Webスクレイピング | Webクローラ | ScrapeStorm
摘要:Web スクレイピングは、通常は自動化されたプログラムを通じて、インターネットから情報やデータを取得するプロセスです。 これらのプログラムは Web クローラーまたは Web ロボットと呼ばれ、Web を閲覧し、情報を抽出して保存したり、さらに処理したりします。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
Web スクレイピングは、通常は自動化されたプログラムを通じて、インターネットから情報やデータを取得するプロセスです。 これらのプログラムは Web クローラーまたは Web ロボットと呼ばれ、Web を閲覧し、情報を抽出して保存したり、さらに処理したりします。

適用シーン
Webスクレイピングは、インターネットから情報を取得するために使用されるテクノロジーであり、データマイニング、競争力のあるインテリジェンス、コンテンツ集約、価格比較、検索エンジンの最適化、ソーシャルメディア分析、世論監視、ナレッジグラフの構築などの分野で広く使用されています。自動化タスク。 Web スクレイピングは、Web ページからの情報の抽出、分析、保存を自動化することで、ユーザーがさまざまな意思決定やイノベーションをサポートするために必要なデータを取得できるようにします。
メリット:Web スクレイピングの利点は、高度に自動化されており、リアルタイムでデータを更新でき、大規模な情報を処理でき、高度にカスタマイズ可能であり、Web データから API やソーシャル メディアに至るまで、さまざまなデータ ソースに適していることです。 これにより、データ取得の効率と柔軟性が向上し、データ変更のリアルタイム追跡が必要なアプリケーションに特に適しており、手動操作の負担が軽減されます。
デメリット:Web スクレイピングの欠点には、不安定なデータ品質、法的および倫理的な問題の可能性、Web サイトのクローリング防止テクノロジーに対処するために必要な複雑なプログラミング、Web サイトの変更に適応するための定期的なメンテナンスの必要性、機密データとプライバシーの問題の関与などが含まれます。
図例
1. ScrapeStormの例。
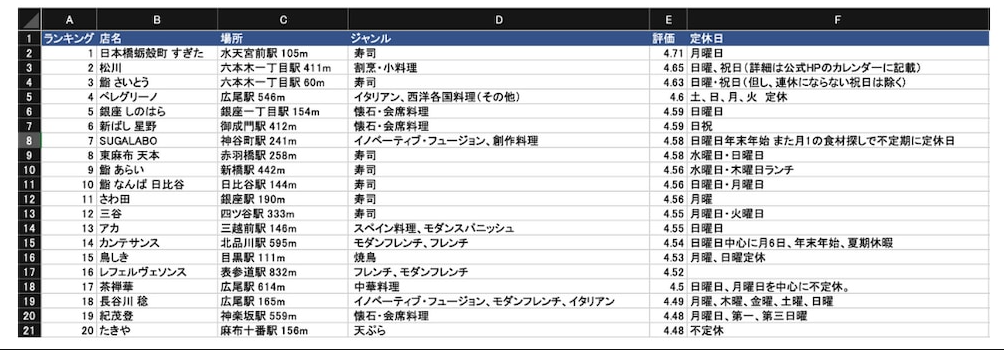
2. 抽出されたデータ。
関連記事
参考リンク
https://www.esector.co.jp/bpa/A20-055.html