データマイニングアルゴリズム (Data Mining Algorithms) | Webクローラ | ScrapeStorm
摘要:データマイニングアルゴリズム(Data Mining Algorithms)は、大量のデータから有用なパターンや知識を自動的に抽出するための技術であり、統計学、機械学習、人工知能などの分野と密接に関連しています。代表的なアルゴリズムとしては、分類(例:決定木、サポートベクターマシン)、クラスタリング(例:K-means、階層型クラスタリング)、アソシエーション分析(例:Apriori、FP-Growth)、回帰分析、異常検知などが挙げられます。これらはすべて、与えられたデータの中から人間が気づきにくい法則や傾向を発見することを目的としています。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データマイニングアルゴリズム(Data Mining Algorithms)は、大量のデータから有用なパターンや知識を自動的に抽出するための技術であり、統計学、機械学習、人工知能などの分野と密接に関連しています。代表的なアルゴリズムとしては、分類(例:決定木、サポートベクターマシン)、クラスタリング(例:K-means、階層型クラスタリング)、アソシエーション分析(例:Apriori、FP-Growth)、回帰分析、異常検知などが挙げられます。これらはすべて、与えられたデータの中から人間が気づきにくい法則や傾向を発見することを目的としています。
適用シーン
データマイニングはさまざまな場面で活用されています。例えば、マーケティング分野では顧客の購買傾向や離脱予測を行い、ターゲット広告や販促戦略に反映させることができます。製造業では設備の故障予測や品質異常の発見に応用され、医療分野では診断支援や病気の早期予測に使われています。また、金融業界では不正取引の検出や信用リスク評価などにも広く用いられています。これらのアルゴリズムは、単に分析を高速化するだけでなく、ビジネス上の意思決定をよりデータドリブンにし、競争力の強化に直結する重要なツールとなっています。
メリット:データマイニングアルゴリズムは人間の直感では把握しにくい膨大なデータ内の複雑な相関関係を発見する能力に優れており、予測精度の高いモデルを構築できることが挙げられます。また、自動化により繰り返しの分析作業を効率化し、ビッグデータ時代における大量データの処理を可能にします。
デメリット:アルゴリズムの選択やパラメータ調整が適切でない場合、過学習や過小評価につながり、誤った結論を導くリスクがあります。また、学習には高性能な計算資源が必要となることがあり、実装や保守の難易度も高い傾向にあります。さらに、得られた結果が必ずしも因果関係を示すわけではないため、人間の解釈力やドメイン知識と組み合わせた慎重な運用が求められます。
図例
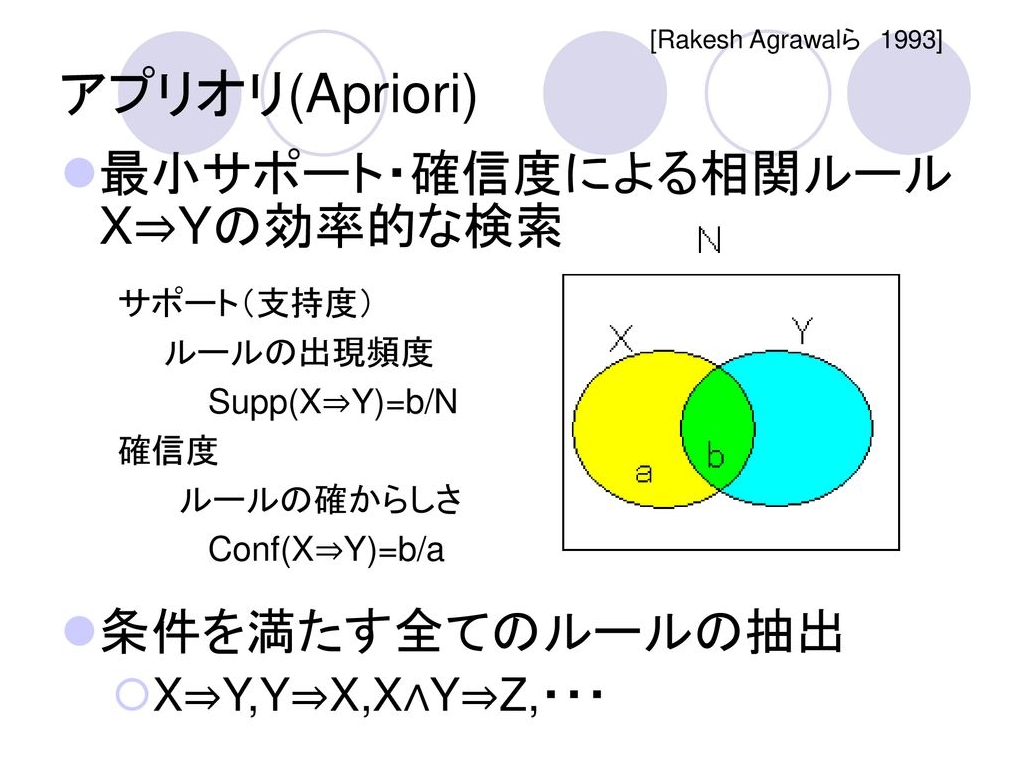
1. データマイニングアルゴリズムーーアプリオリ。
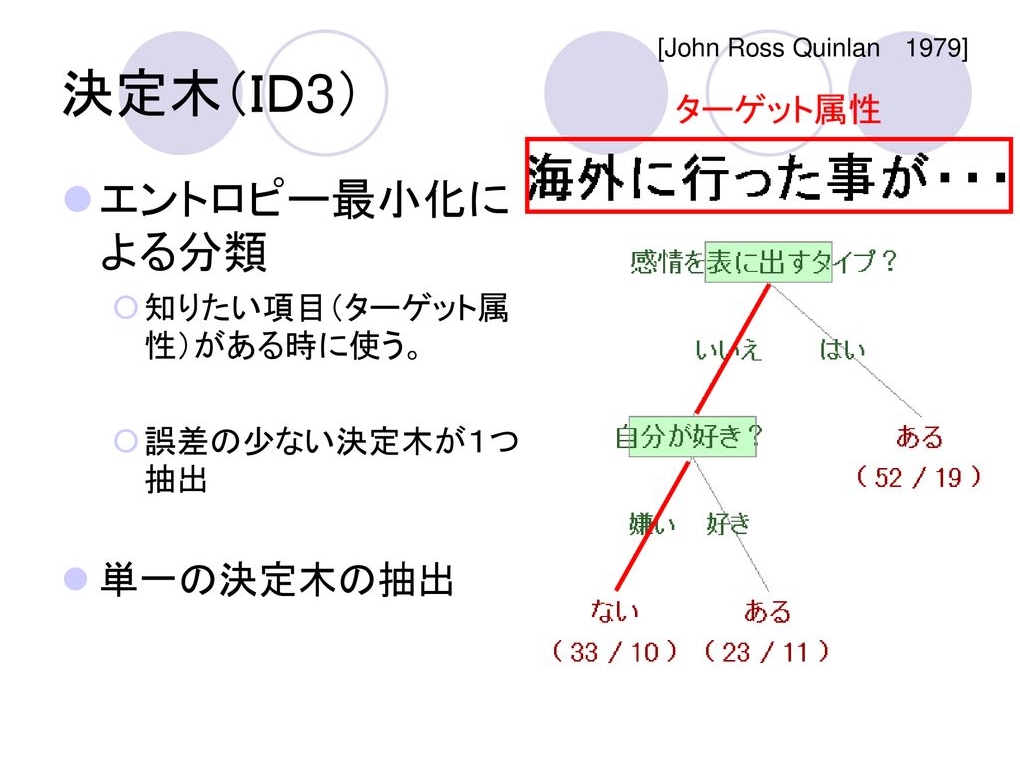
2.データマイニングアルゴリズムーーID3。