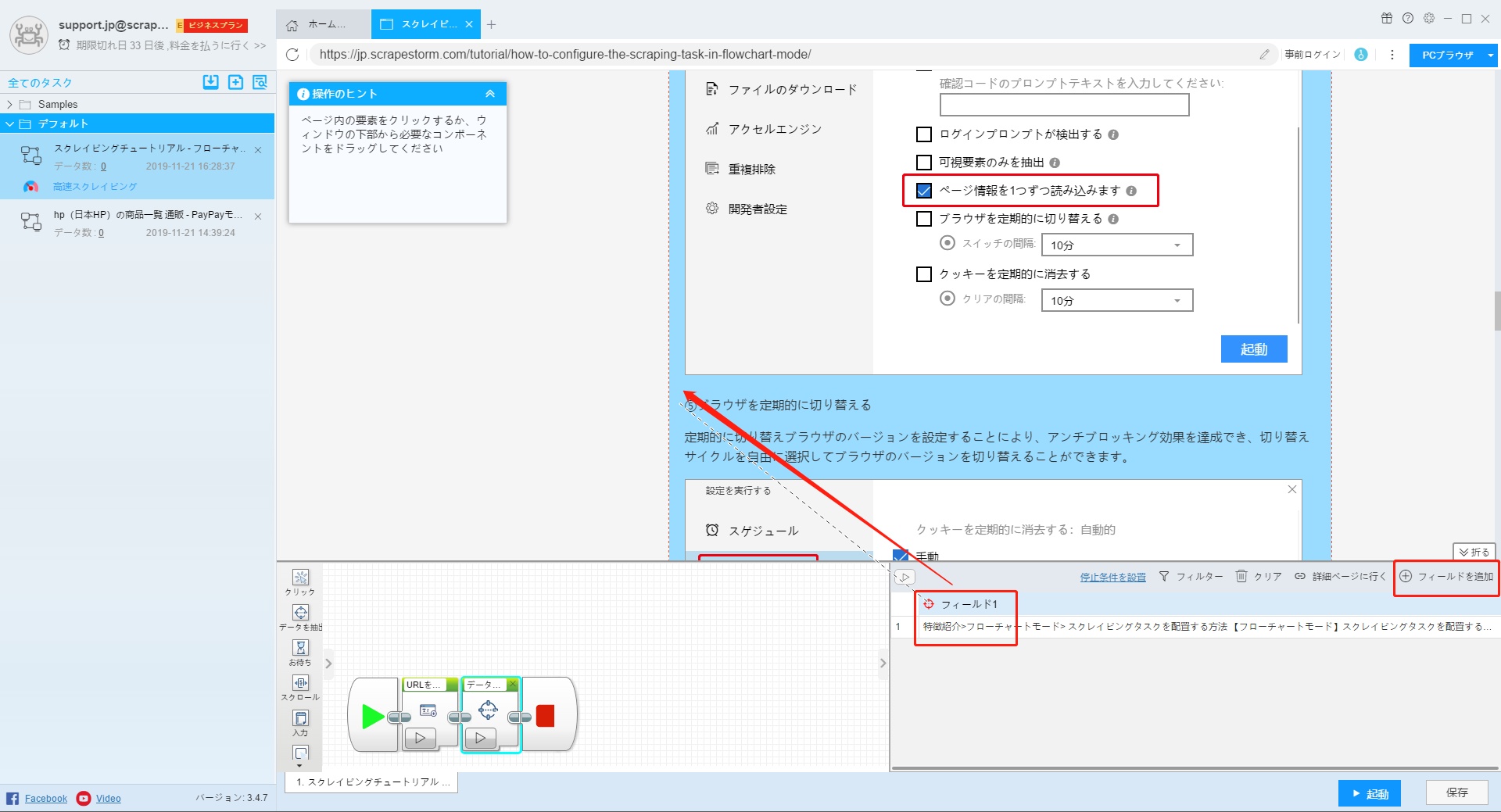
次に、フィールドを右クリックして、抽出タイプを「内部HTML」に変更します。
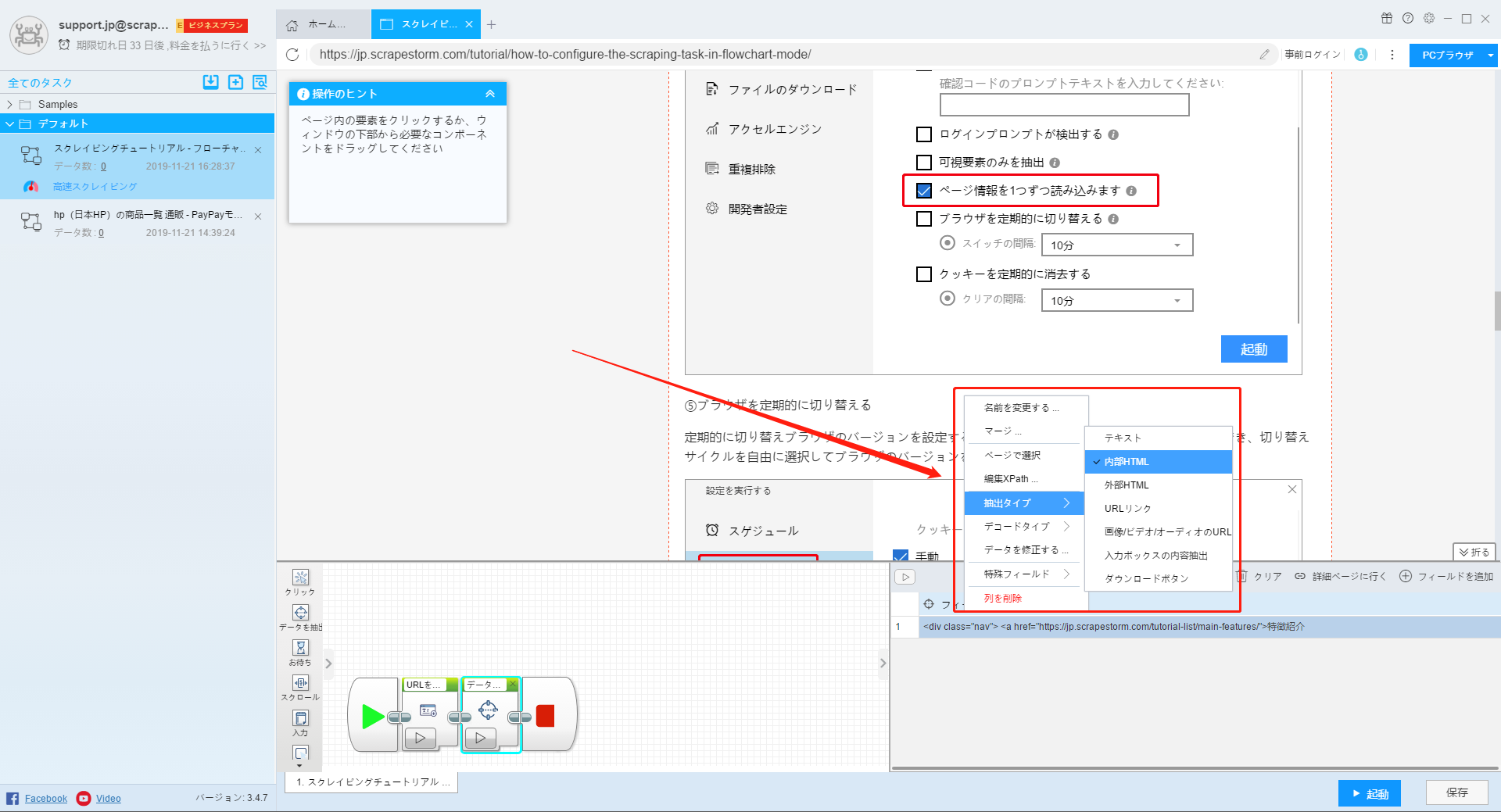
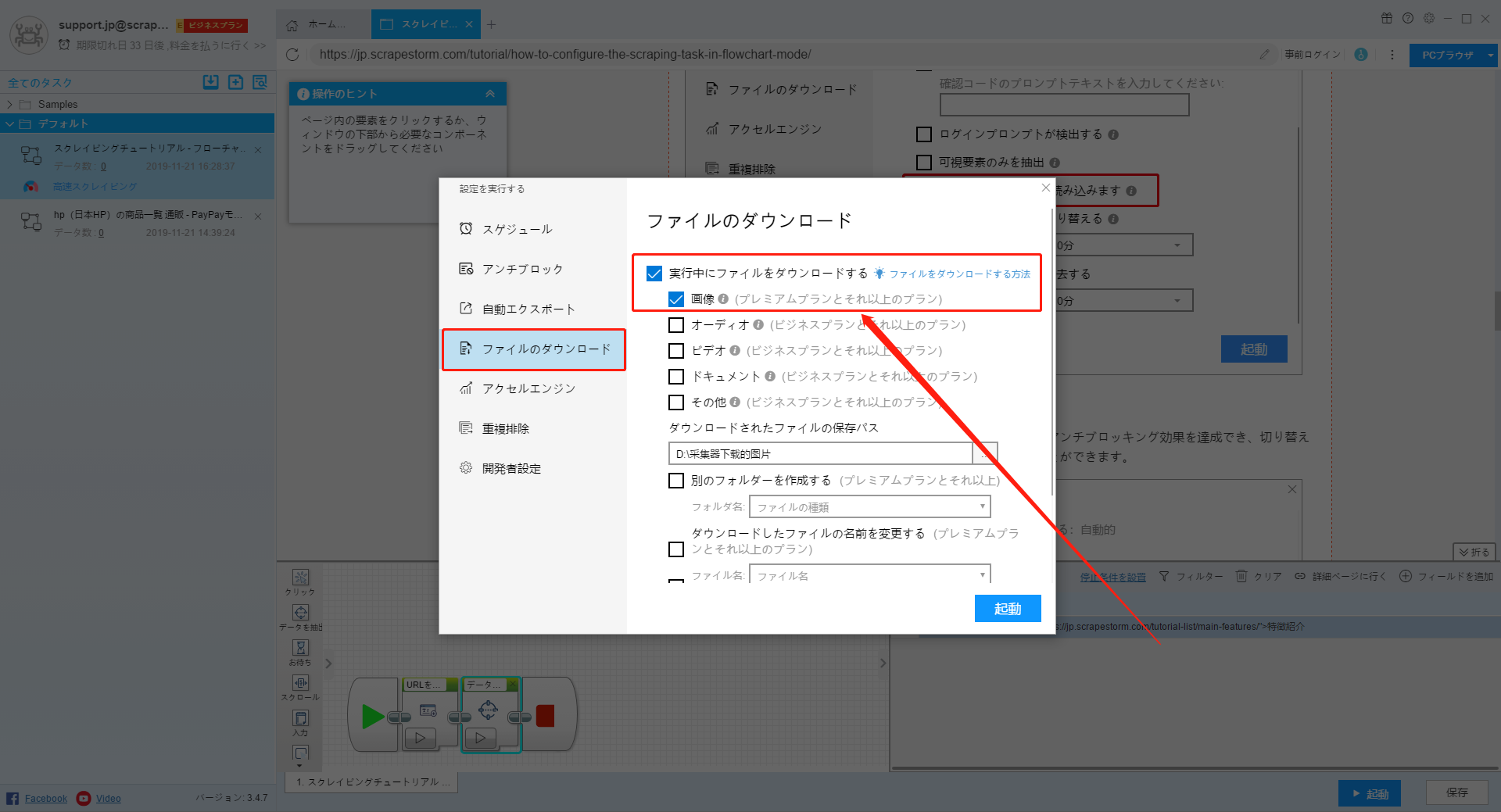
画像ダウンロード機能を設定するには、右下隅の「起動」アイコンをクリックして、起動ボックスに設定できます。
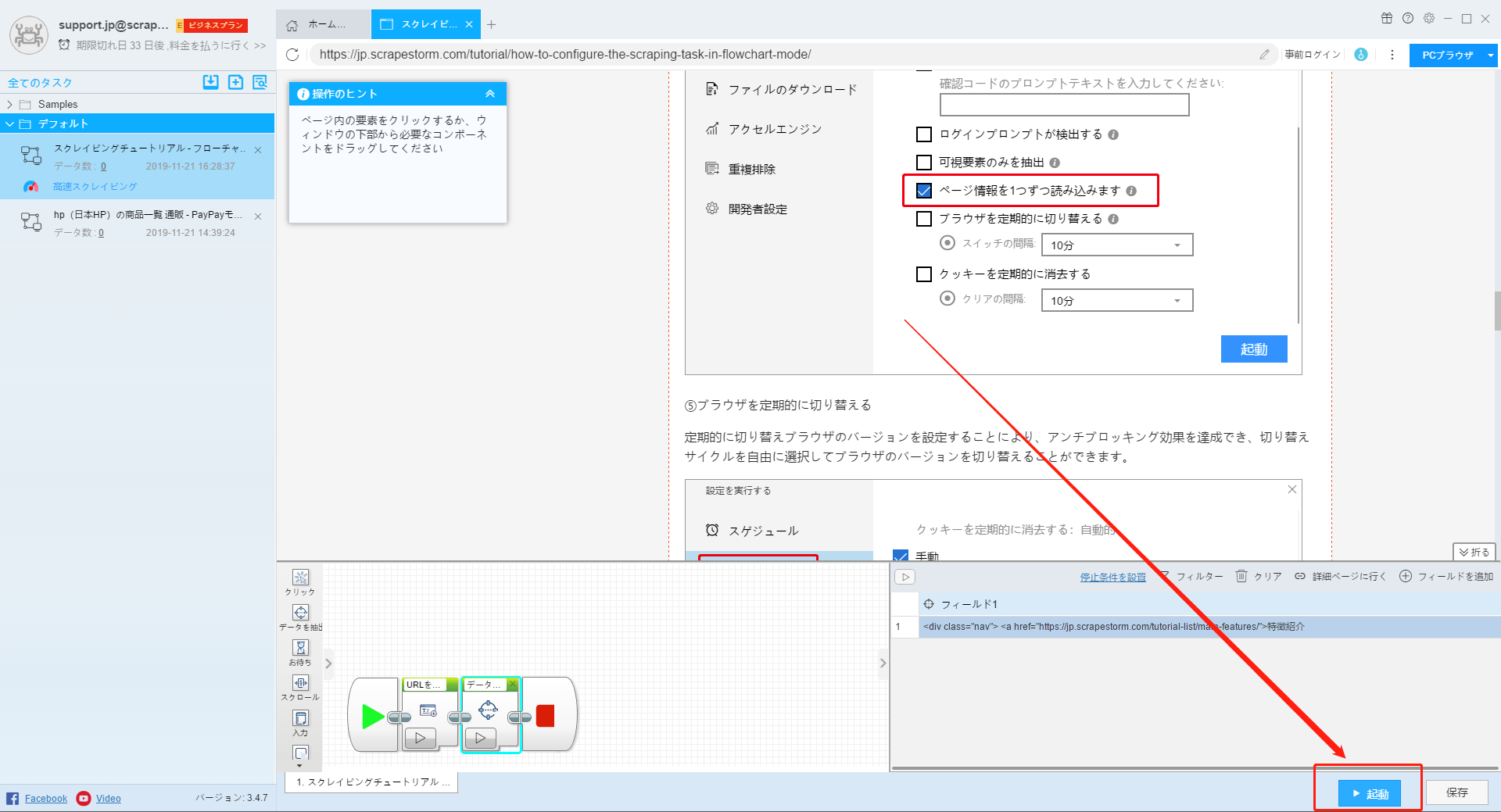
「実行中にファイルをダウンロード」および「画像」を選択して画像ダウンロード機能を開きます。画像のローカル保存パスを設定できます。