データインジェスト(データ取り込み、Data Ingestion) | Webクローラ | ScrapeStorm
摘要:Data Ingestion(データインジェスチョン)とは、さまざまなデータソースからデータを収集し、分析や処理が可能なシステムへ取り込むプロセスを指します。企業のデータ基盤において最初の重要なステップであり、データベース、ログファイル、IoTデバイス、クラウドサービス、外部APIなど多様なソースからデータを取得し、データレイクやデータウェアハウスへ転送します。例えば、Apache Kafka や Apache NiFi、Azure Data Factory などのツールは、データインジェスチョンを効率的に実行するための代表的なプラットフォームです。これらの技術により、企業はリアルタイムまたはバッチ形式でデータを収集し、ビッグデータ分析、機械学習、ビジネスインテリジェンスなどに活用するための基盤を構築できます。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
Data Ingestion(データインジェスチョン)とは、さまざまなデータソースからデータを収集し、分析や処理が可能なシステムへ取り込むプロセスを指します。企業のデータ基盤において最初の重要なステップであり、データベース、ログファイル、IoTデバイス、クラウドサービス、外部APIなど多様なソースからデータを取得し、データレイクやデータウェアハウスへ転送します。例えば、Apache Kafka や Apache NiFi、Azure Data Factory などのツールは、データインジェスチョンを効率的に実行するための代表的なプラットフォームです。これらの技術により、企業はリアルタイムまたはバッチ形式でデータを収集し、ビッグデータ分析、機械学習、ビジネスインテリジェンスなどに活用するための基盤を構築できます。
適用シーン
Data Ingestion は、ビッグデータ分析、リアルタイムデータ処理、IoTプラットフォーム、データウェアハウス構築など、データ駆動型のシステムで広く利用されています。例えば、ECサイトではユーザーのクリックログ、購買履歴、検索履歴などをリアルタイムに収集し、顧客行動分析やレコメンドシステムに利用します。物流業界では、車両のGPSデータやセンサー情報を継続的に取り込み、運行状況の監視やルート最適化に役立てることができます。また、スマートシティやIoT環境では、センサーや監視装置から送信される大量のストリームデータを取り込み、交通管理、環境監視、設備管理などの分析基盤として活用されます。さらに、企業のデータ統合プロジェクトでは、複数の業務システムやクラウドサービスからデータを収集し、統合データプラットフォームを構築する際の中核的なプロセスとなります。
メリット:Data Ingestion の最大の利点は、異なるデータソースからデータを統合し、分析や意思決定のための共通基盤を構築できる点です。リアルタイムストリーミングやバッチ処理の両方に対応することで、企業は即時性の高いデータ分析と長期的なデータ蓄積を同時に実現できます。また、スケーラブルなデータパイプラインを構築することで、大量データの処理にも柔軟に対応できます。さらに、データ品質チェックやフォーマット変換などの処理を取り込み段階で実施することで、後続の分析プロセスの効率化やデータ品質の向上にも寄与します。
デメリット:Data Ingestion の導入には、データパイプライン設計やシステム統合などの専門知識が必要であり、初期構築に一定のコストと技術リソースが求められます。また、多数のデータソースを扱う場合、フォーマットの違いやデータ品質の問題に対応するための追加処理が必要になることがあります。さらに、リアルタイムデータ処理ではインフラの負荷や運用コストが増加する可能性があり、適切なスケーリング設計が不可欠です。加えて、データの収集段階でセキュリティやプライバシー管理を十分に行わないと、データ漏洩やコンプライアンス違反のリスクが生じる可能性があります。
図例
1. データ取り込みは、データが発生する運用プレーンと、データがAIモデル、ダッシュボード、APIなどの分析製品に変換される分析プレーンとの間の重要なリンクとして機能します。
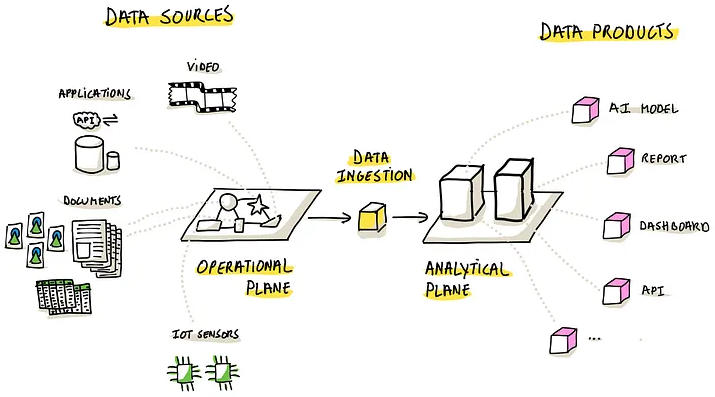
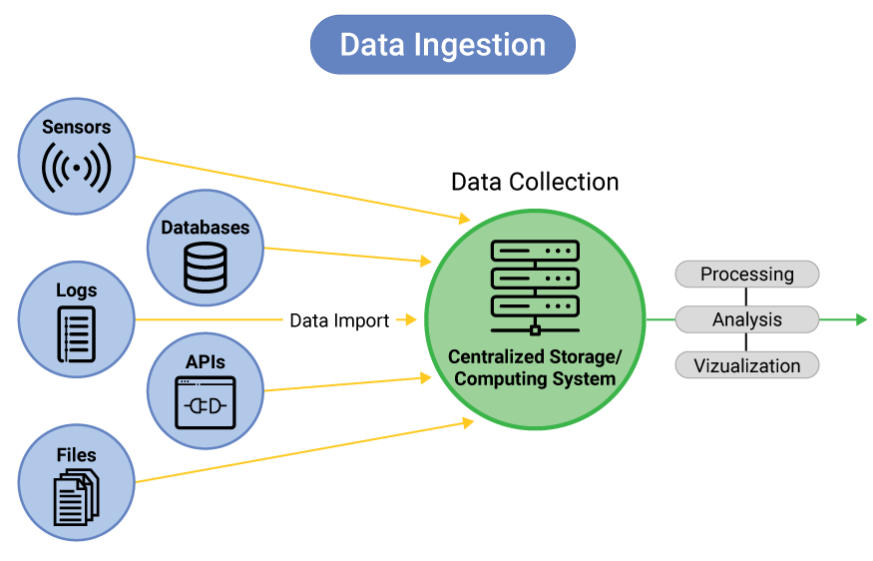
2. データインジェスト。
関連記事
参考リンク
https://www.scylladb.com/glossary/data-ingestion/
https://www.geeksforgeeks.org/big-data/what-is-data-ingestion/