アンチスクレイピング技術 | Webクローラ | ScrapeStorm
摘要:アンチスクレイピング(Anti-scrapingtechniques)は、自動化されたスクレイピング (通常はスクレイピング ロボットまたはスクレイピングソフトウェア) から Web サイトおよびオンライン データ リソースを保護するために使用されるテクノロジーおよび方法です。 これらのメカニズムの目的は、Web サイトの正当なユーザーが通常どおりに Web サイトにアクセスして使用できるようにすると同時に、プライバシー、データ セキュリティ、ネットワーク パフォーマンスを保護するために不正なデータ収集を制限または防止することです。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
アンチスクレイピング(Anti-scrapingtechniques)は、自動化されたスクレイピング (通常はスクレイピング ロボットまたはスクレイピングソフトウェア) から Web サイトおよびオンライン データ リソースを保護するために使用されるテクノロジーおよび方法です。 これらのメカニズムの目的は、Web サイトの正当なユーザーが通常どおりに Web サイトにアクセスして使用できるようにすると同時に、プライバシー、データ セキュリティ、ネットワーク パフォーマンスを保護するために不正なデータ収集を制限または防止することです。

適用シーン
Web サイトは多くの場合、違法なデータ収集やコンテンツの盗難を防ぐためにコンテンツとデータを保護したいと考えています。 アンチクロール メカニズムを使用すると、悪意のあるスクレイピングが Web サイト データにアクセスするのを防ぐことができます。 実際、データとリソースの保護を必要とするほとんどすべてのオンライン アクティビティには、アンチクローラー メカニズムが使用される可能性があります。 これらは、データの整合性を維持し、プライバシーを保護し、悪用を減らし、ネットワークの適切な機能を確保するのに役立ちます。
メリット:スクレイピング対策メカニズムは、Web サイトがデータ、コンテンツ、リソースを不正なクロールや悪用から保護するのに役立ちます。 スクレイピングのアクセスを制御・削減することでサーバーの負荷を軽減し、Webサイトのパフォーマンスや応答速度を向上させることができます。 競争の激しい市場では、クロール防止メカニズムは、価格情報や顧客データのスクレイピングなど、競合他社による不公平な行為を減らすのにも役立ちます。
デメリット:スクレイピング対策メカニズムは、通常のユーザーを悪意のあるクローラーと誤って判断する場合があり、正規のユーザーが制限され、ユーザー エクスペリエンスに影響を与えます。 検索エンジンスクレイピングなどの一部の正規のスクレイピングも、アンチスクレイピングメカニズムの影響を受ける可能性があり、特別な処理が必要になります。
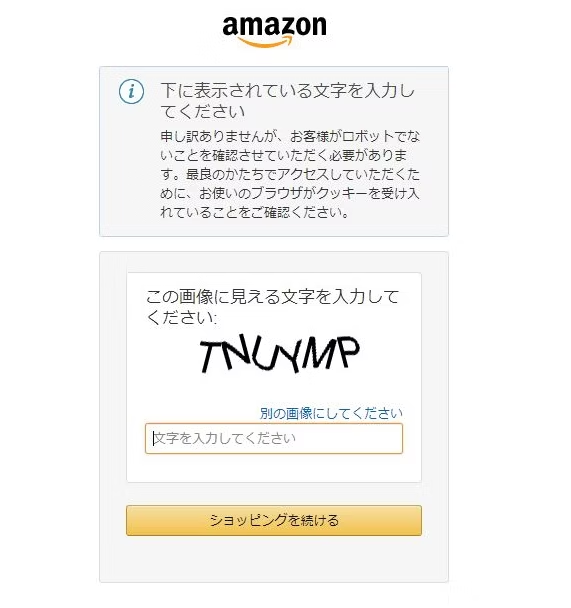
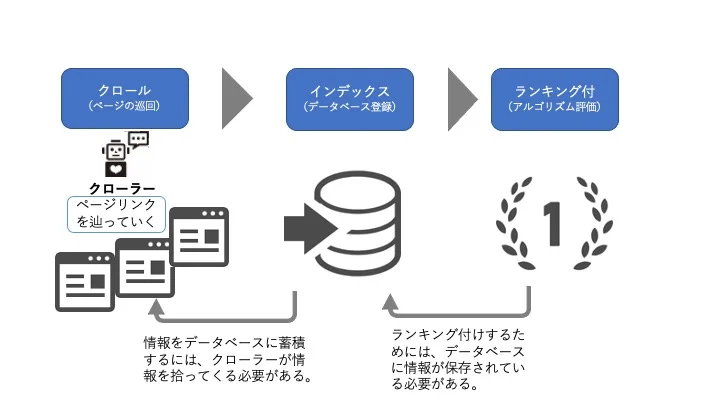
図例
1. 検索順位表示の仕組み。
2. サイト側も情報を取られたくないので、こういった外部からの機械的なアクセスを遮断するための対策を講じています。