【スマートモード】【フローチャートモード】IPローテーションと遅延を設定する方法 | Webクローラ | ScrapeStorm
摘要:このチュートリアルでは、IPローテーションと遅延を設定する方法を説明します。 ScrapeStorm無料ダウンロード
IPローテーション、自動設定、手動設定が含まれています。この部分は、主に、発生する可能性のあるさまざまなWebサイトのブロックの問題を回避するために使用されます。
タスク編集画面で、起動をクリックして、実行の設定画面を開く、アンチブロックを設定できます。
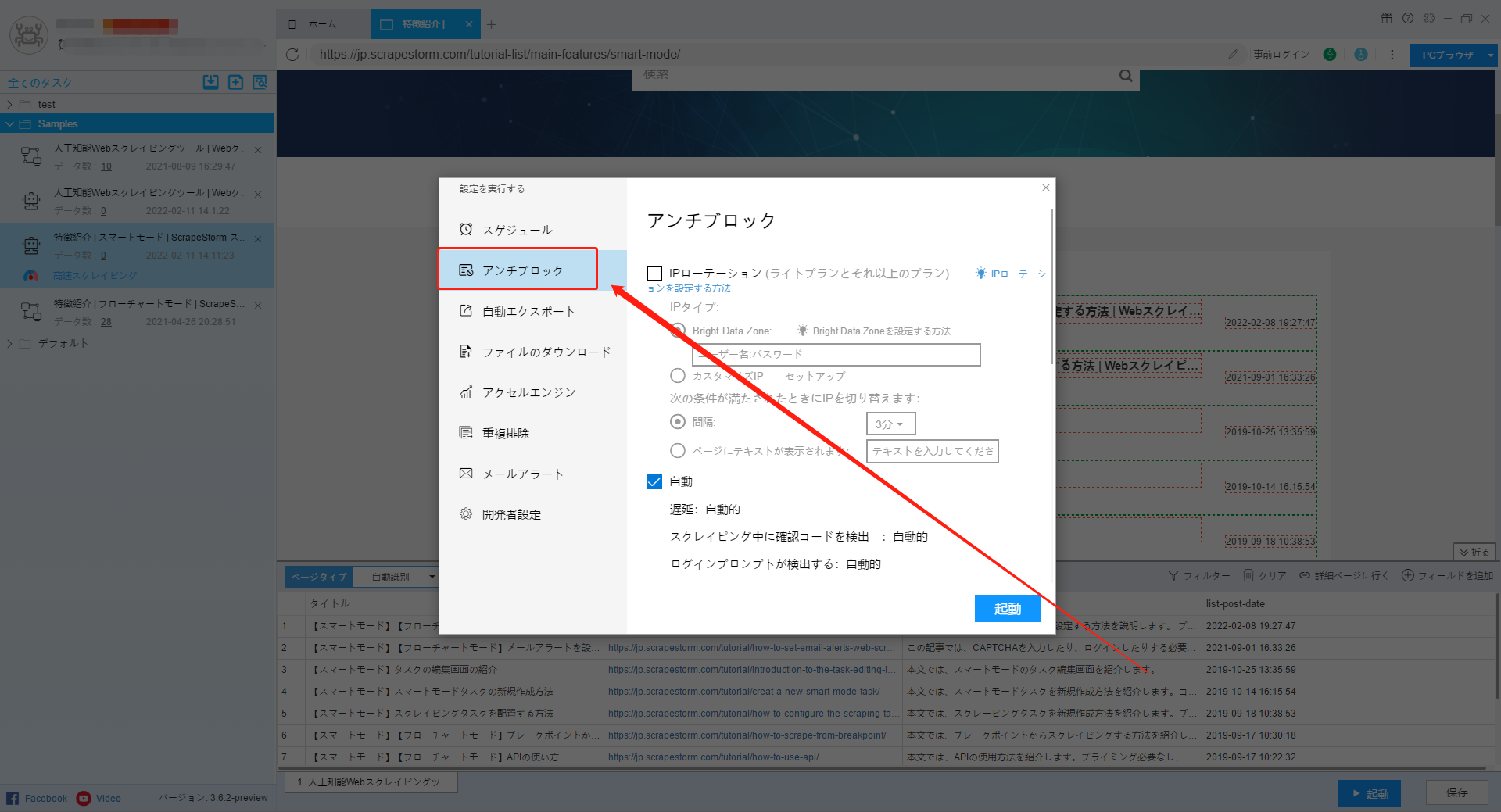
1. IPローテーション
(1) IP のタイプ
ⅰ. Bright Data Zone
Bright Data Zone は外部プロキシで、公式ウェブサイトでIPを購入する必要があります。
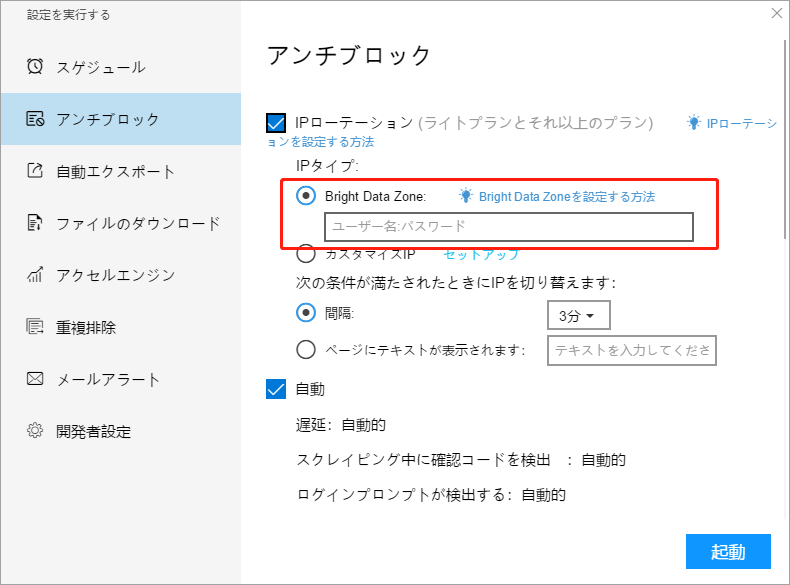
ⅱ. カスタマイズ IP
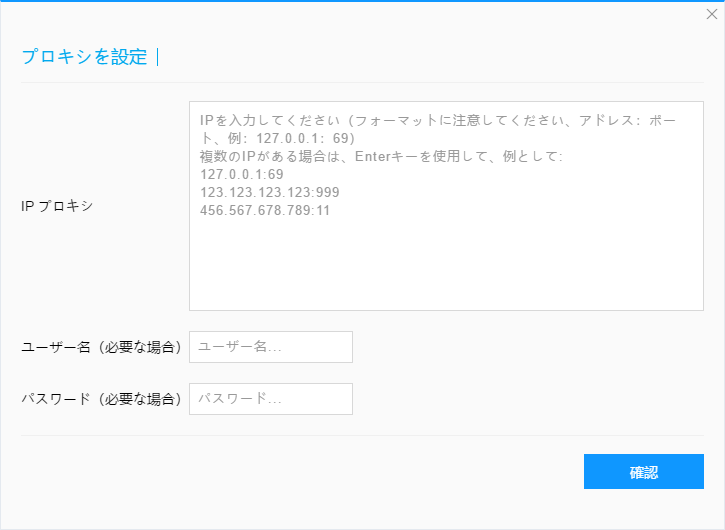
自分のIPを使用する必要がある場合は、「セットアップ」をクリックして、必要に応じて設定してください。 注:カスタムIPは順番に切り替えられます。
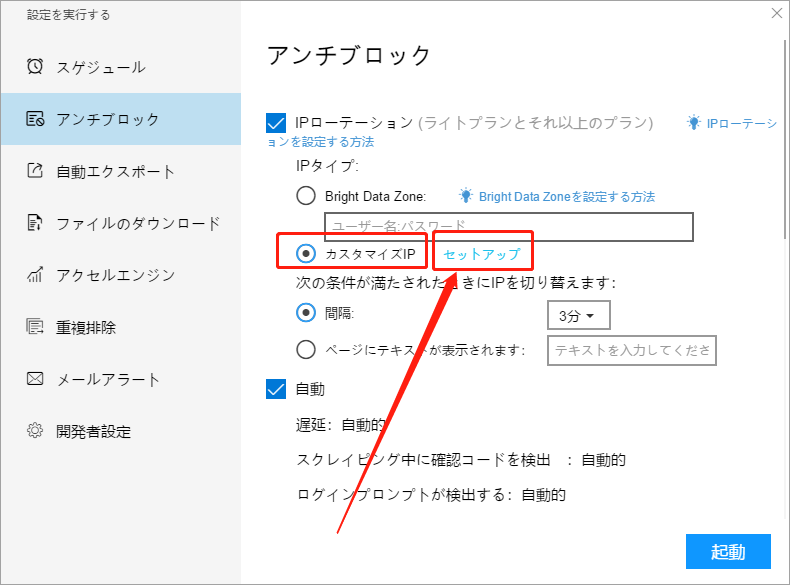
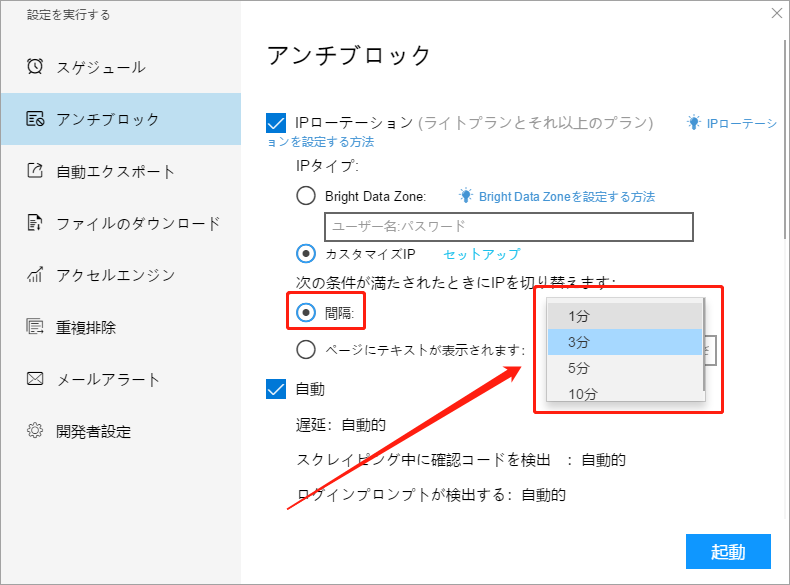
(2) 次の条件が満たされたときにIPを切り替えます:
ⅰ. 間隔
時間に基づくIPを切り替えます。たとえば、切り替え条件を「間隔:3分」に設定すると、IPは3分ごとに切り替えられ、同時に1つのIPが消費されます。
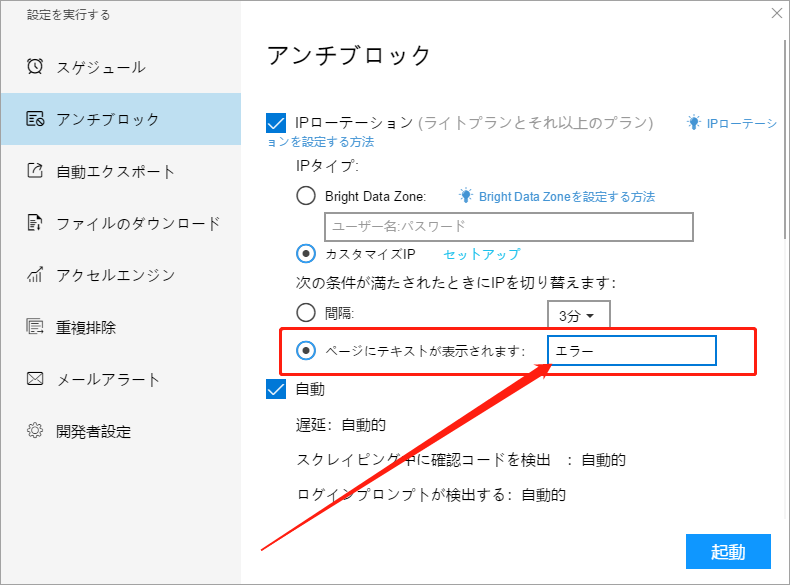
ⅱ. ページにテキストが表示されます
テキストに従って切り替えます。 たとえば、切り替え条件を「ページにテキストが表示されます:エラー」に設定した場合、対応するテキストがWebページに表示されると、IPが1回切り替えられ、同時に1つのIPが消費されます。
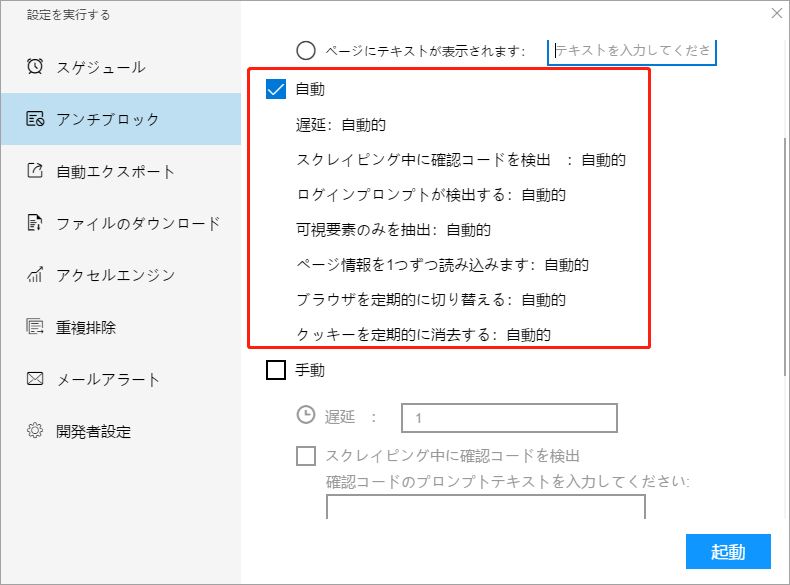
2. 自動
一般的なスクレイピングタスクについては、デフォルト自動に設定します。
3.手動
Webサイトが特別な場合、自動モードがうまくデータを取得できない時、手動モードを利用してください。
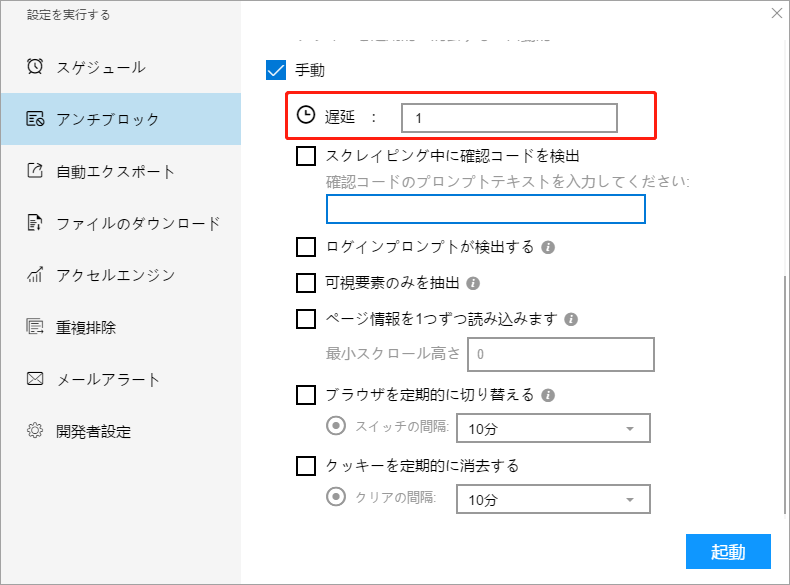
ⅰ. 遅延(s)
一部のWebページはゆっくりと開き、スクレイピング効果に影響を与えることがあります。 遅延を設定して、スクレイピングの品質を効果的に向上させることができます。 システムのデフォルトの遅延は1秒ですが、必要に応じて変更できます。
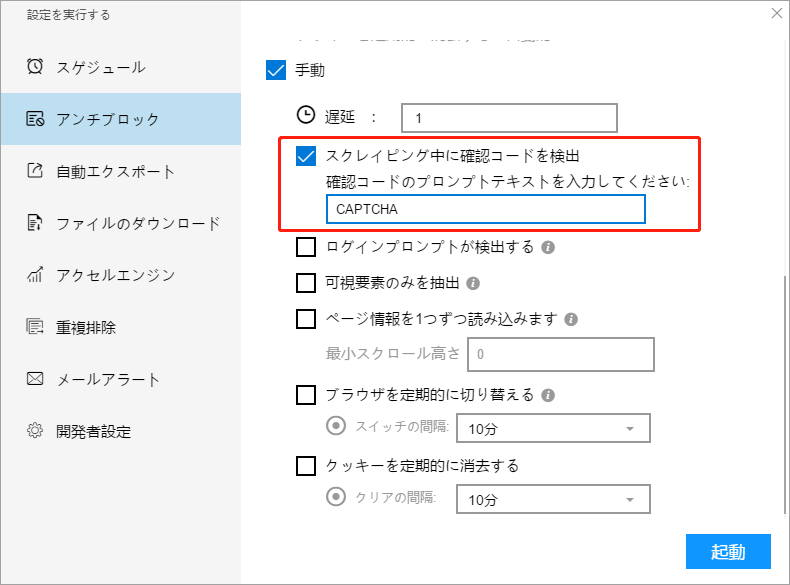
ⅱ.スクレイピング中にキャプチャを検出する
ソフトウェアは通常、キャプチャを自動的に検出します。 特別な場合には、特定のテキストに遭遇したときにキャプチャを検出するように手動で設定できます。
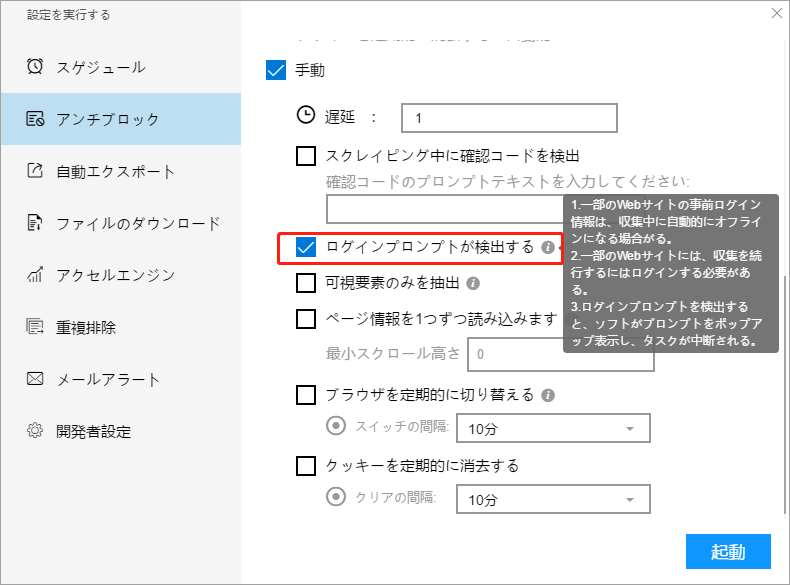
ⅲ. スクレイピング中にログインプロンプトを検出する
データをスクレイピングするためにログインする必要のあるWebサイトは、実行中にログアウトされてデータをスクレイピングできなくなる場合があります。または、一部のWebサイトでは、一定量のデータをスクレイピングした後にログインを求められます。 この機能を利用して、 ログアウトするか、ログインする必要がある場合は、ログインするように求められます。
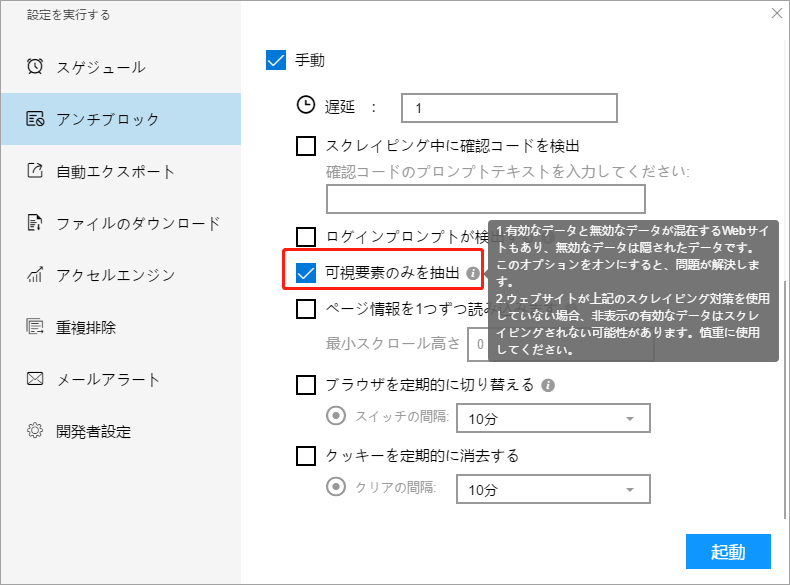
ⅳ.可視化要素のみを抽出する
一部のWebサイトでは、無効なデータと有効なデータが混在しています。 データをスクレイピングすると、多くの無効な文字が表示され、これらの無効な文字は非表示になります。 この場合、この設定を選択して、表示されている要素のみをスクレイプできます。
注:Webサイトに無効な文字を非表示にする設定がない場合、このオプションを選択すると、データが不完全になるか、スクレイプできなくなります。
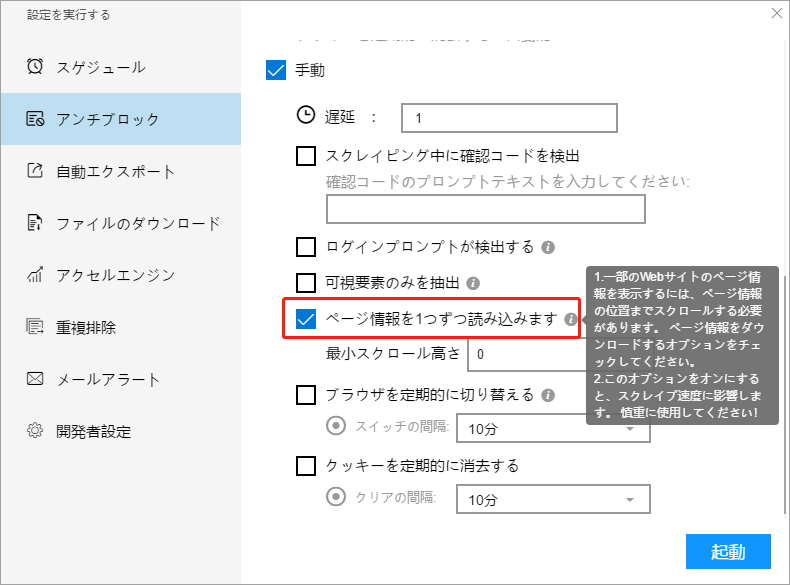
ⅴ. ページ情報を1つずつ読み込む
一部のWebサイトでは、コンテンツを表示する前に特定の位置までスクロールする必要があります。そうしないと、データをスクレイプできず、この時点でこの機能を選択してください。 ただし、この機能をチェックすると、スクレイピングの速度に影響が出ますのでご注意ください。
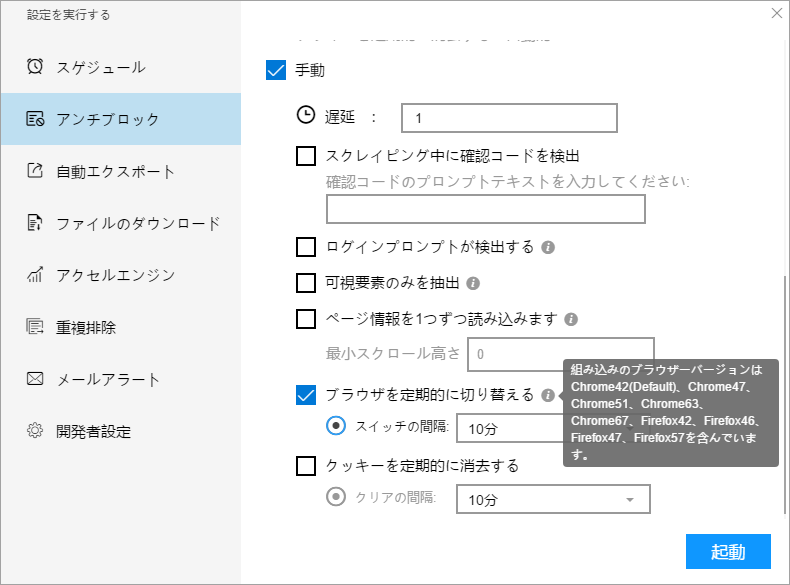
ⅵ. ブラウザを定期的に切り替える
ブラウザを定期的に切り替えることで、一部のWebサイトのブロックの問題を解決し、ブロック防止効果を得ることができます。
ブラウザのバージョンを切り替える間隔を設定できます。 30秒から10分までの間隔を設定します。 ソフトウェアは、間隔に応じてさまざまなブラウザバージョンを自動的に切り替えます。
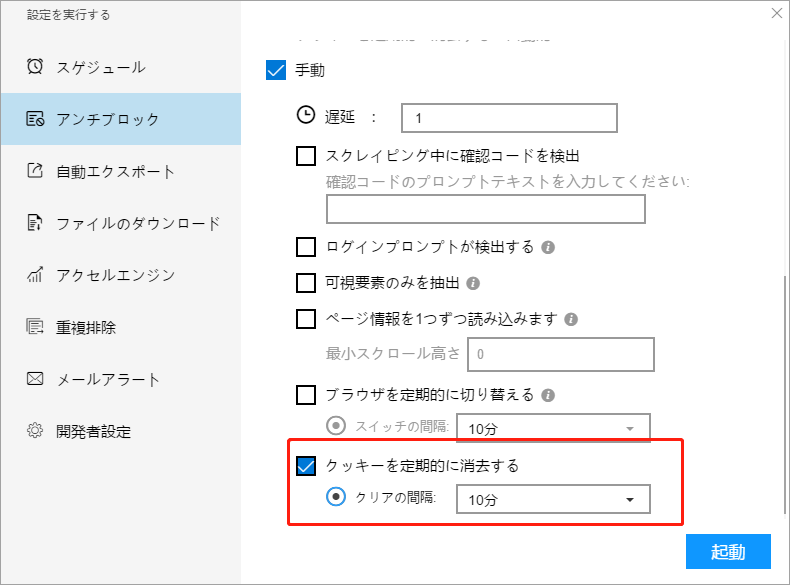
ⅶ. 定期的にCookieをクリアする
Cookieを定期的にクリアすると、一部のWebサイトのブロックの問題を解決し、ブロック防止効果を得ることができます。
Cookieをクリアする間隔を設定できます。 30秒から10分までの間隔を設定します。 ソフトウェアは、間隔に応じて自動的にCookieをクリアします。