【スマートモード】【フローチャートモード】詳細ページのリンクを収集する方法 | Webクローラ | ScrapeStorm
摘要:この記事では、主に詳細ページのリンクを収集する方法についてを説明します。 ScrapeStorm無料ダウンロード
データ収集の時、よく詳細ページのリンクを必要です。本文では、ScrapeStormのスマートモードを利用して、三つの詳細ページのリンクを取得する方法を紹介します。フローチャートモードの方法も同じです。
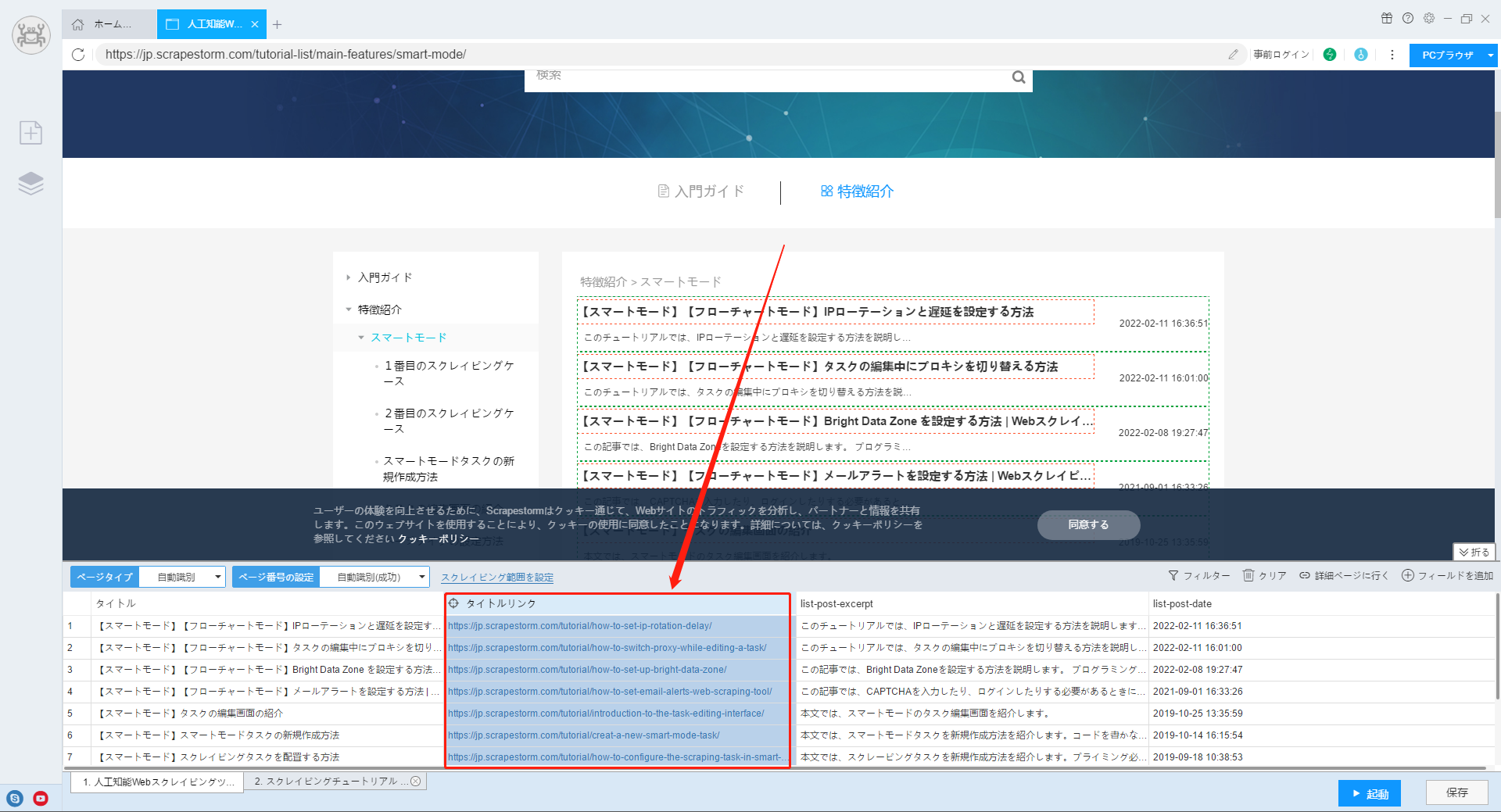
方法一:自動識別で獲得
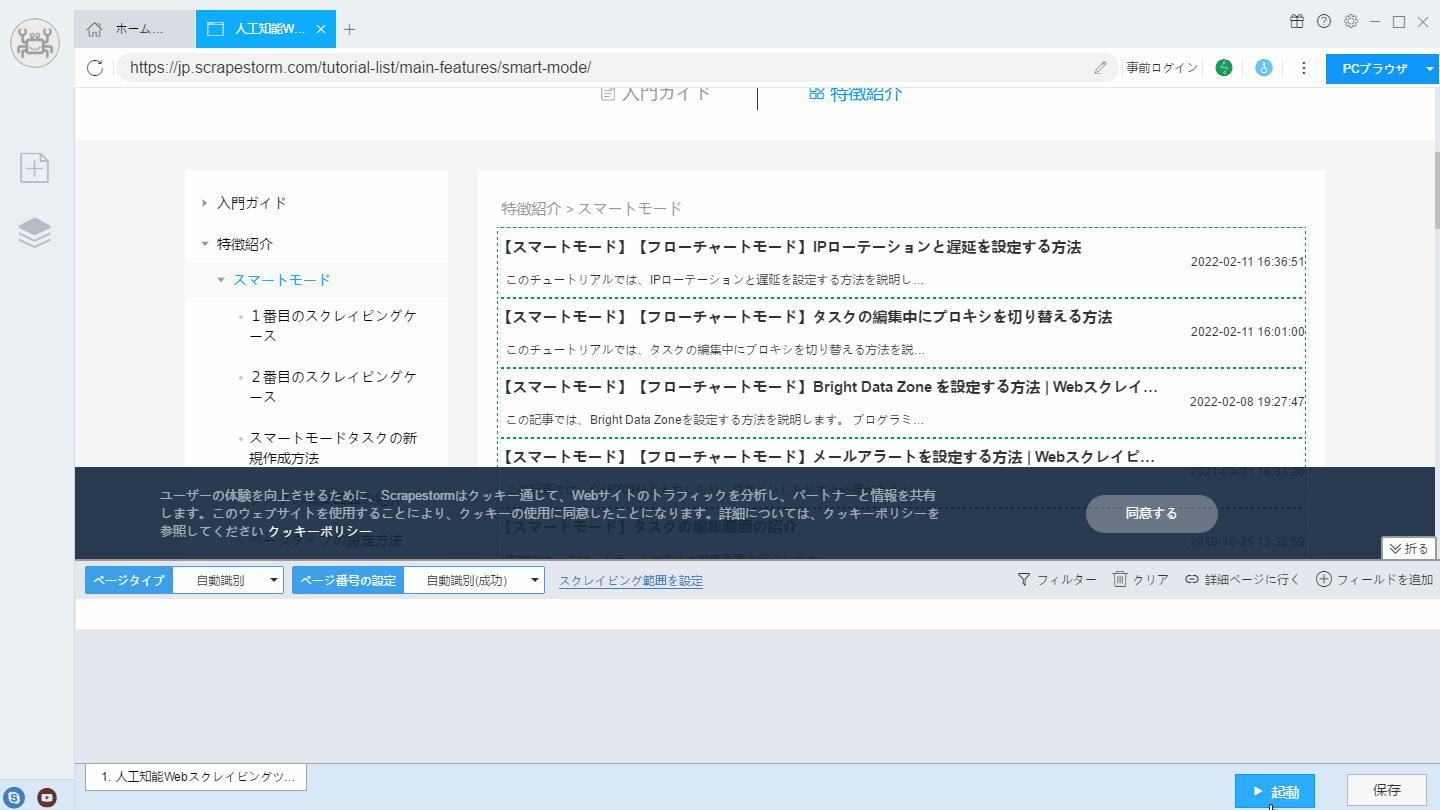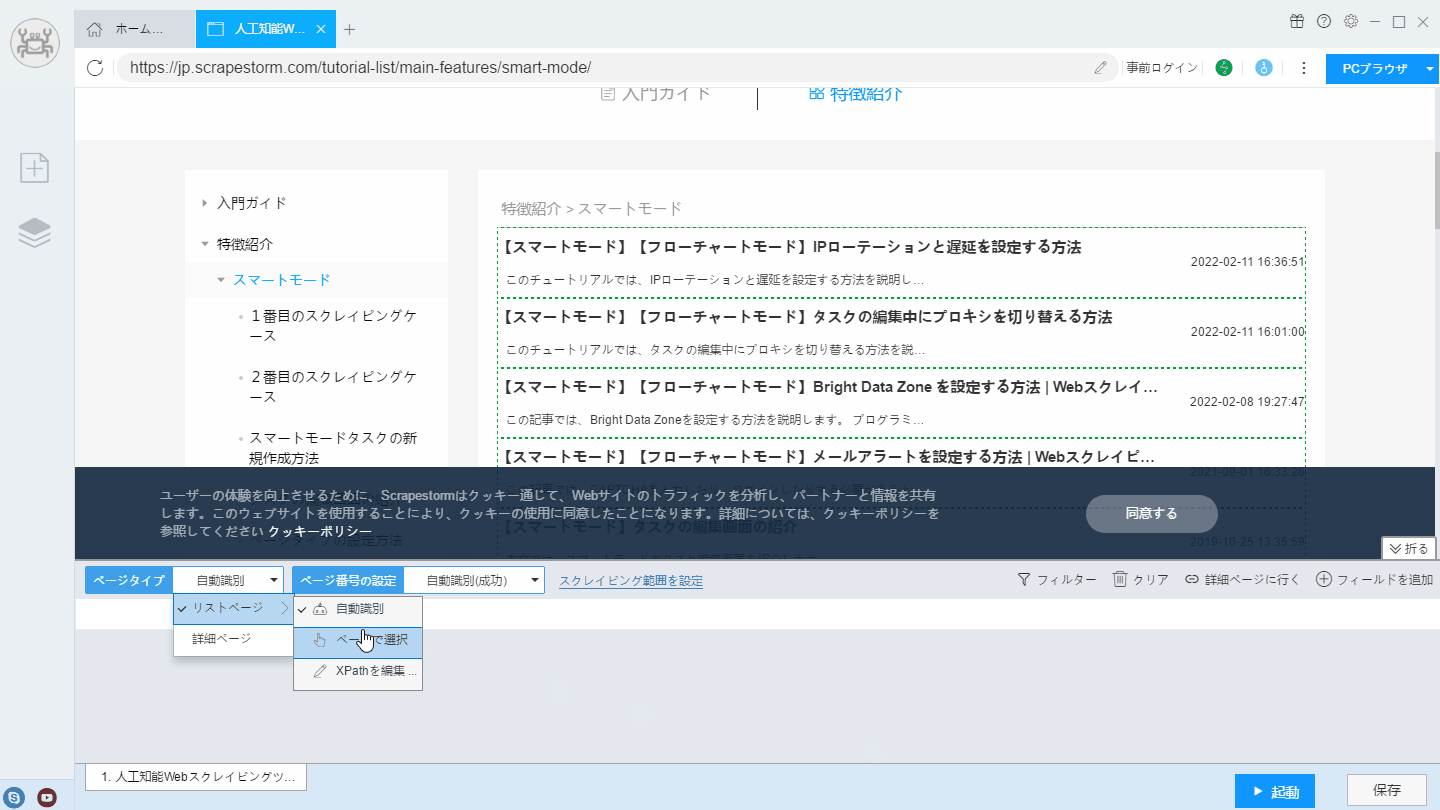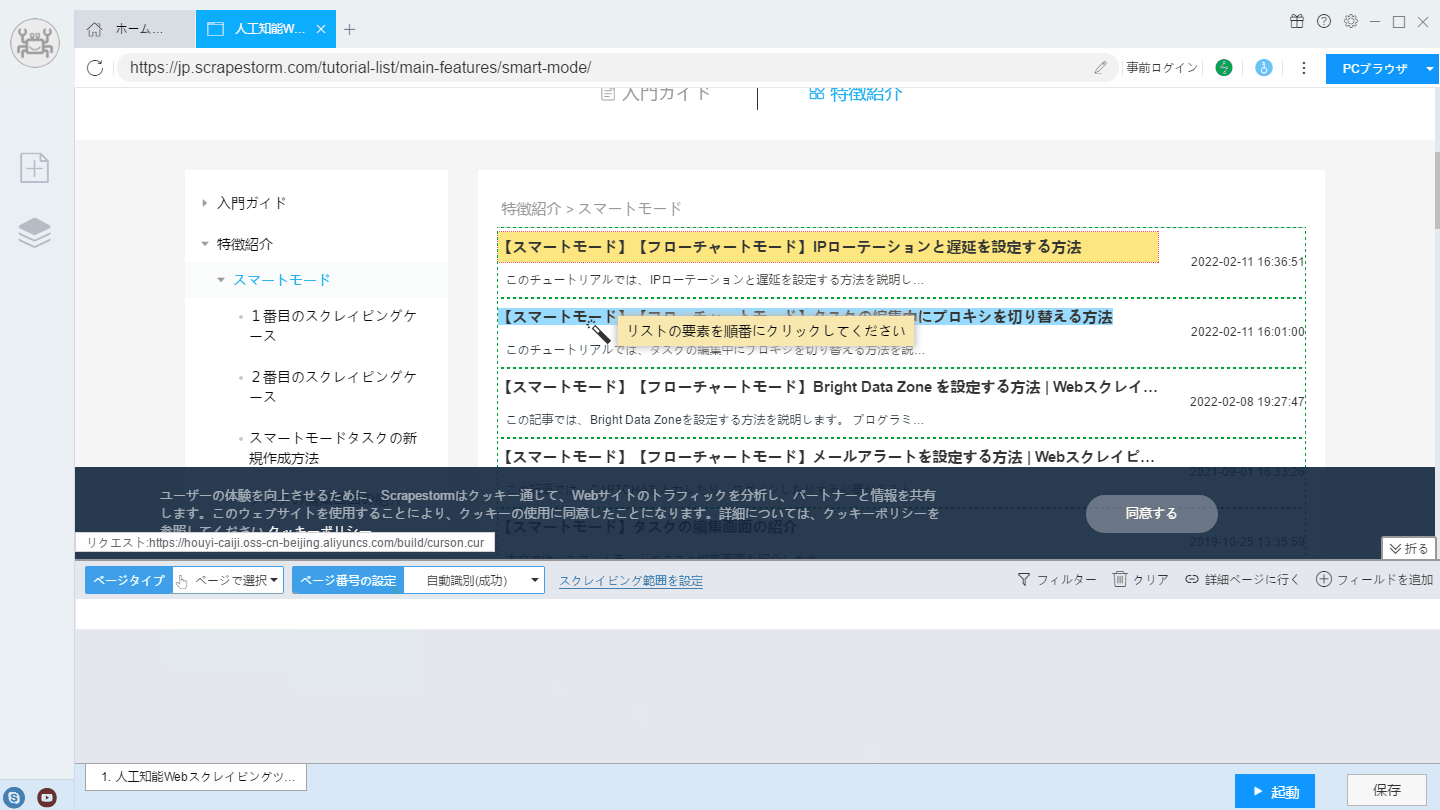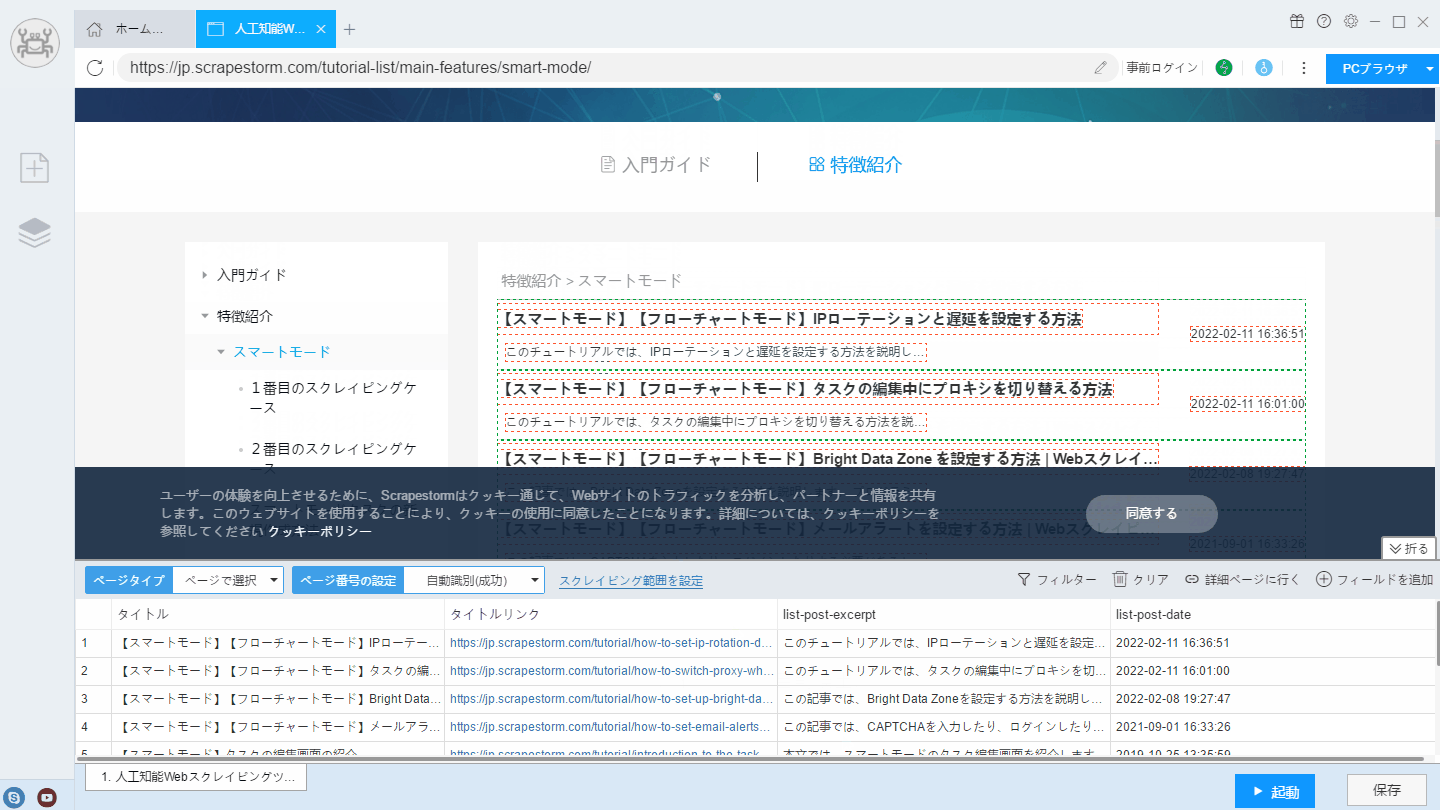
ScrapeStormのスマートモードはリストを自動的に識別します。通常、Webサイトがリストを認識すると、詳細ページのリンクも識別されます。
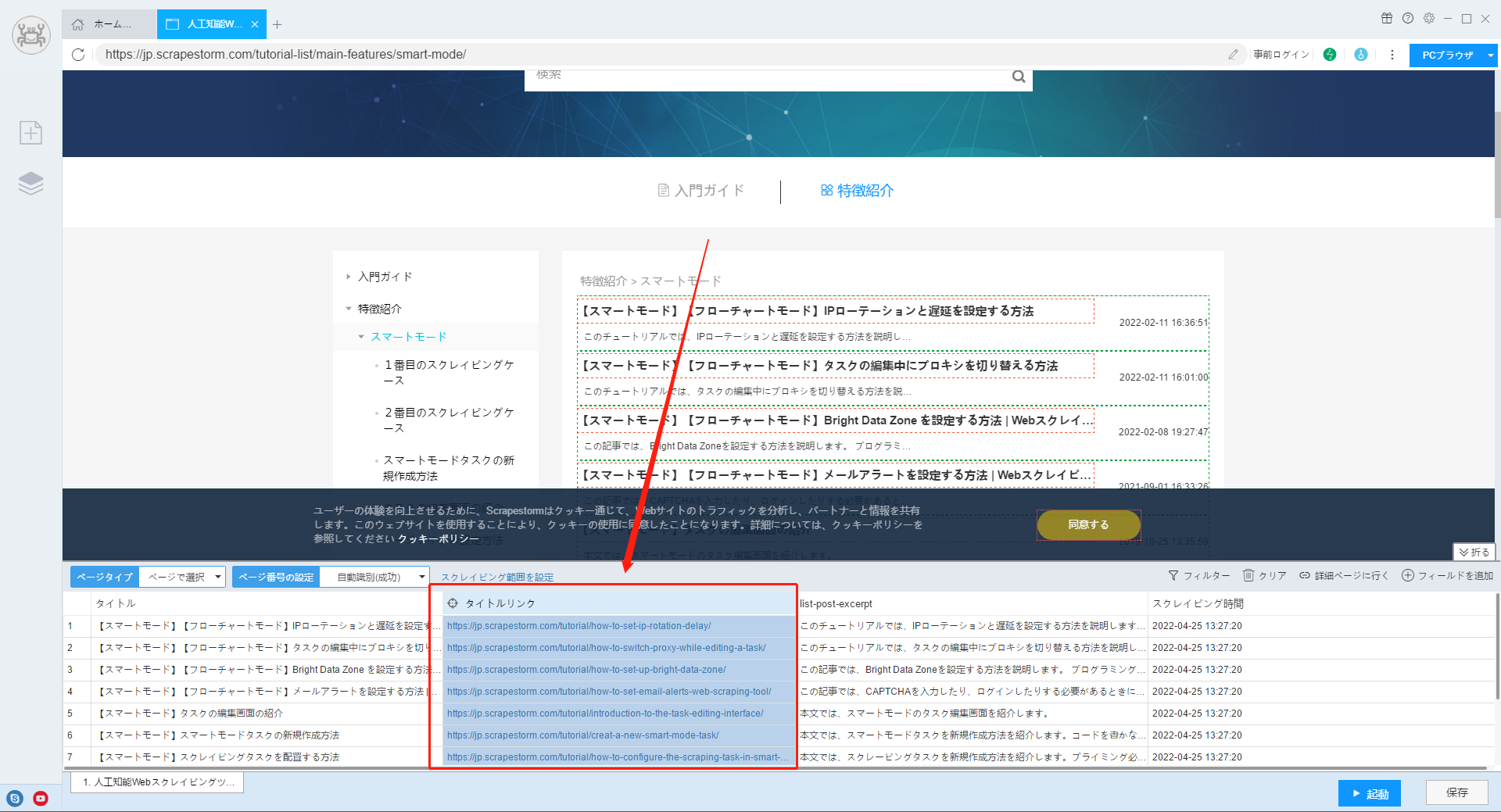
【注意】自動識別が不正確な場合は、リストの識別を手動で実行することもできます。
リストを識別のチュートリアルをご参照ください。
方法二:詳細ページに行くで獲得
リストを識別する時に、詳細ページのリンクを識別できない場合があります。このとき、「詳細ページに行く」機能を使用して詳細ページに入り、リンクを収集することができます。
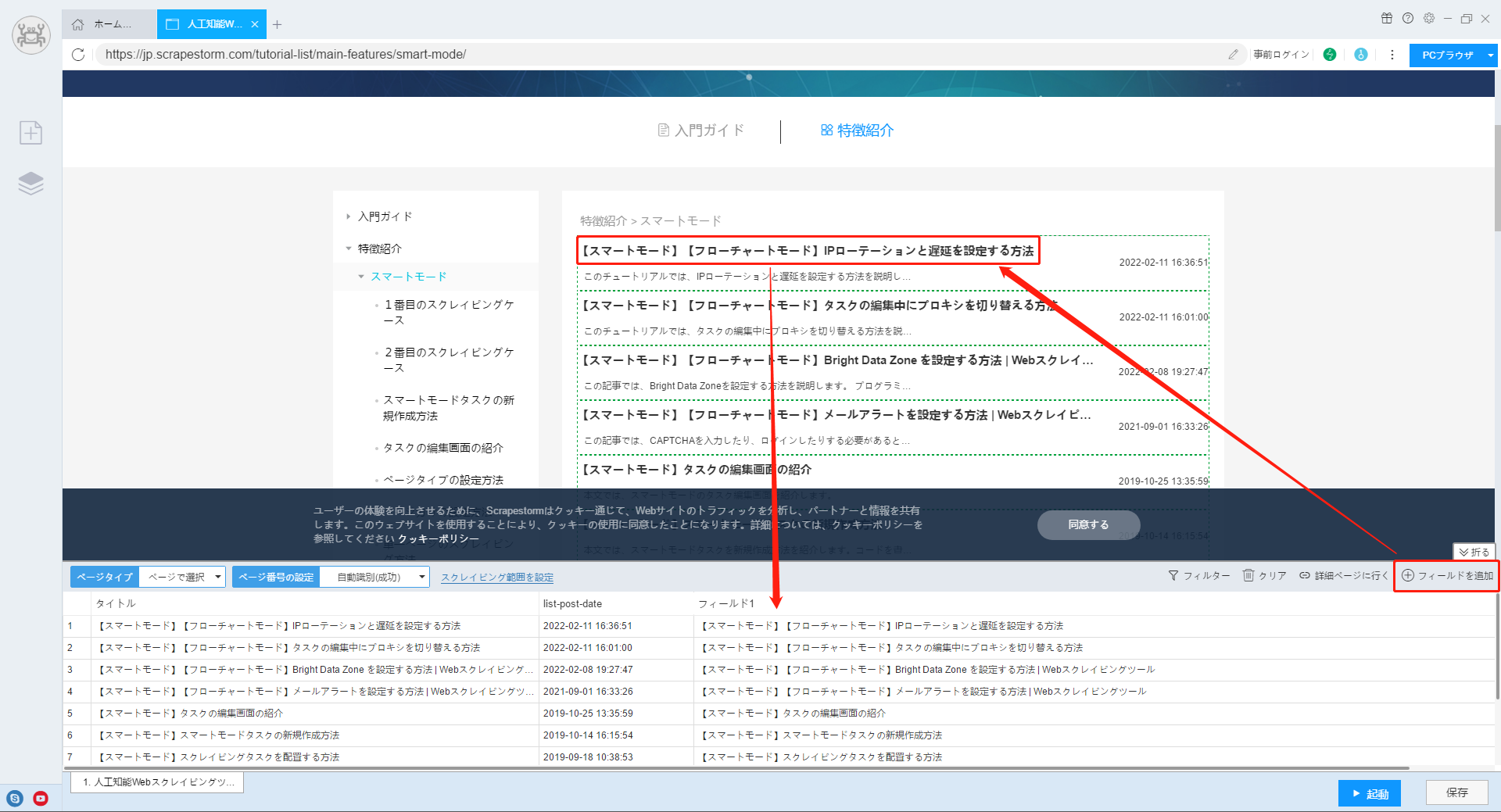
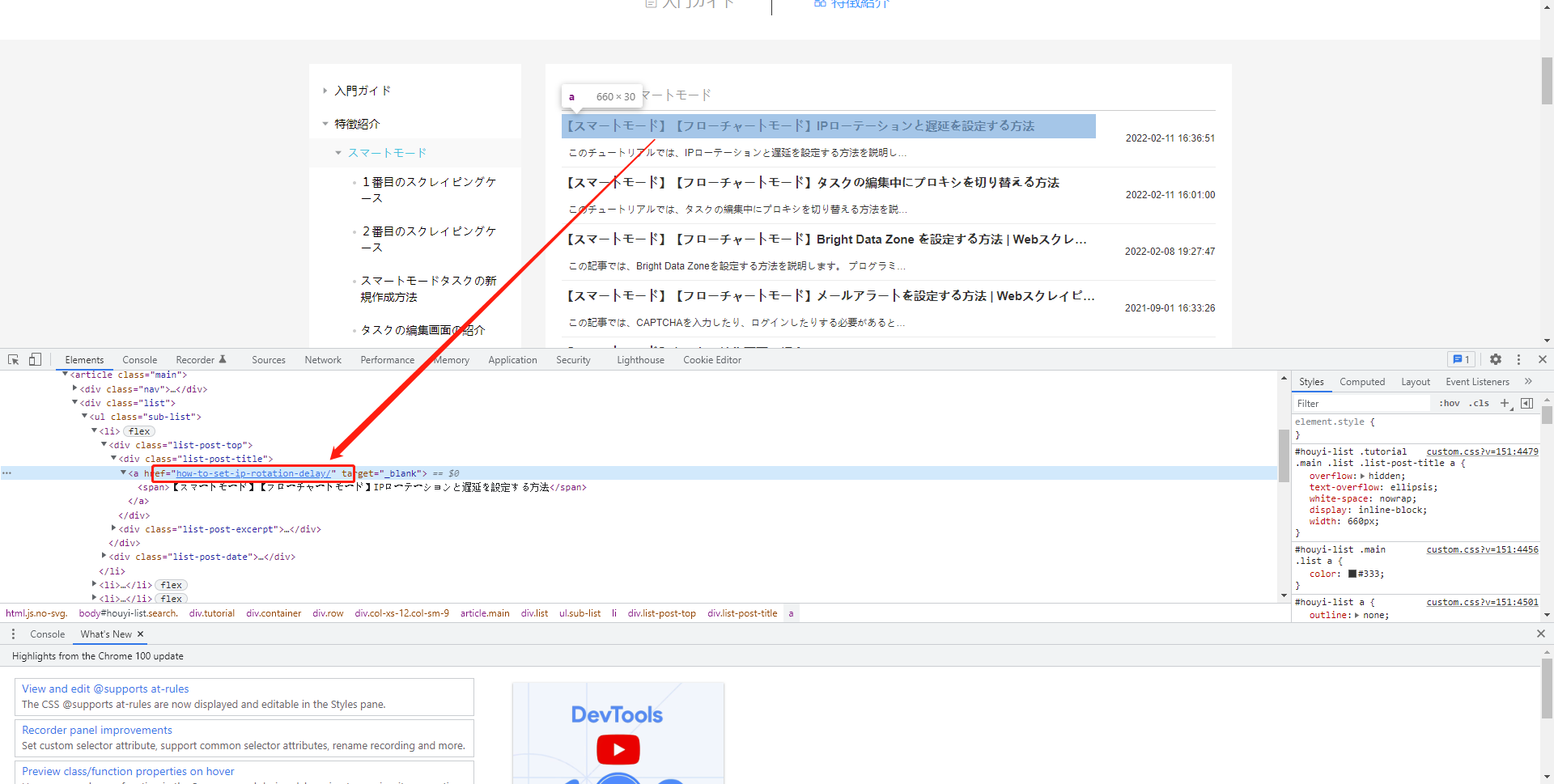
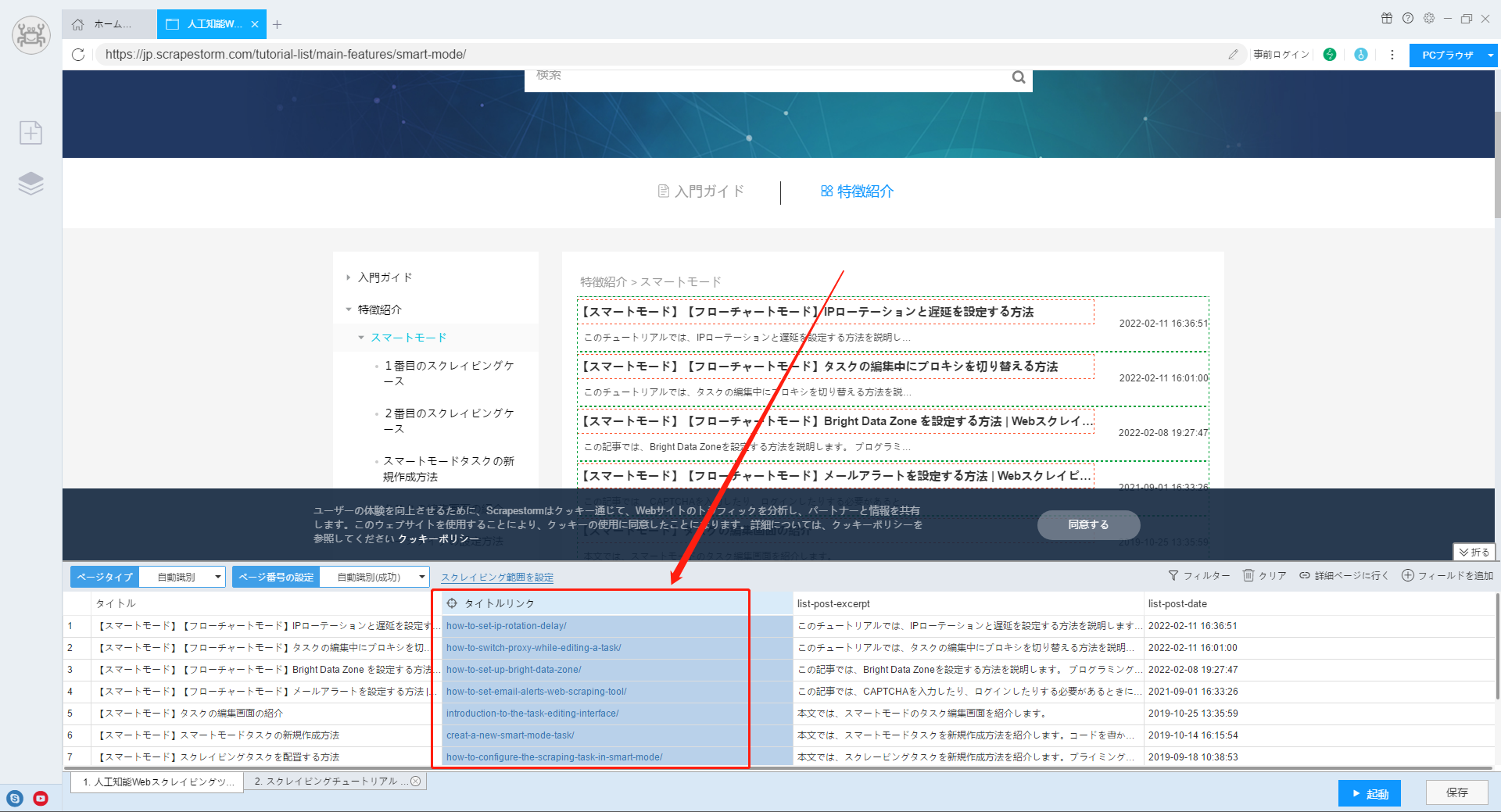
1.リストを識別した後、「フィールドを追加」機能を使用して、詳細ページへのリンクを含むデータを選択します。ソフトウェアが自動的にフィールドを生成します。
【注意】リンク付きのデータは、通常、記事のタイトルや商品名などです。ソフトウェアで確認できない場合は、ブラウザで確認できます。
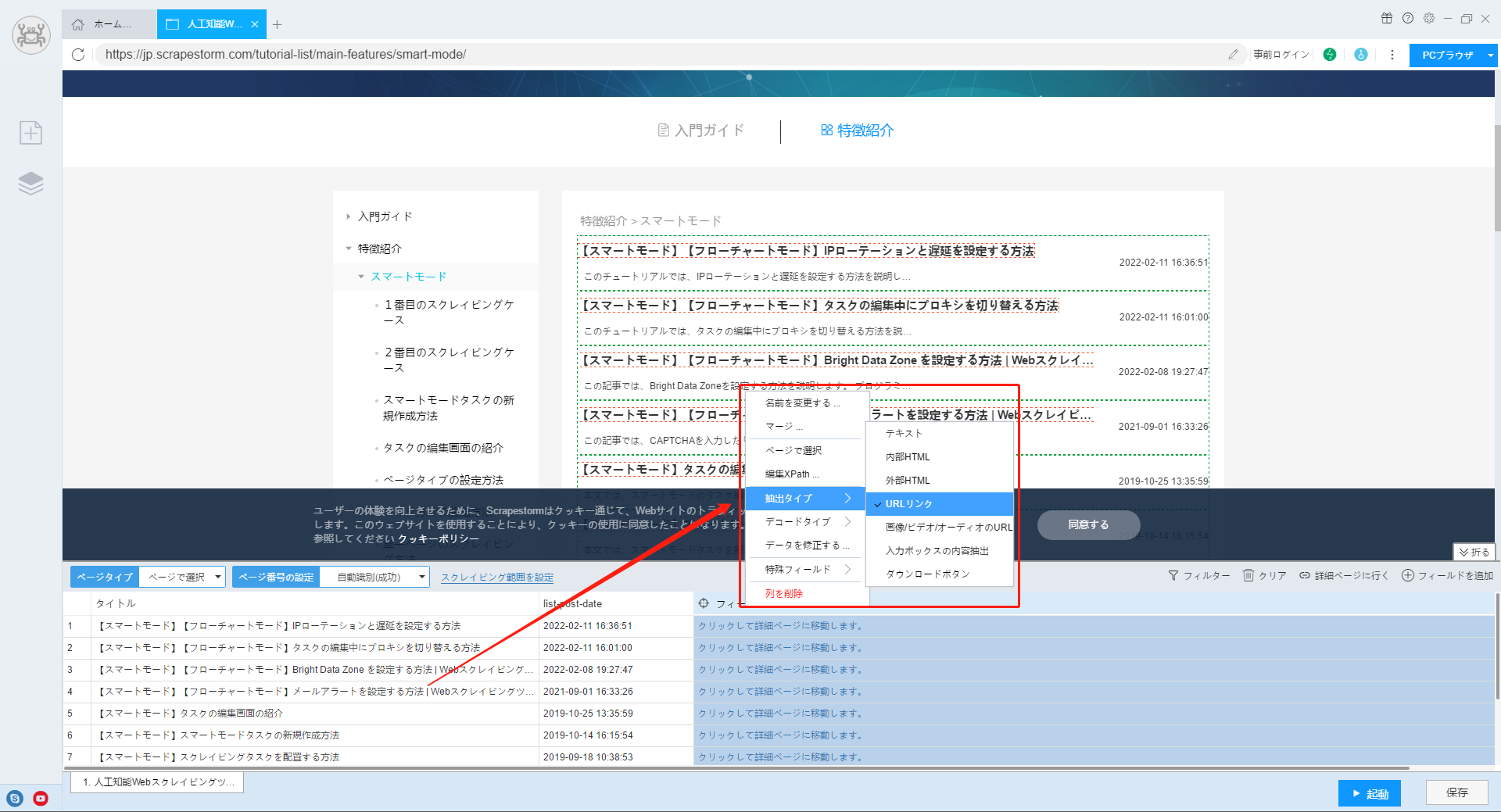
2.生成されたフィールドを右クリックし、「抽出タイプ」を設定して、「URLリンク」を選択します。
3.「詳細ページに行く」をクリックし、詳細ページに入ります。
詳細ページのチュートリアルをご参照ください。
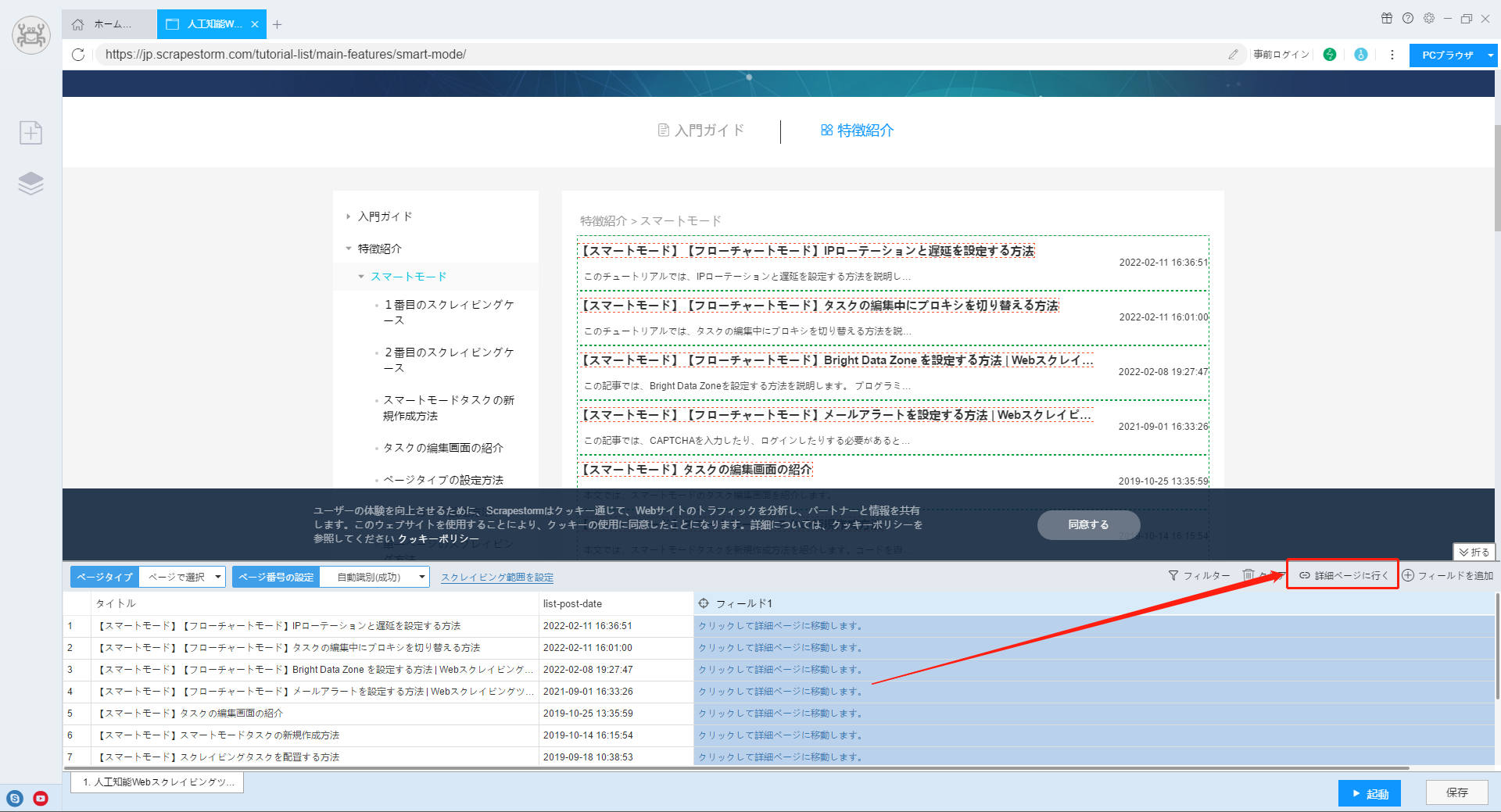
4.詳細ページに入ったら、フィールドを任意に追加し、生成されたフィールドを右クリックして「特殊フィールド」を設定し、「ページのURL」選択します。これで、詳細ページのリンクが表示されます。
方法三:詳細ページのリンクを綴る
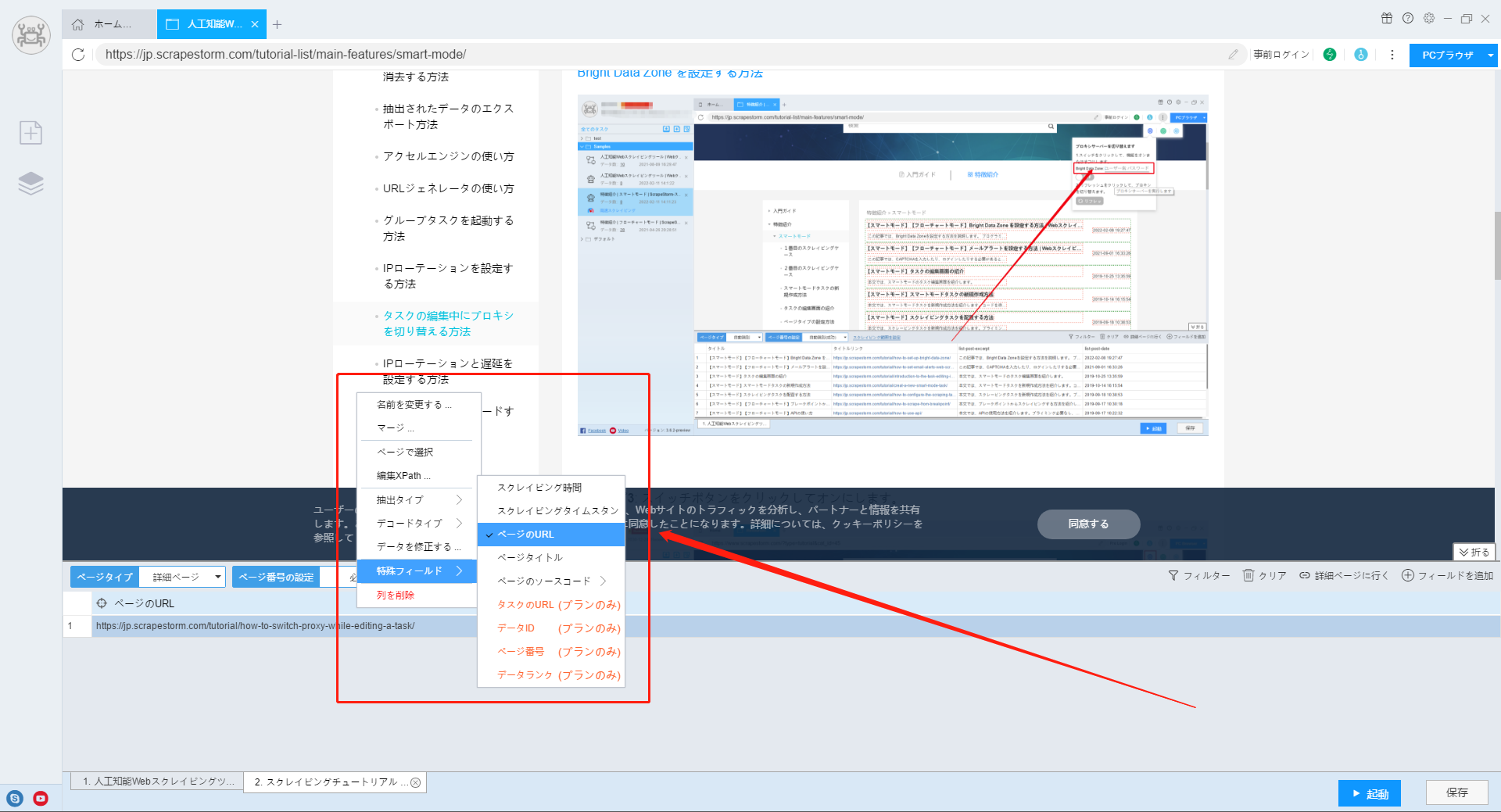
上記の方法のいずれも詳細ページのリンクを正常に収集できないが、xpathまたは正規表現を使用して詳細ページのIDまたはタイトル名等を抽出できる場合は、「データを修正する」機能によって詳細ページのリンクを綴ることができます。
【注意】XPathまたは正規表現がわからない場合は、カスタマーサービスにお問い合わせください。お問い合わせ:https://jp.scrapestorm.com/?type=contact
フィールドを右クリックし、「データを修正する」を設定して、図に示すように新しい「プレフィックスを追加」を作成します。
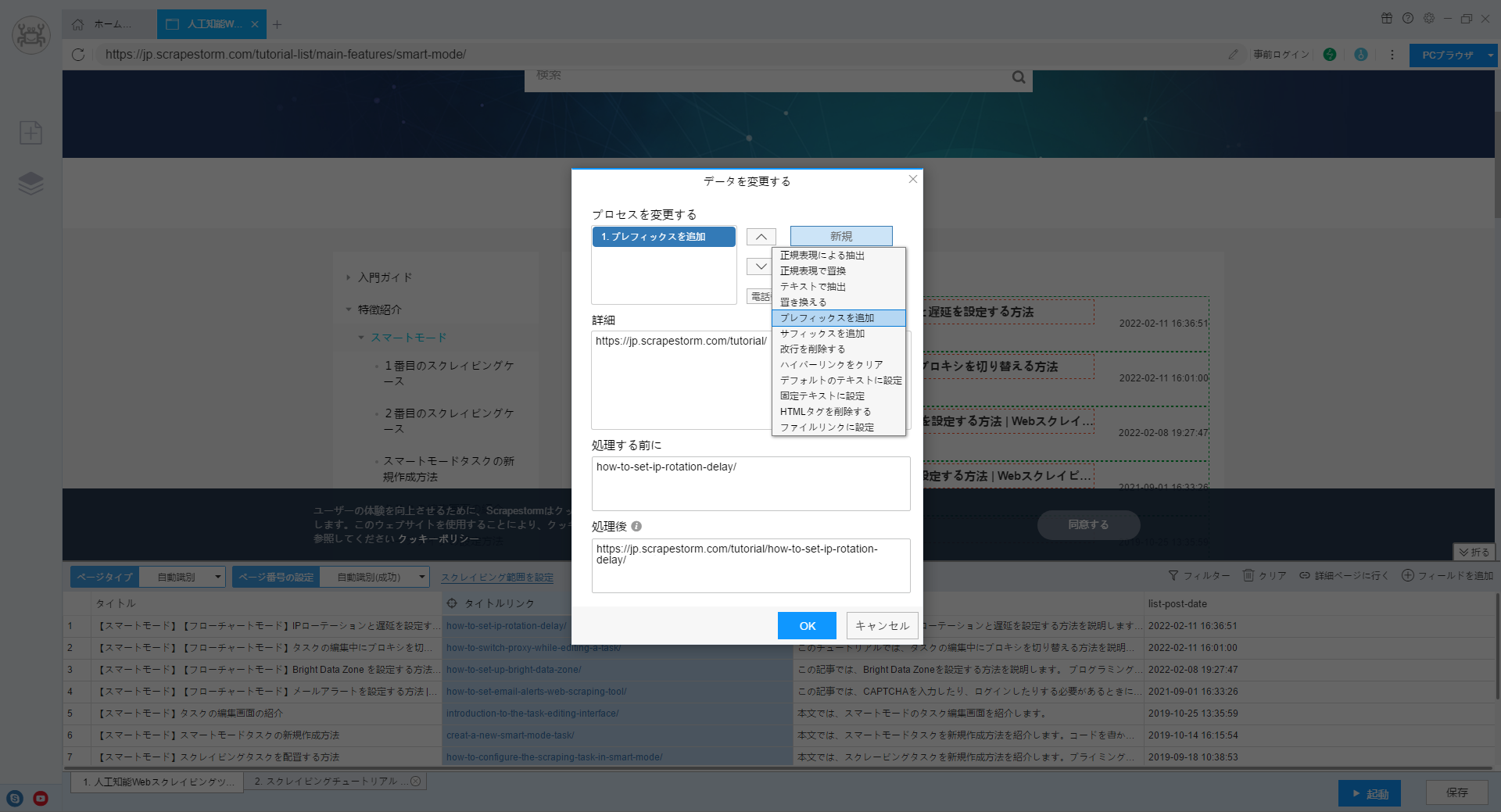
これにより、詳細ページのリンクを獲得します。