データフィルタリング(Data Filtering) | Webクローラ | ScrapeStorm
摘要:データフィルタリングは、データセットから特定の条件に合致するデータを抽出したり、不要なデータを除外したりするプロセスです。このプロセスは、データ分析や機械学習の前処理として広く使用され、データの精度や効率性を向上させるために重要です。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データフィルタリングは、データセットから特定の条件に合致するデータを抽出したり、不要なデータを除外したりするプロセスです。このプロセスは、データ分析や機械学習の前処理として広く使用され、データの精度や効率性を向上させるために重要です。
適用シーン
不正確、重複、欠損データを除去して、データの質を向上させる。特定の顧客セグメントに焦点を当て、ターゲットを絞ったマーケティング戦略を立てる。IoTセンサーからのデータをフィルタリングして、特定の条件を満たすイベントのみを検出し、対応する。通常の範囲から外れるデータポイントを抽出し、異常な挙動を識別する。
メリット:ノイズや不適切なデータを排除することで、分析結果やモデルの精度が向上します。大量のデータから必要な情報だけを抽出することで、計算リソースの使用を最適化し、処理時間を短縮できます。特定の条件に基づいたデータを抽出することで、分析をより的確にターゲティングできる。
デメリット:フィルタリングによって有用な情報が失われるリスクがあります。特に、条件設定が厳しすぎる場合、重要なデータが除外される可能性があります。特定の条件に基づいてデータを選別することで、データにバイアスがかかる可能性があります。これにより、分析結果やモデルが偏ったものになることがあります。複雑な条件でフィルタリングを行うと、計算コストや時間が増大する可能性があります。
図例
1. フィルタリングで安心インターネット。
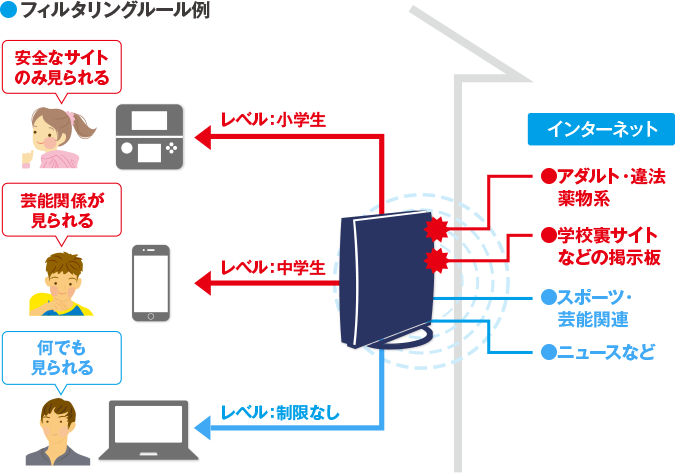
2. データフィルター機能。