【フローチャートモード】順番にクリック機能で詳細ページをスクレイピング | Webクローラ | ScrapeStorm
摘要:この記事では、ScrapeStormのフローチャートモードを使用して、順番にクリック機能を設定して詳細ページのデータを収集する方法を簡単に説明します。 ScrapeStorm無料ダウンロード
この記事では、ScrapeStormのフローチャートモードを使用して、順番にクリック機能を設定して詳細ページのデータを収集する方法を簡単に説明します。
1. 対象の Webサイトのリンクをコピーします。
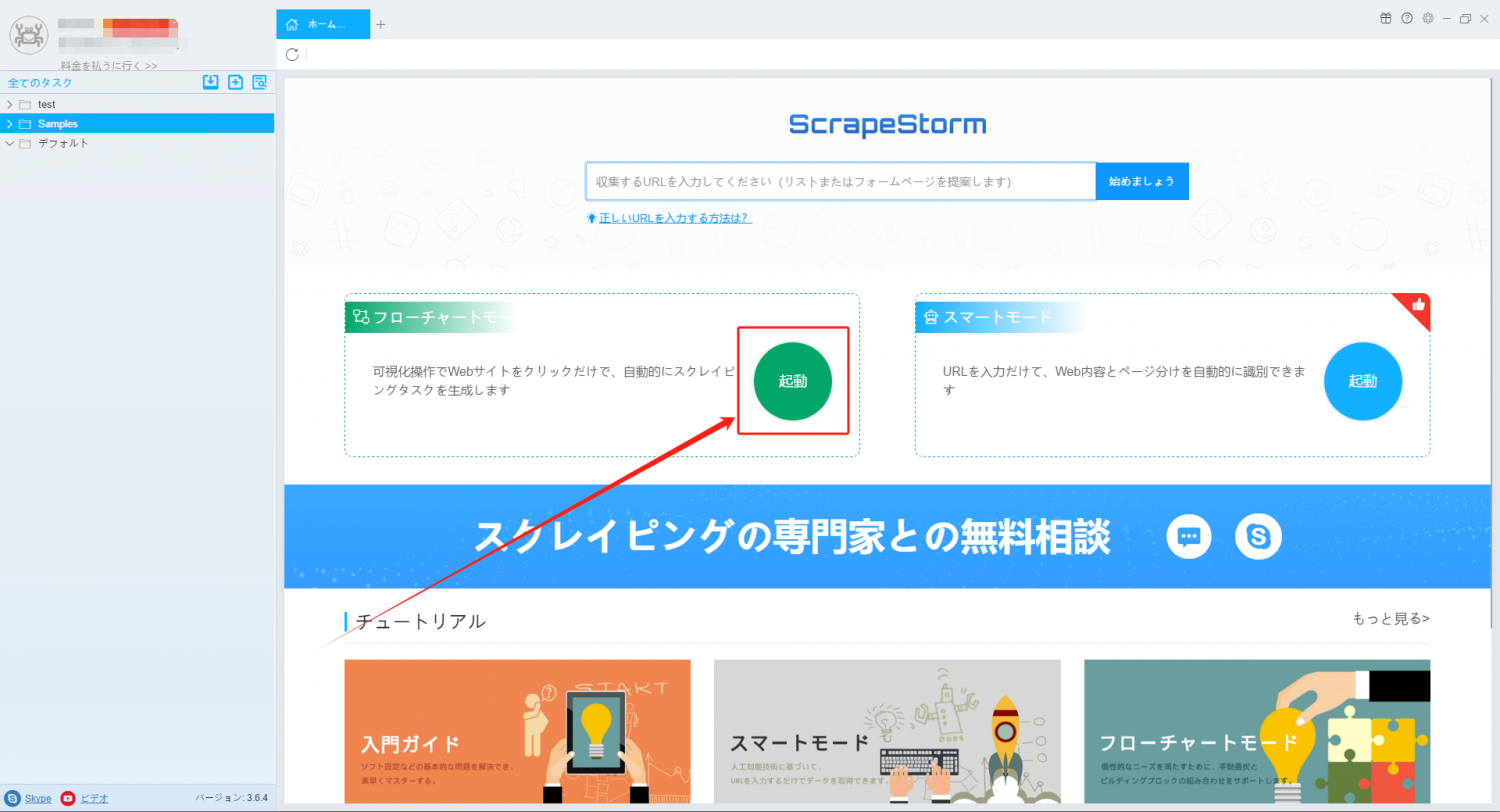
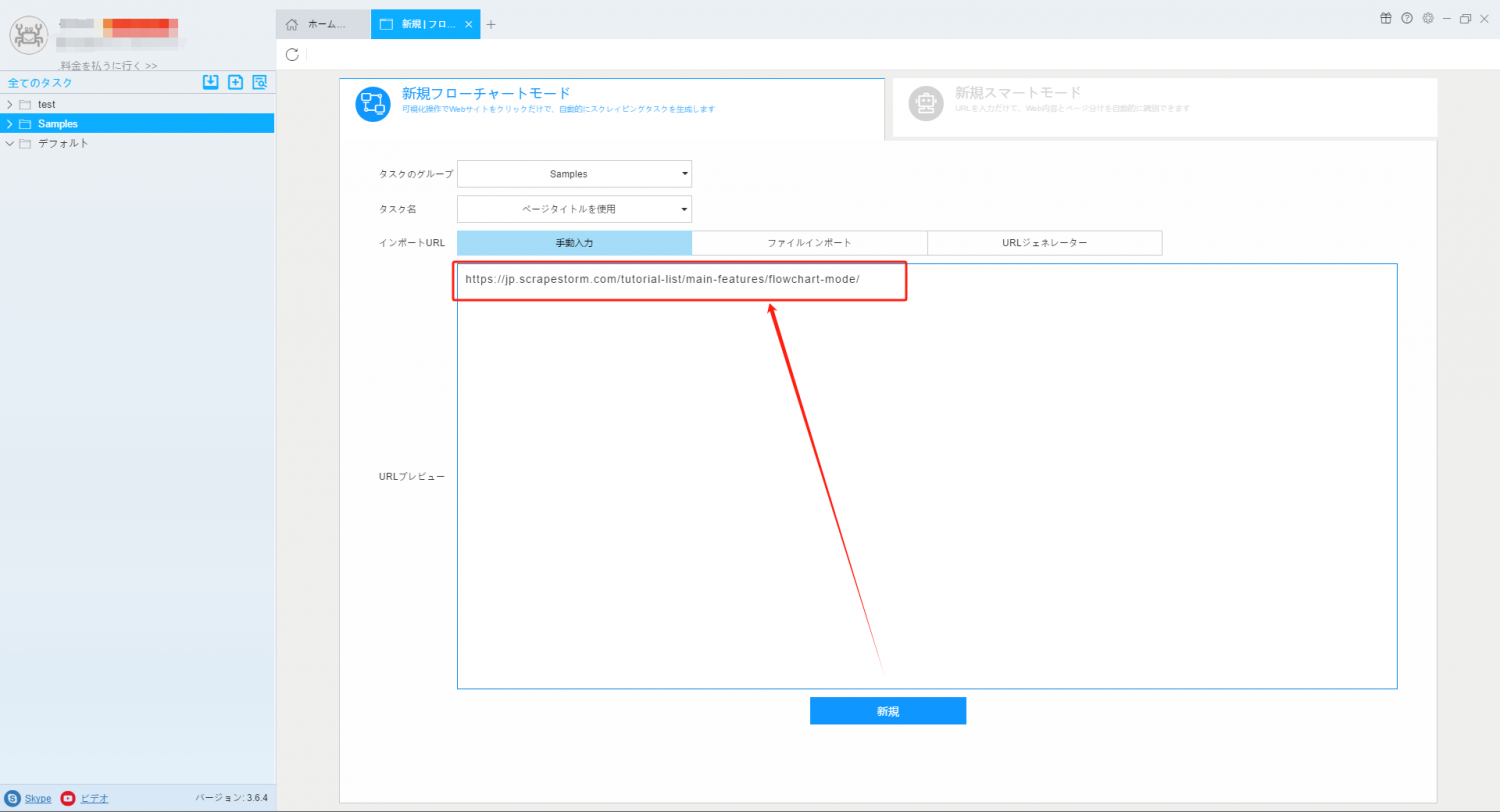
2. フローチャートモードのタスクを作成します。
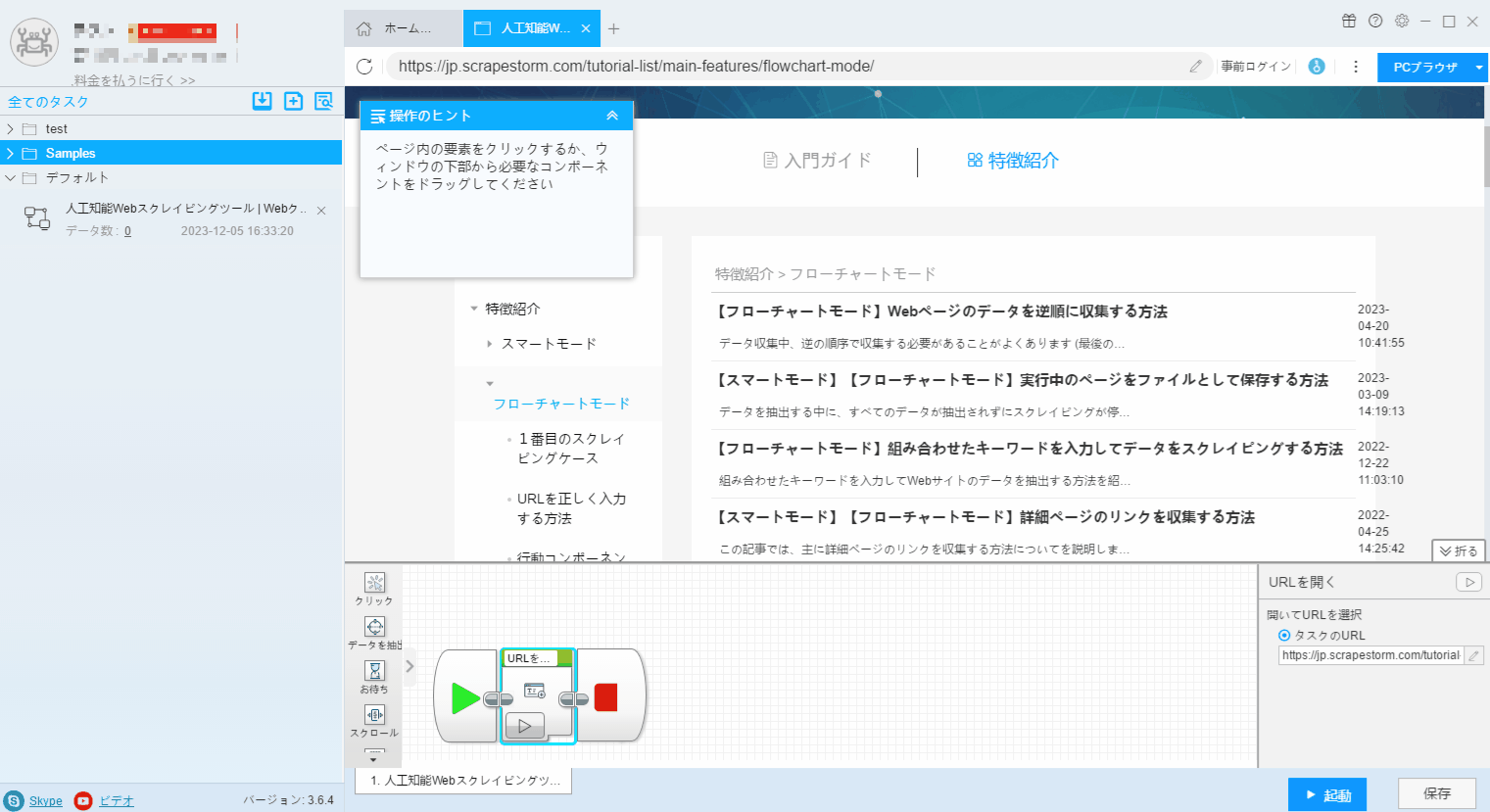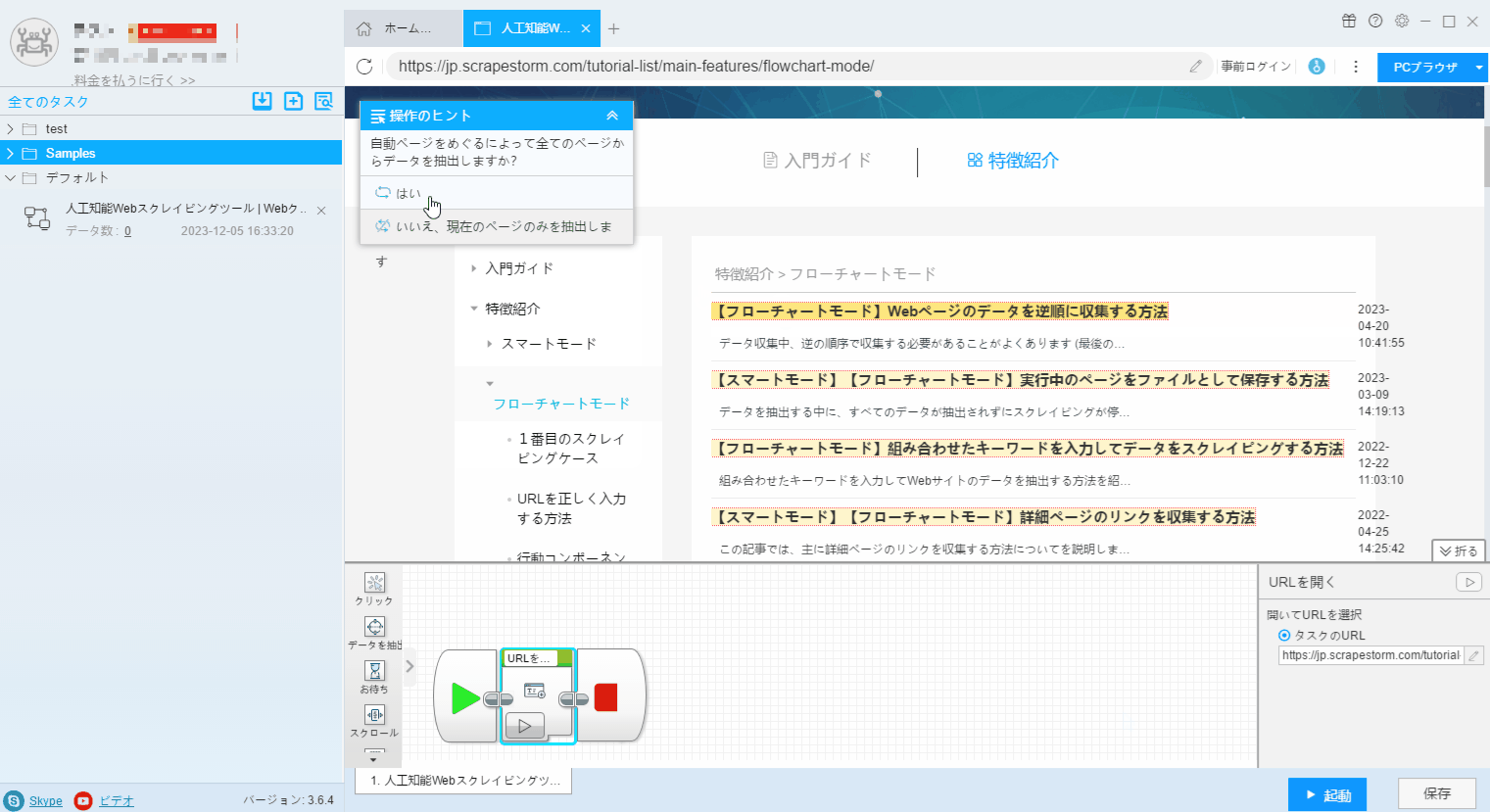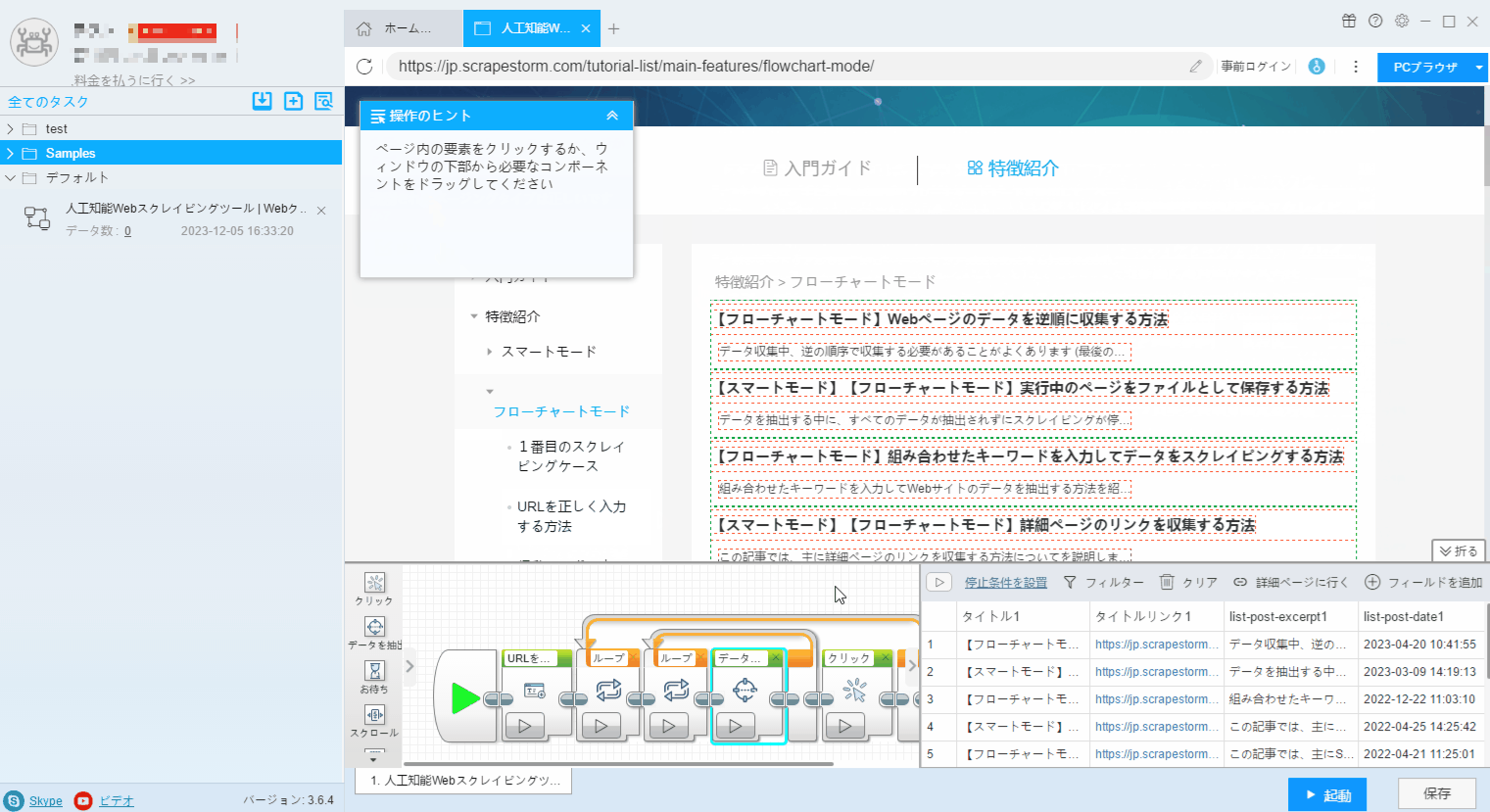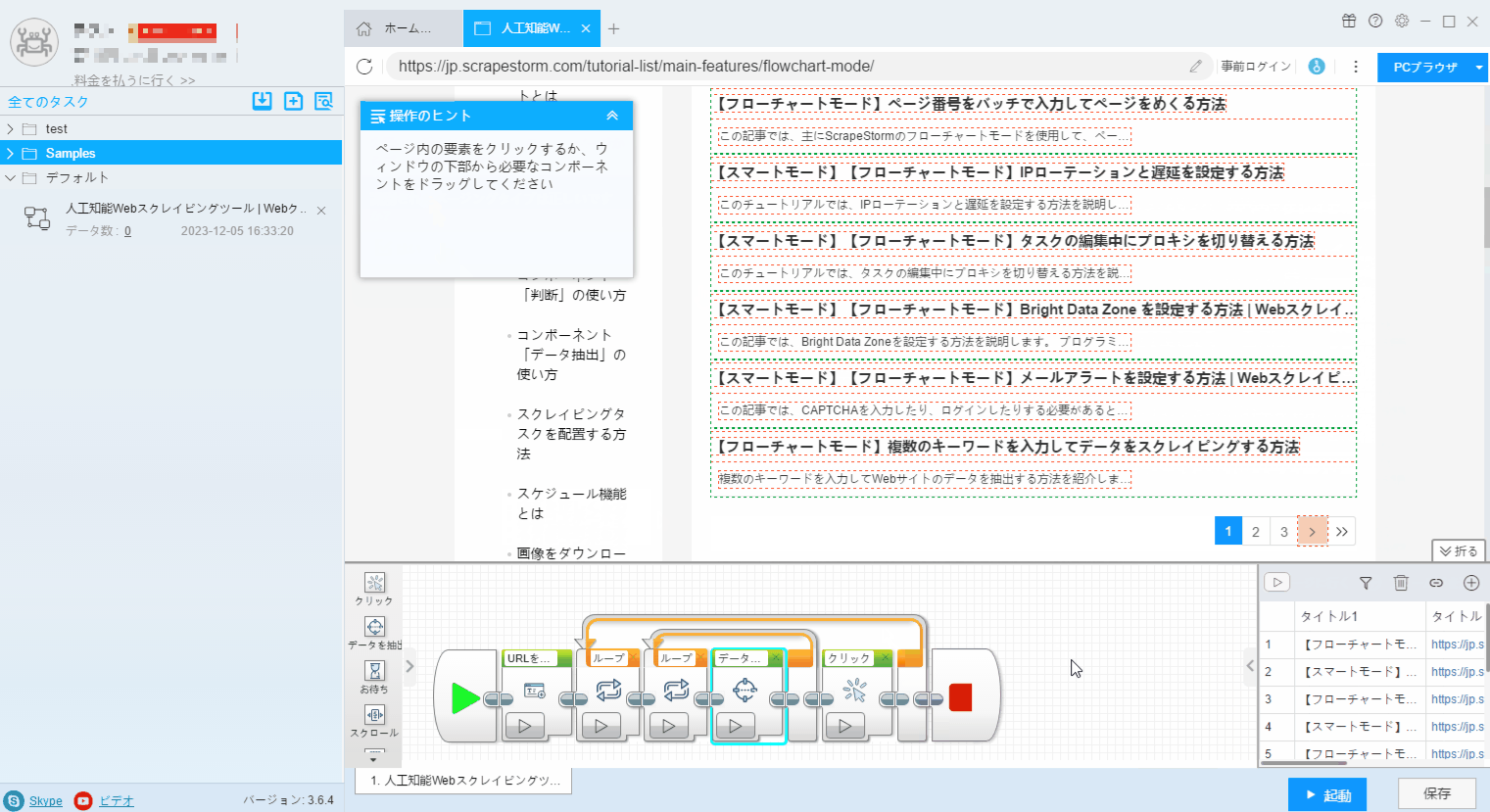
3. フローチャートモードの「操作ヒント」に従う、リスト要素とページボタンを識別します。
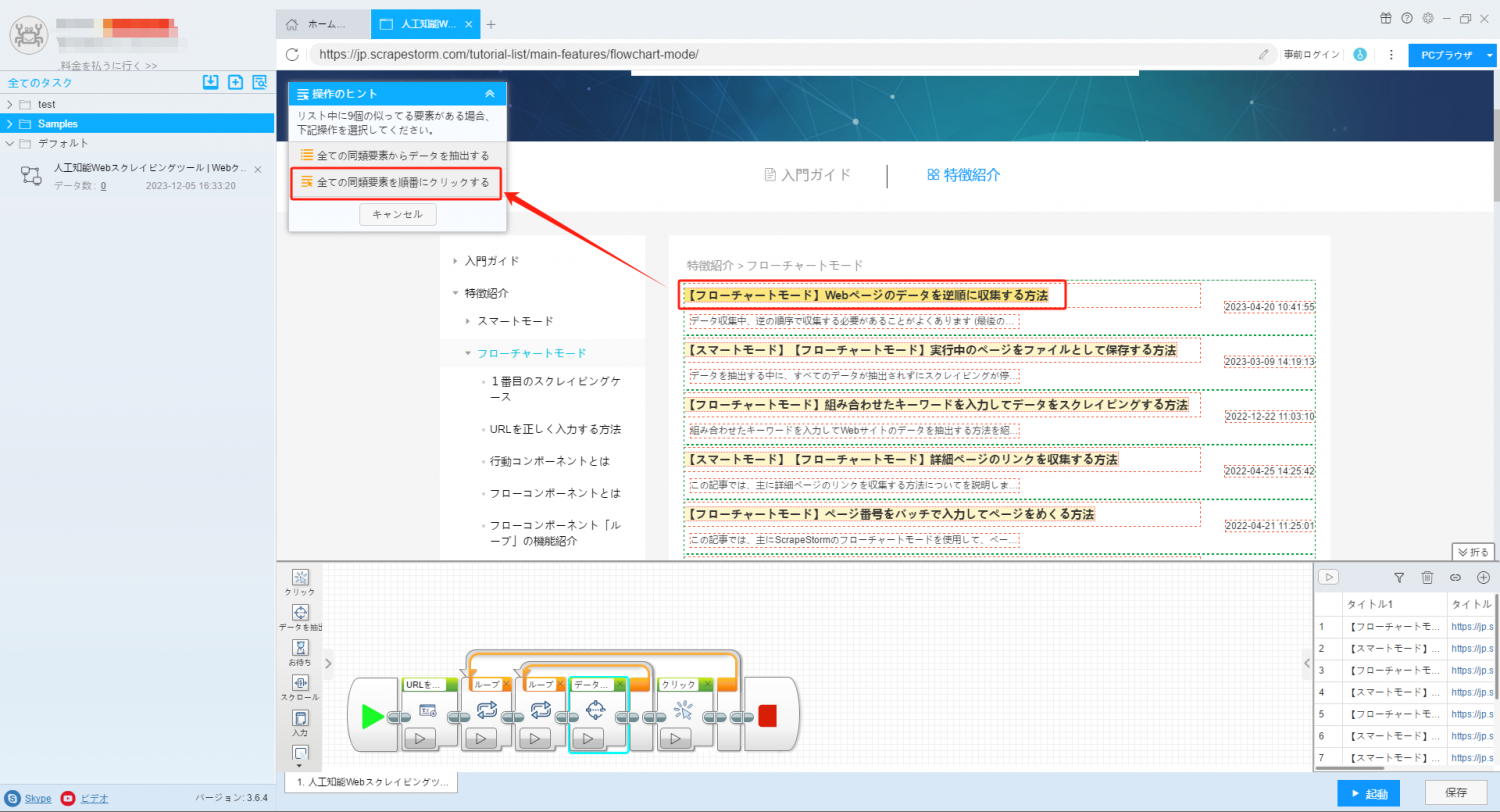
4. Webページ内のリンク付きデータ (通常は製品名、記事のタイトルなど) をクリックし、操作ヒントで「全ての同類要素を順番にクリック」を選択します。
5. クリックコンポーネントが自動的に生成されるので、コンポーネントを選択し、右側のコンポーネントの「新しいタブを開く」設定で「いいえ」を選択します。
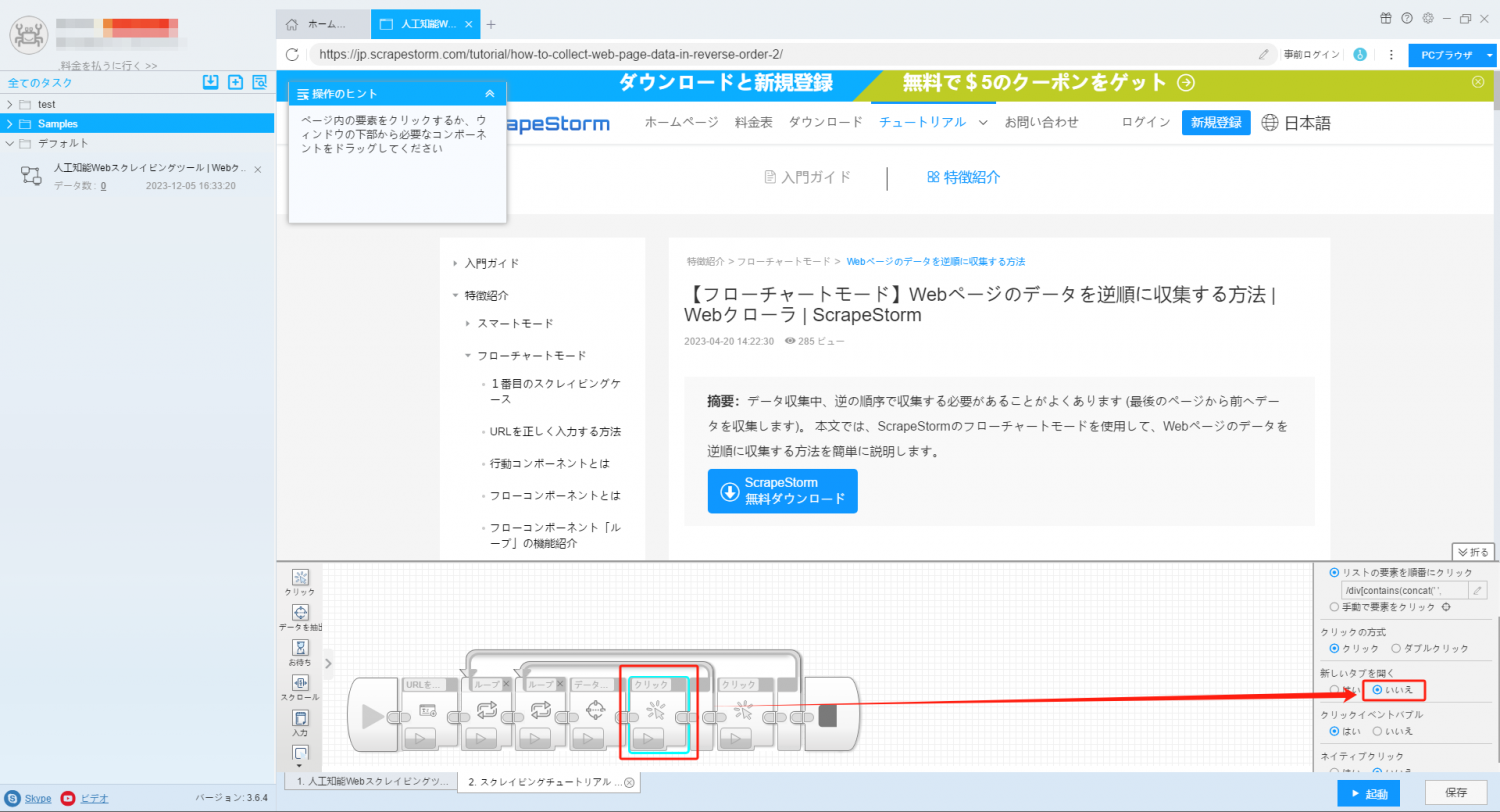
6. 右下隅にタスク設定を保存します。
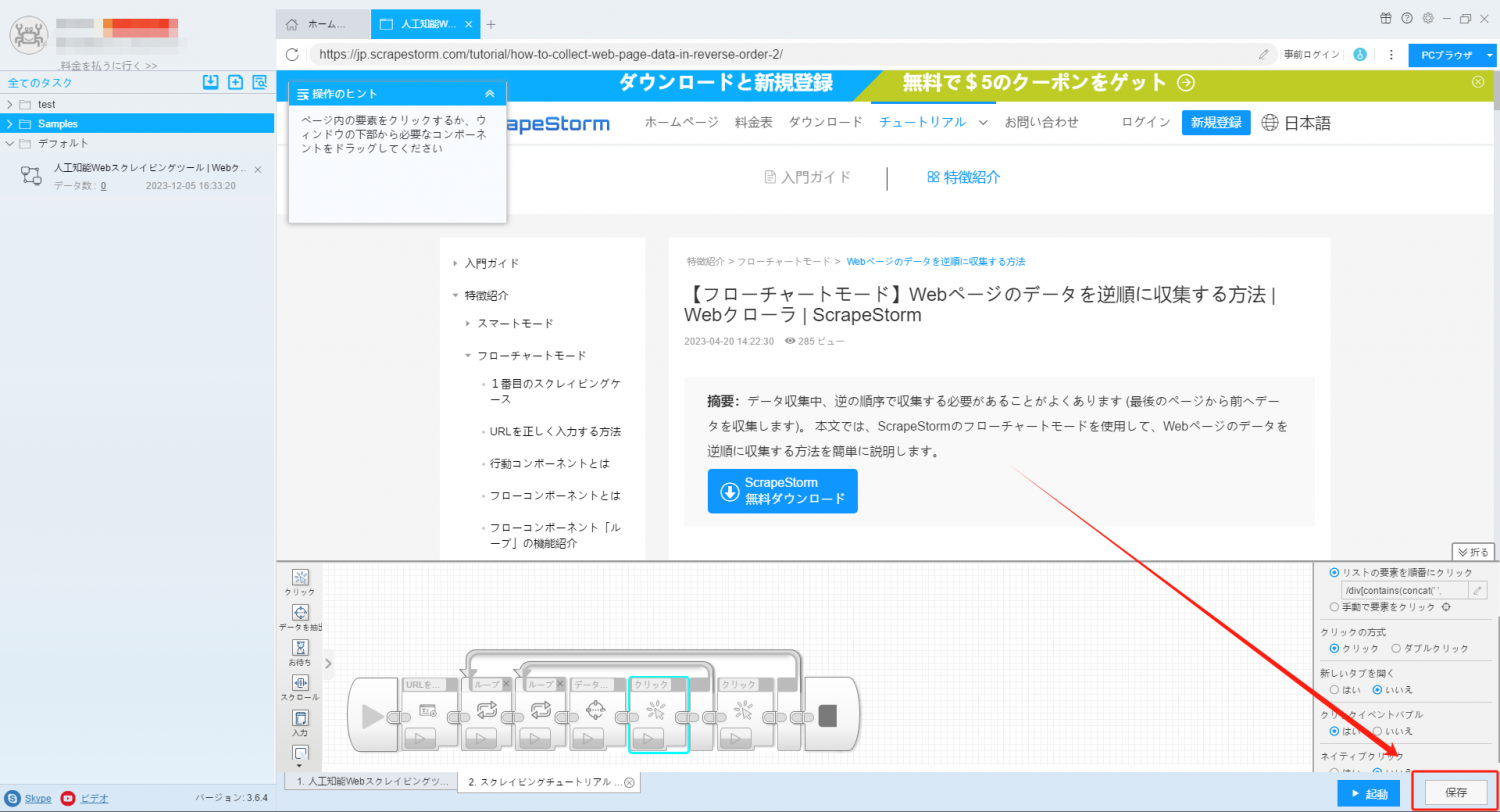
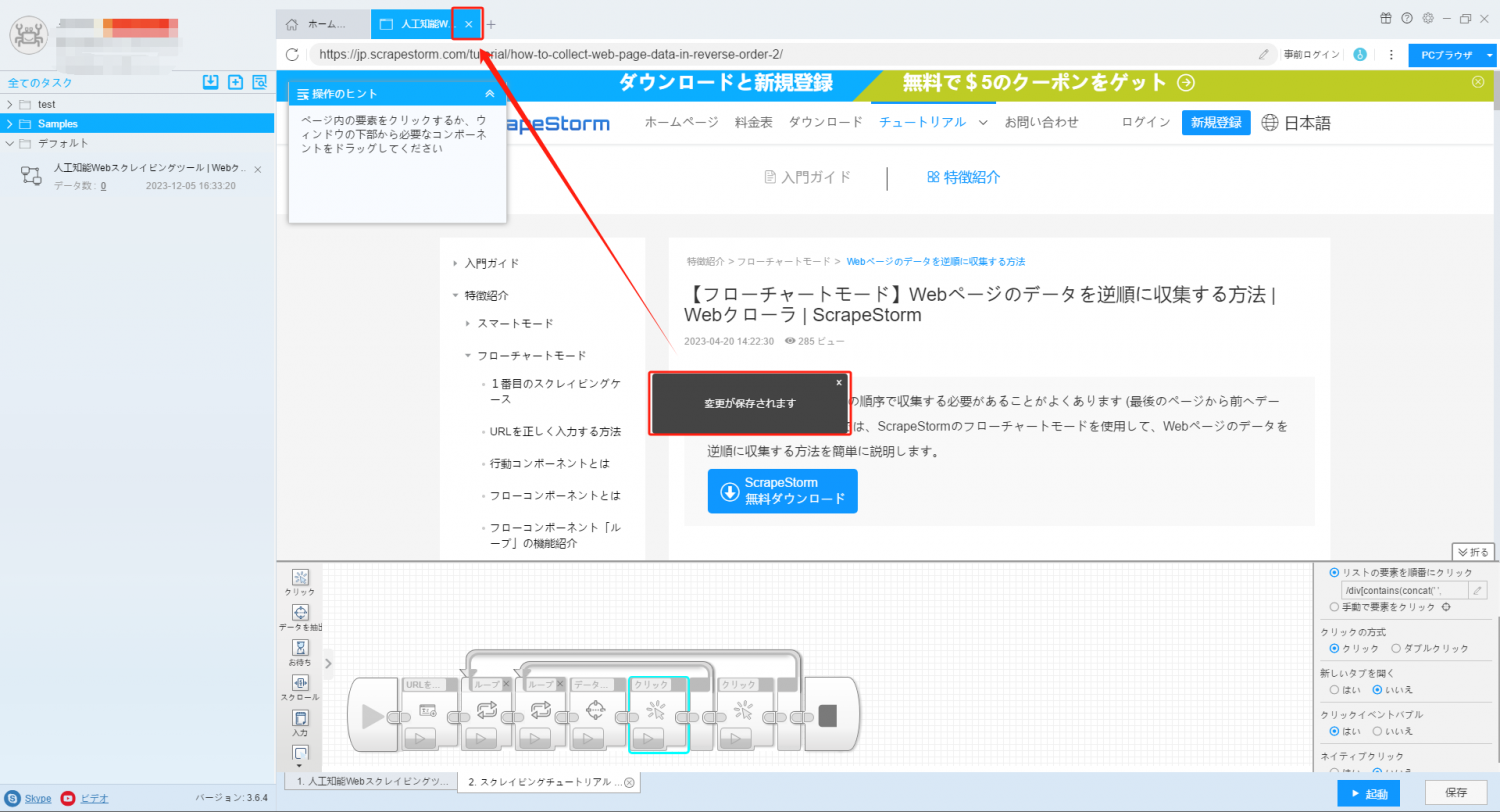
7. 「変更が保存されます」した後、タスクの編集インターフェイスを閉じます。
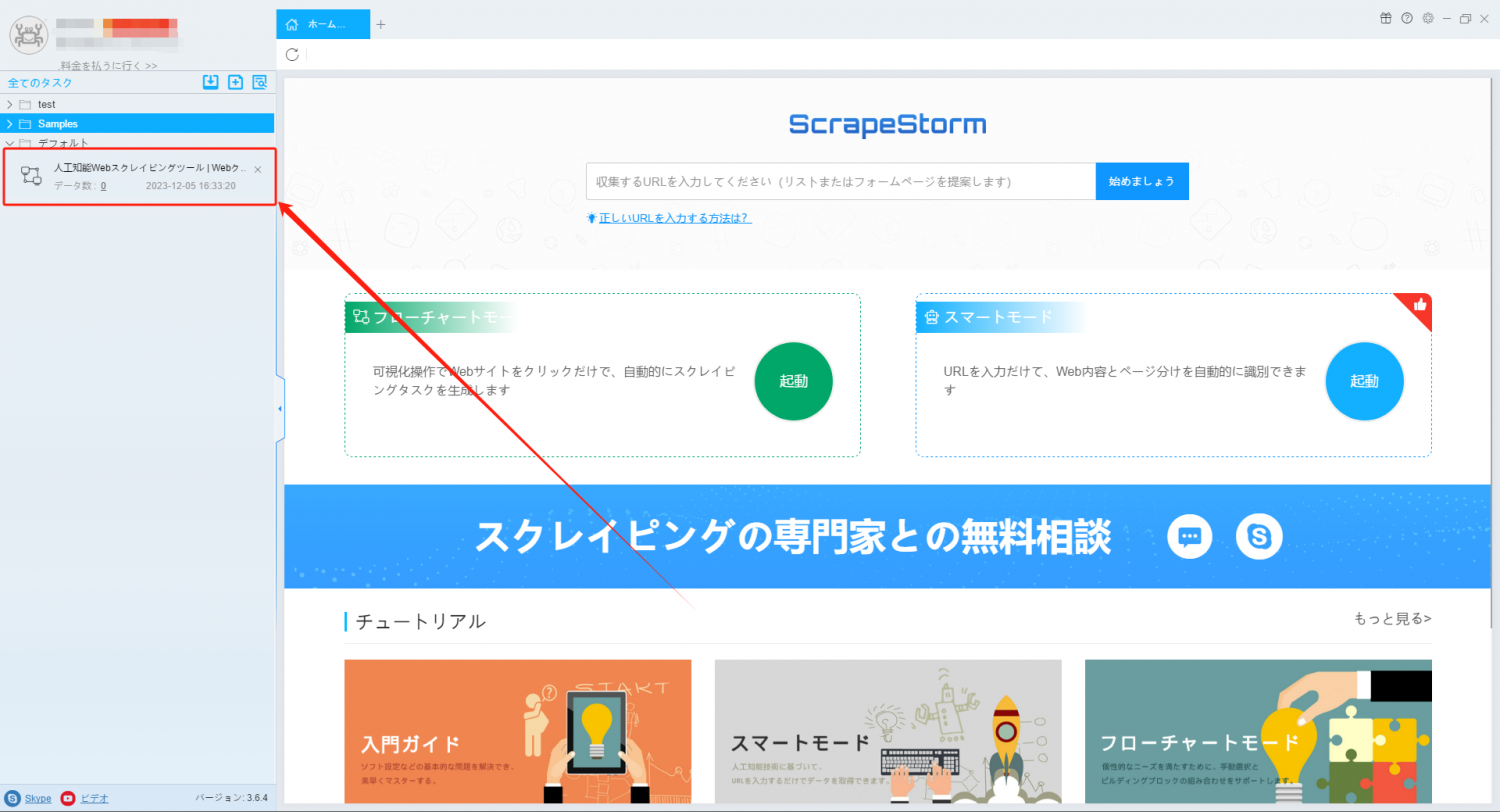
8. タスクリストをダブルクリックしてタスクを再度開き、編集インターフェイスに入ります。この時点で、コンポーネントが自動的に実行された後、詳細ページを通常どおり開くことができます。
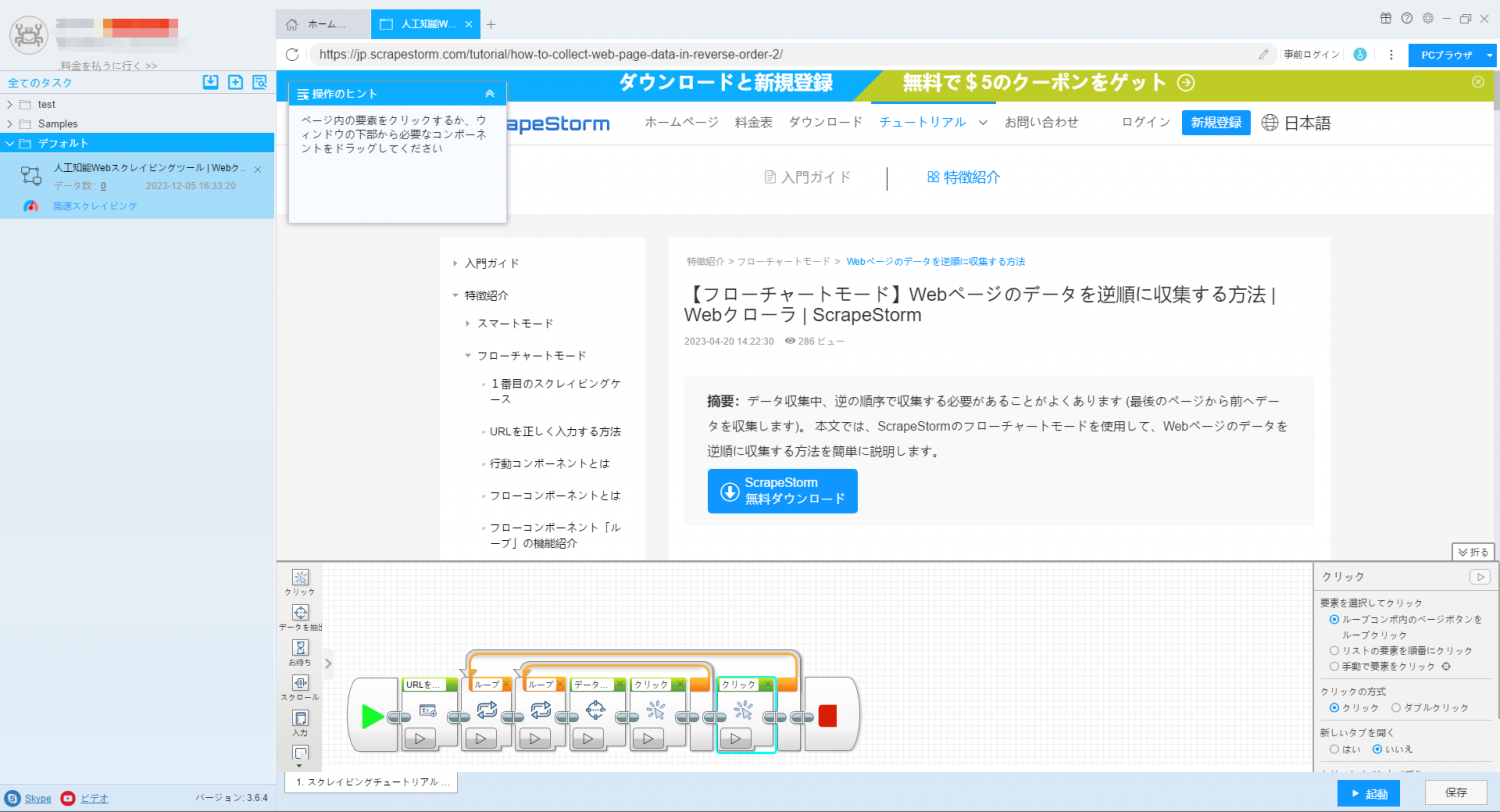
9. 操作ヒントを使用して、詳細ページのデータを識別して抽出します。
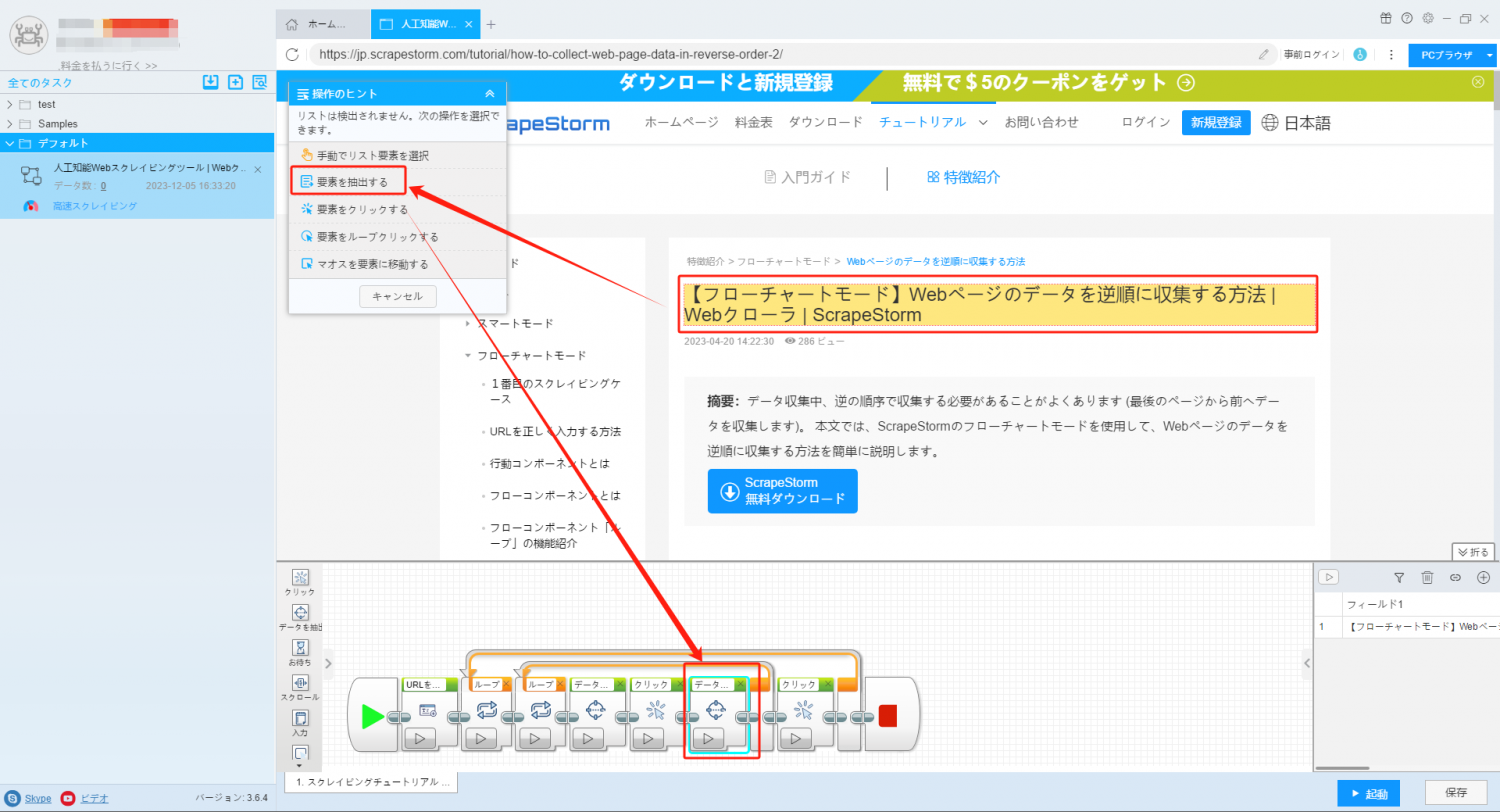
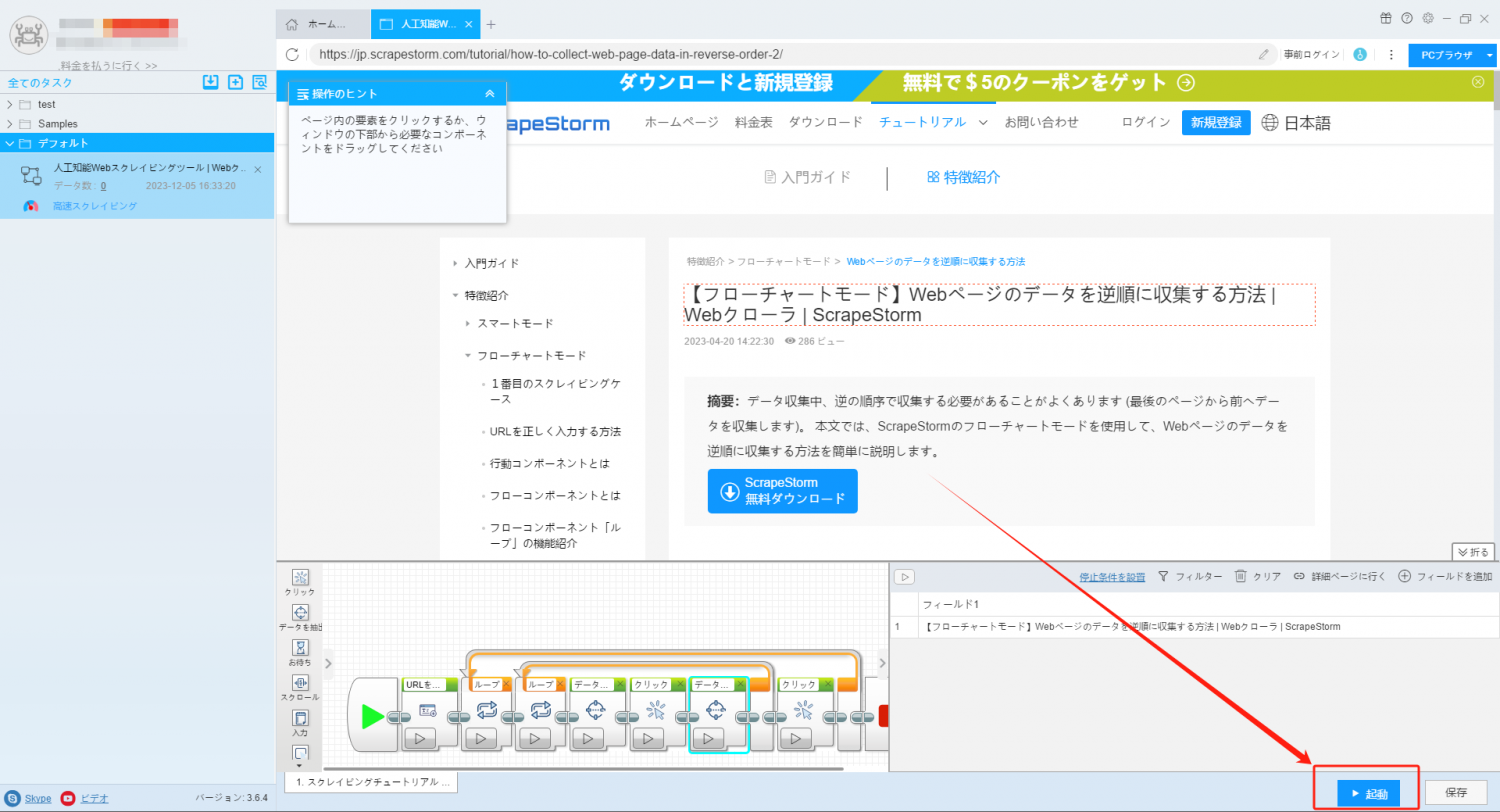
10. タスクを起動してスクレイピングを開始します。
順番にクリック機能を利用して、詳細ページの情報を収得する方法はこれ以上です。 次に、収集中に詳細ページから一覧ページに正常に戻れず、最初の詳細ページのデータしか収集できなかった特殊な状況を紹介します。 この状況を解決するには 2 つの方法があります。
方法 1: 詳細ページ自体に閉じるボタン/戻るボタンがある場合、詳細ページの「データ抽出」コンポーネントの後に「クリック」コンポーネントを追加し、詳細ページの閉じるボタン/戻るボタンを識別することをお勧めします。 このようにして、ソフトウェアは詳細ページのデータ抽出を完了した後、詳細ページを閉じて、次の詳細ページを収集します。
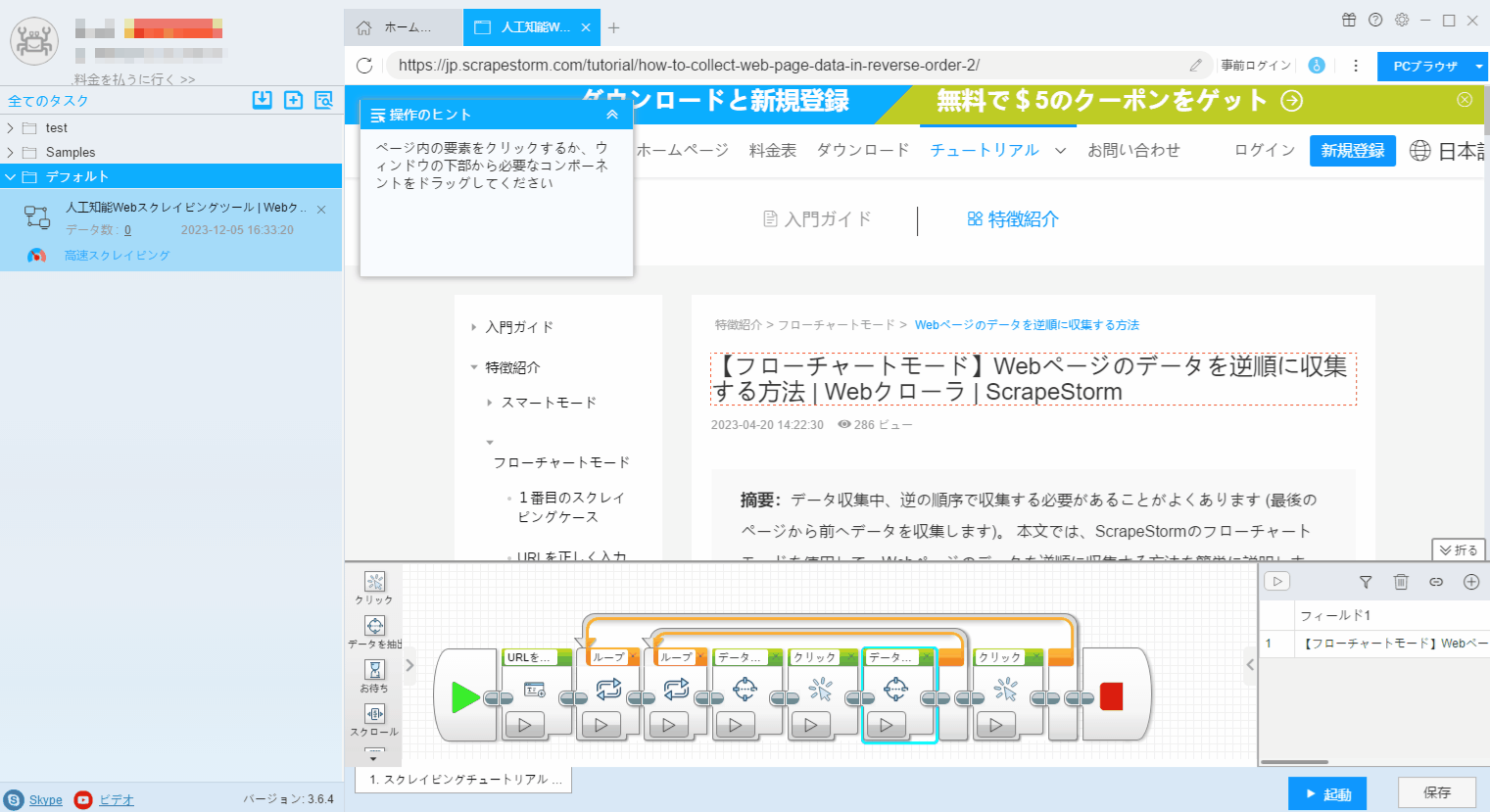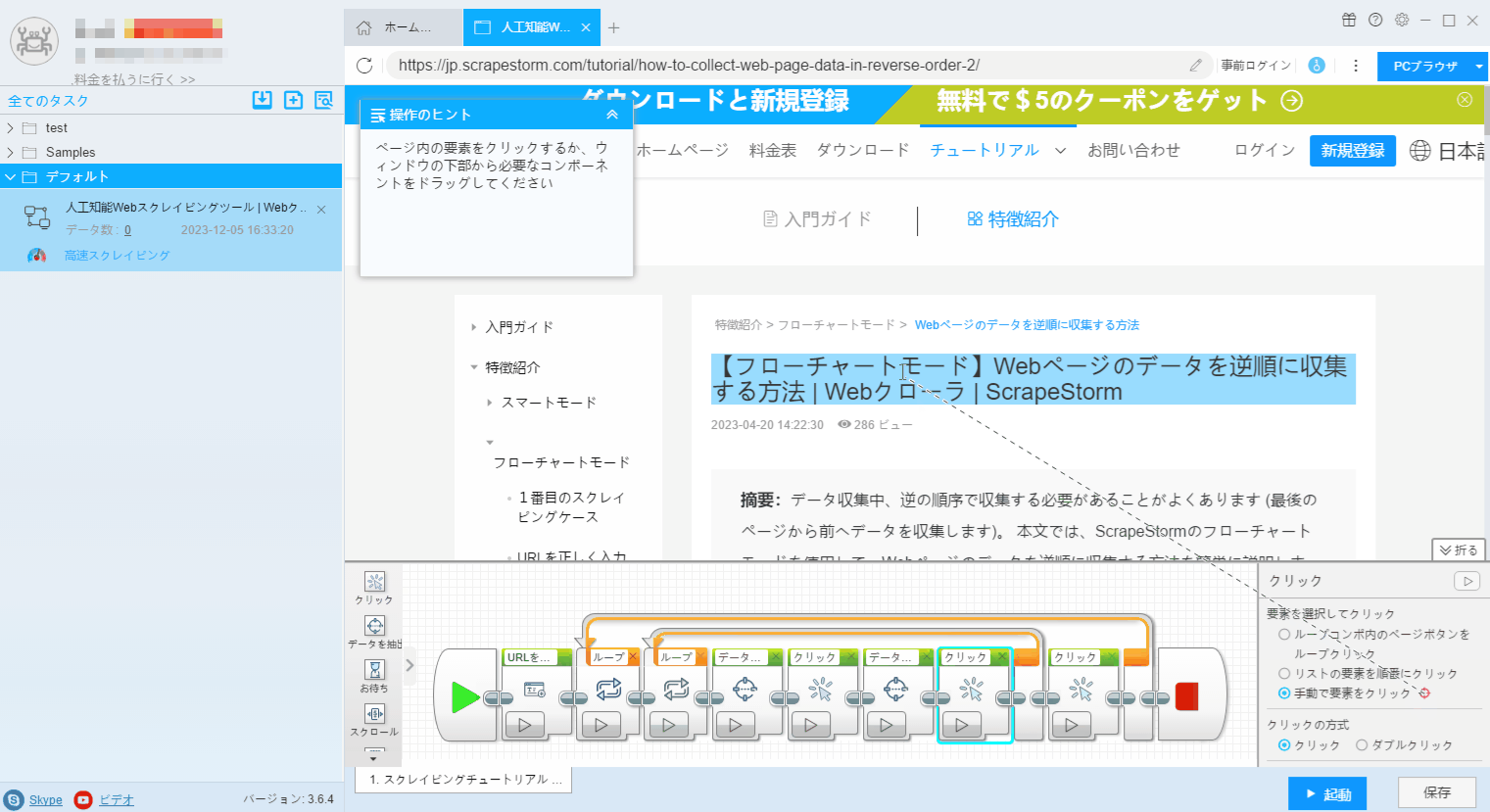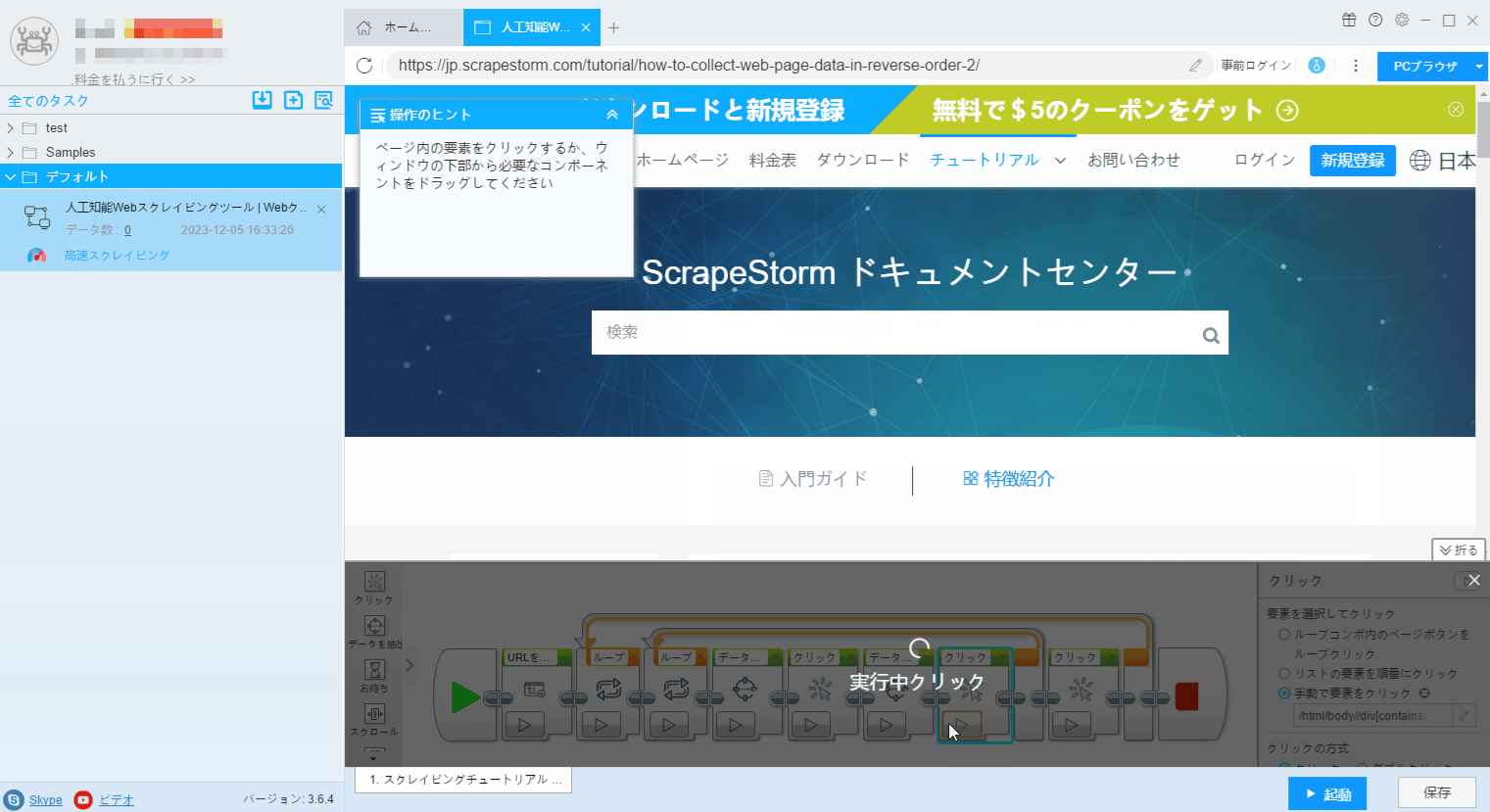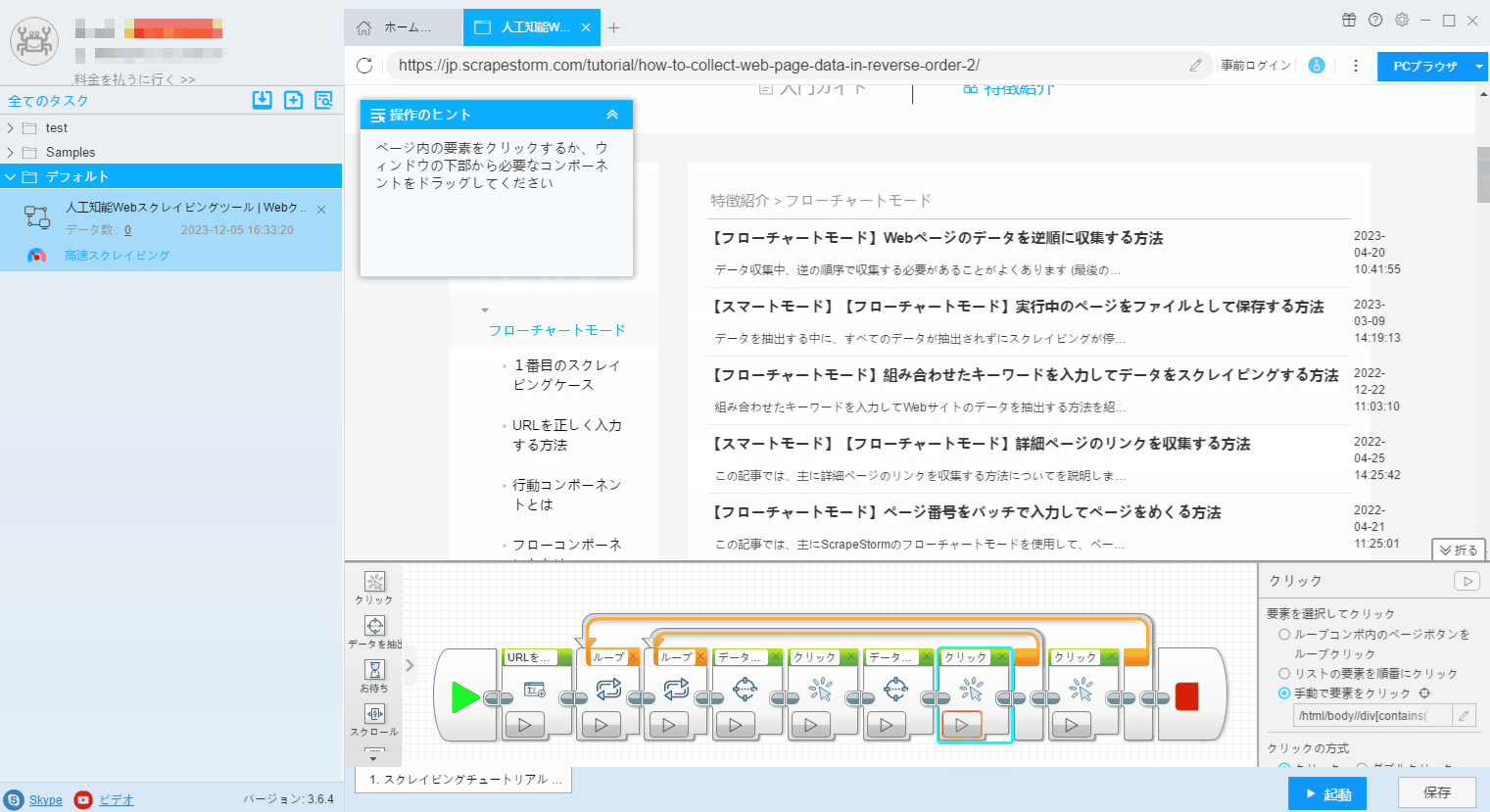
方法 2: 詳細ページ自体に閉じるボタン/戻るボタンがない場合は、詳細ページの「データ抽出」コンポーネントの後に「戻る」コンポーネントを手動でドラッグして追加できます。このように、詳細ページでデータ抽出を実行した後、ソフトウェアは自動的にリストページに戻り、次の詳細ページを収集します。