データレイク (Data Lake) | Webクローラ | ScrapeStorm
摘要:データレイク(Data Lake)とは、構造化データ、半構造化データ、非構造化データなど、あらゆる形式のデータをそのままの形で大量に保存できる一元的なリポジトリを指します。データを事前に整形・変換することなく蓄積し、必要に応じて分析や処理を行うことが可能です。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データレイク(Data Lake)とは、構造化データ、半構造化データ、非構造化データなど、あらゆる形式のデータをそのままの形で大量に保存できる一元的なリポジトリを指します。データを事前に整形・変換することなく蓄積し、必要に応じて分析や処理を行うことが可能です。
適用シーン
多様なデータソースから大量のデータを収集し、データレイクに保存することで、機械学習や高度な分析を通じてビジネスインサイトを得ることができます。データサイエンティストは、データレイクに蓄積された生データを活用して、新たなモデルの開発やアルゴリズムのトレーニングを行うことができます。IoTデバイスやソーシャルメディアなどからリアルタイムで生成されるデータをデータレイクに取り込み、即時の分析や意思決定に役立てることが可能です。
メリット:データをそのままの形式で保存できるため、事前のスキーマ設計やデータ変換が不要で、多様なデータタイプに対応できます。大規模なデータを効率的に保存・処理できるため、データ量の増加にも柔軟に対応できます。従来のデータウェアハウスと比較して、低コストで大容量のデータを保存できるストレージソリューションを活用できます。
デメリット:生データをそのまま保存するため、データの品質や一貫性を確保するための適切な管理とガバナンスが必要です。構造化されていないデータが多いため、必要な情報を効率的に検索・抽出するための高度なメタデータ管理や検索ツールが求められます。多様なデータ形式や分析手法に対応するため、データサイエンスやエンジニアリングの専門知識が必要となる場合があります。
図例
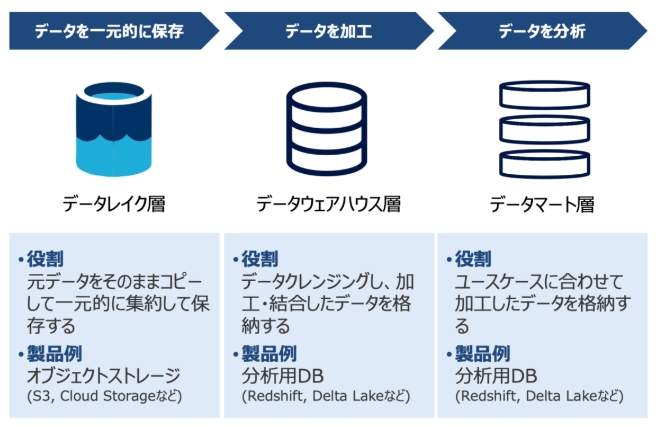
1. データ基盤の三層構造。
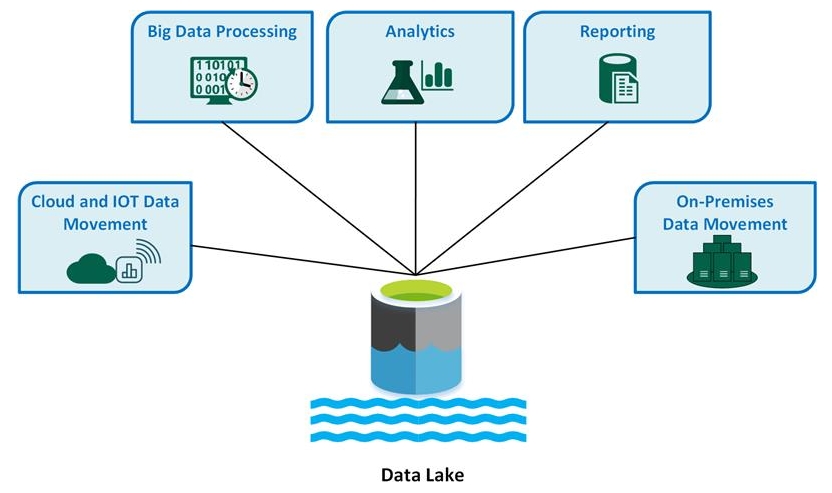
2. データレイク。
関連記事
参考リンク
https://learn.microsoft.com/ja-jp/azure/architecture/data-guide/scenarios/data-lake
https://ktksq.hatenablog.com/entry/datalake
https://ja.wikipedia.org/wiki/%E3%83%87%E3%83%BC%E3%82%BF%E3%83%AC%E3%82%A4%E3%82%AF