データエンジニア(Data Engineer) | Webクローラ | ScrapeStorm
摘要:データエンジニアは、大量のデータを効率的に収集、処理、保存、管理するためのシステムとパイプラインを設計・構築・運用する専門家です。データサイエンティストやアナリストが分析や機械学習を行うために必要な基盤を整備する役割を担います。データエンジニアは、データの品質、可用性、信頼性を確保しながら、データフローの最適化と自動化を実現します。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データエンジニアは、大量のデータを効率的に収集、処理、保存、管理するためのシステムとパイプラインを設計・構築・運用する専門家です。データサイエンティストやアナリストが分析や機械学習を行うために必要な基盤を整備する役割を担います。データエンジニアは、データの品質、可用性、信頼性を確保しながら、データフローの最適化と自動化を実現します。
適用シーン
EコマースやSNSなどで生成される大量のユーザーデータをリアルタイムで収集・処理し、顧客行動分析やレコメンドエンジンに活用します。機械学習チームと連携し、モデル学習に必要なクリーンデータを定期的に供給するデータパイプラインを構築します。センサーから送信されるリアルタイムデータを収集し、異常検知や運用モニタリングに活用します。
メリット:データエンジニアは、パイプラインを自動化することで、膨大なデータ処理を高速かつ効率的に実行します。これにより、リアルタイム分析やバッチ処理のスピードが向上します。重複や欠損データを自動的に検出・修正し、高品質なデータセットを維持することで、分析や予測モデルの精度が向上します。分散処理やクラウド技術を活用することで、大規模なデータフローにも対応可能です。データ量の増加に対して柔軟にスケールアップできます。
デメリット:分散処理やクラウド基盤を活用する場合、インフラコストや運用コストが高くなることがあります。データエンジニアリングには、プログラミング、データベース設計、ETL、分散処理など多様な技術スキルが求められます。そのため、習得までに時間と経験が必要です。データパイプラインでエラーが発生すると、原因特定や復旧に時間がかかることがあります。データ整合性の問題にも対応が必要です。大量の機密データを扱うため、適切なアクセス制御や暗号化対策が必須です。不備があるとデータ漏洩のリスクがあります。
図例
- データエンジニアの役割。
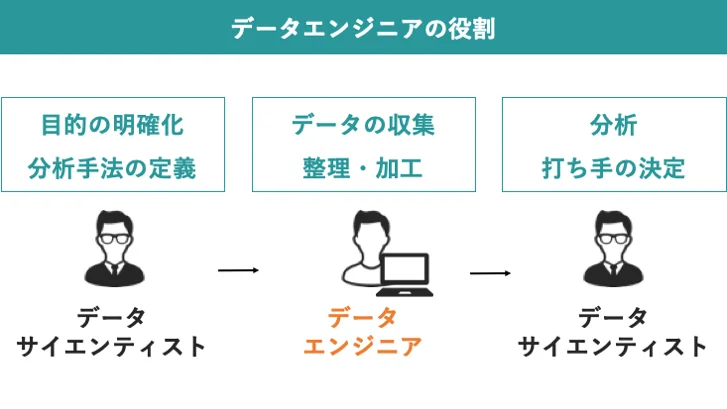
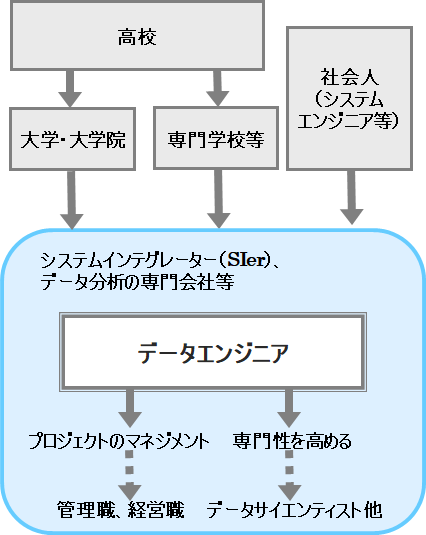
2. データエンジニア – 職業詳細。
関連記事
参考リンク
https://kuroco.team/blog-data-engineer-20221007/