データ分類(DataClassification) | Webクローラ | ScrapeStorm
摘要:データ分類は、特定の基準または属性に従ってデータをグループ化および整理するプロセスです。 この分類は、データのタイプ、目的、特性、またはその他の関連要素に基づいて行うことができます。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
データ分類は、特定の基準または属性に従ってデータをグループ化および整理するプロセスです。 この分類は、データのタイプ、目的、特性、またはその他の関連要素に基づいて行うことができます。
適用シーン
データベース内のデータは、データの管理と取得をより効率的に行うために、日付、種類、地理的位置、その他の属性などの特定のフィールドに基づいて分類できます。 ドキュメント、ファイル、またはその他の情報をトピック、コンテンツ、または形式ごとに分類すると、見つけやすく、使用しやすくなります。 データ サイエンスと分析の分野では、データ分類はデータ パターンと洞察を探索するための基礎であり、特定の分類方法に基づいてデータ マイニングを実行できます。
メリット:分類により、データの管理と維持が容易になり、必要なデータを迅速に見つけて取得し、処理できるようになります。 さまざまなニーズに応じてデータを分類、整理し、作業効率とデータ分析の精度を向上させることができます。 データをより深く理解して活用し、パターン、傾向、つながりを発見できます。
デメリット:人が異なれば、異なる基準に従ってデータを分類する可能性があり、分類方法に主観性や不一致が生じる可能性があります。 データ量が増加するにつれて、データ分類の維持と更新には、より多くのコストと時間が必要になる場合があります。 過度にセグメント化すると、分類システムが複雑すぎて管理や使用が困難になる可能性があります。
図例
1. Amazon Macie を用いた Amazon RDS データベースのデータ分類方法。
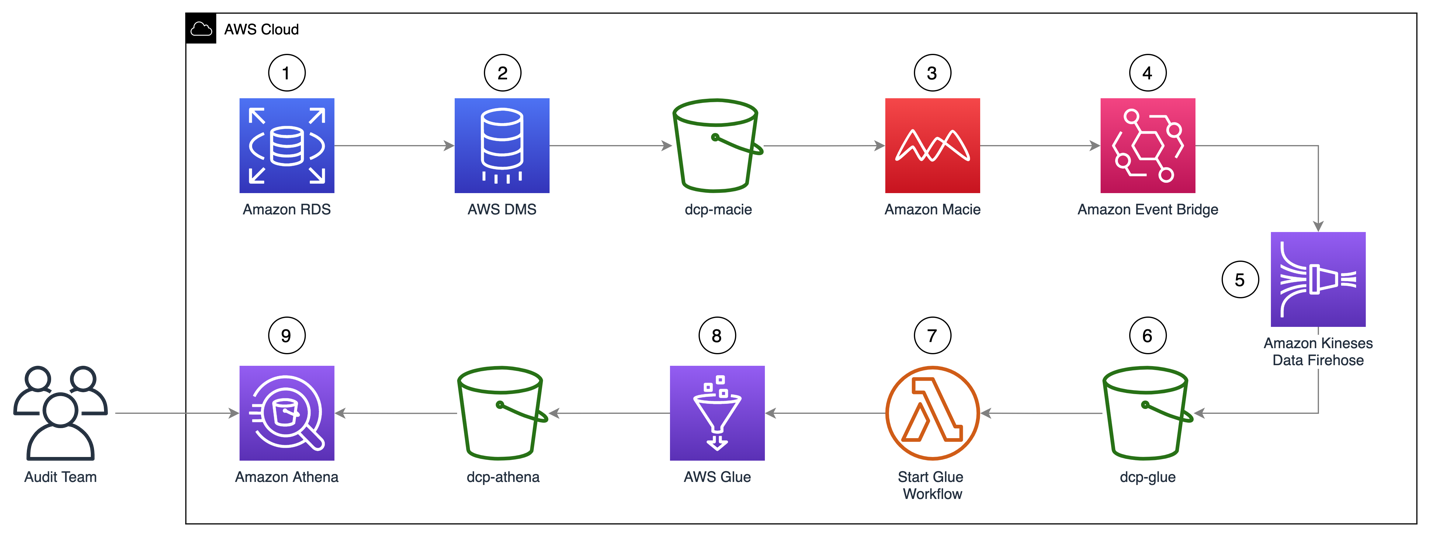
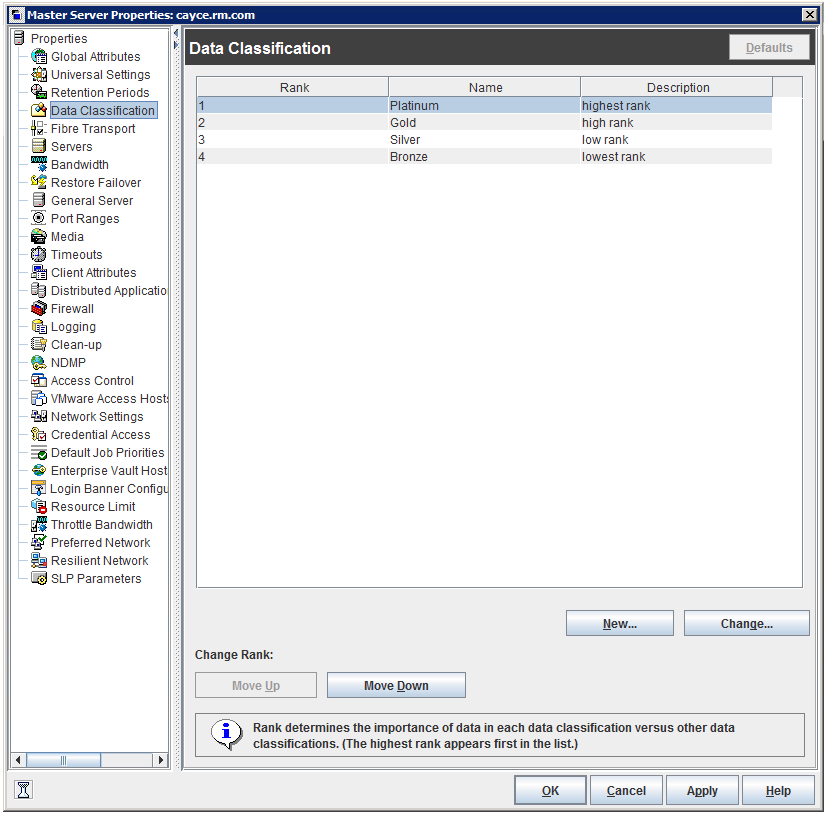
2. データの分類 (Data Classification)プロパティ。
関連記事
参考リンク
https://www.cohesity.com/jp/glossary/data-classification/
https://www.proofpoint.com/jp/threat-reference/data-classification