ディープクロール(Deep Crawling) | Webクローラ | ScrapeStorm
摘要:Deep Crawling(ディープクロール)とは、Webクローラーが対象サイトのトップページや表層ページのみを収集するのではなく、ページ内のリンクを再帰的にたどりながら、サイトのより深い階層にあるページへ継続的にアクセスしてデータを収集する技術手法を指します。浅いクロール(シャロークロール)が表層ページのみを取得するのに対し、ディープクロールはサイトのディレクトリ構造、ページネーション、カテゴリリンク、さらには動的に読み込まれるコンテンツなどを追跡することで、より包括的かつ完全なデータを取得できます。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
Deep Crawling(ディープクロール)とは、Webクローラーが対象サイトのトップページや表層ページのみを収集するのではなく、ページ内のリンクを再帰的にたどりながら、サイトのより深い階層にあるページへ継続的にアクセスしてデータを収集する技術手法を指します。浅いクロール(シャロークロール)が表層ページのみを取得するのに対し、ディープクロールはサイトのディレクトリ構造、ページネーション、カテゴリリンク、さらには動的に読み込まれるコンテンツなどを追跡することで、より包括的かつ完全なデータを取得できます。
適用シーン
Deep Crawling は、検索エンジンのインデックス構築、ビッグデータ分析、市場インテリジェンス収集、学術研究、垂直分野のデータ集約などの場面で広く利用されています。検索エンジン分野では、ディープクロールはWebページのインデックス構築や検索結果の網羅性・更新性を高めるための重要な技術です。例えば、Google Search や Bing などの検索サービスでは、大規模なクローリングシステムによってWeb全体の情報を収集しています。
メリット:Deep Crawling の最大の利点は、表層リンクからは取得できない深層データを取得できる点にあります。Webサイトの多階層ページ構造を再帰的に探索することで、ページネーション、フィルタリング、関連リンクなどの仕組みの背後にある豊富な情報を発見でき、データ収集の完全性とカバレッジを大幅に向上させます。
デメリット:Deep Crawling の実装にはいくつかの課題や制約が存在します。まず、ディープクロールは対象サイトのサーバーに大きなアクセス負荷を与える可能性があり、適切なアクセス頻度制御を行わない場合、IPブロックやCAPTCHA認証などのアンチスクレイピング対策を引き起こす可能性があります。また、クロールの深度が増すにつれてページ数が指数的に増加するため、リンクの重複排除、タスクスケジューリング、データ保存管理などにおいて高いシステム複雑性と計算資源が必要になります。
図例
1. 標準的なWebクローラーの高レベルアーキテクチャ。
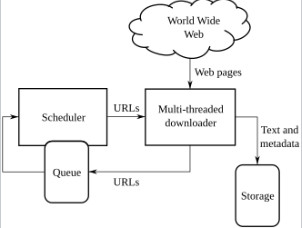
2. Deep Crawling(ディープクロール)。