増分データ収集(Incremental Data Collection) | Webクローラ | ScrapeStorm
摘要:増分収集は、データ ソースの最新の変更を反映するために既存のデータを更新および維持するために使用されるデータ収集方法です。 この方法は、最初からすべてのデータを取得する完全収集とは異なりますが、増分収集は最後の収集以降に発生した変更のみを取得します。 ScrapeStorm無料ダウンロード
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。
概要
増分収集は、データ ソースの最新の変更を反映するために既存のデータを更新および維持するために使用されるデータ収集方法です。 この方法は、最初からすべてのデータを取得する完全収集とは異なりますが、増分収集は最後の収集以降に発生した変更のみを取得します。

適用シーン
増分収集は、金融取引やソーシャル メディアの更新など、リアルタイムまたはほぼリアルタイムのデータ同期が必要なシナリオに適しています。 完全収集と比較して、増分収集ではデータ送信に必要な帯域幅が削減され、ストレージ コストが削減されます。 定期的に更新されるデータを必要とするアプリケーションでは、増分収集によりデータの取得時間とリソース コストを削減できます。
メリット:増分収集により、データ送信量が削減され、収集と送信の時間が短縮されます。 また、データはほぼリアルタイムで変更を反映できると同時に、帯域幅とストレージのコストも削減できます。
デメリット:増分取得には最初の完全な取得が必要であり、遅延が長くなる可能性があります。 データ ソースの変更を監視し、追加のプログラミングと構成が必要になる場合がある増分取得プロセスを効率的に実装する必要もあります。
図例
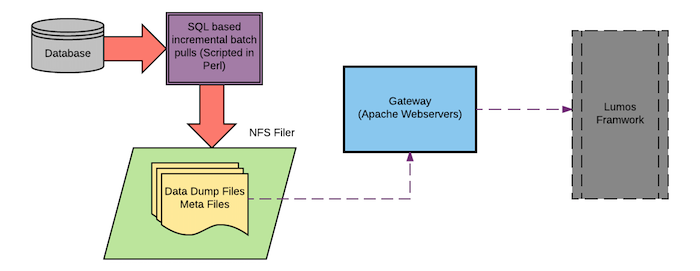
1. 増分データ収集の概略図。
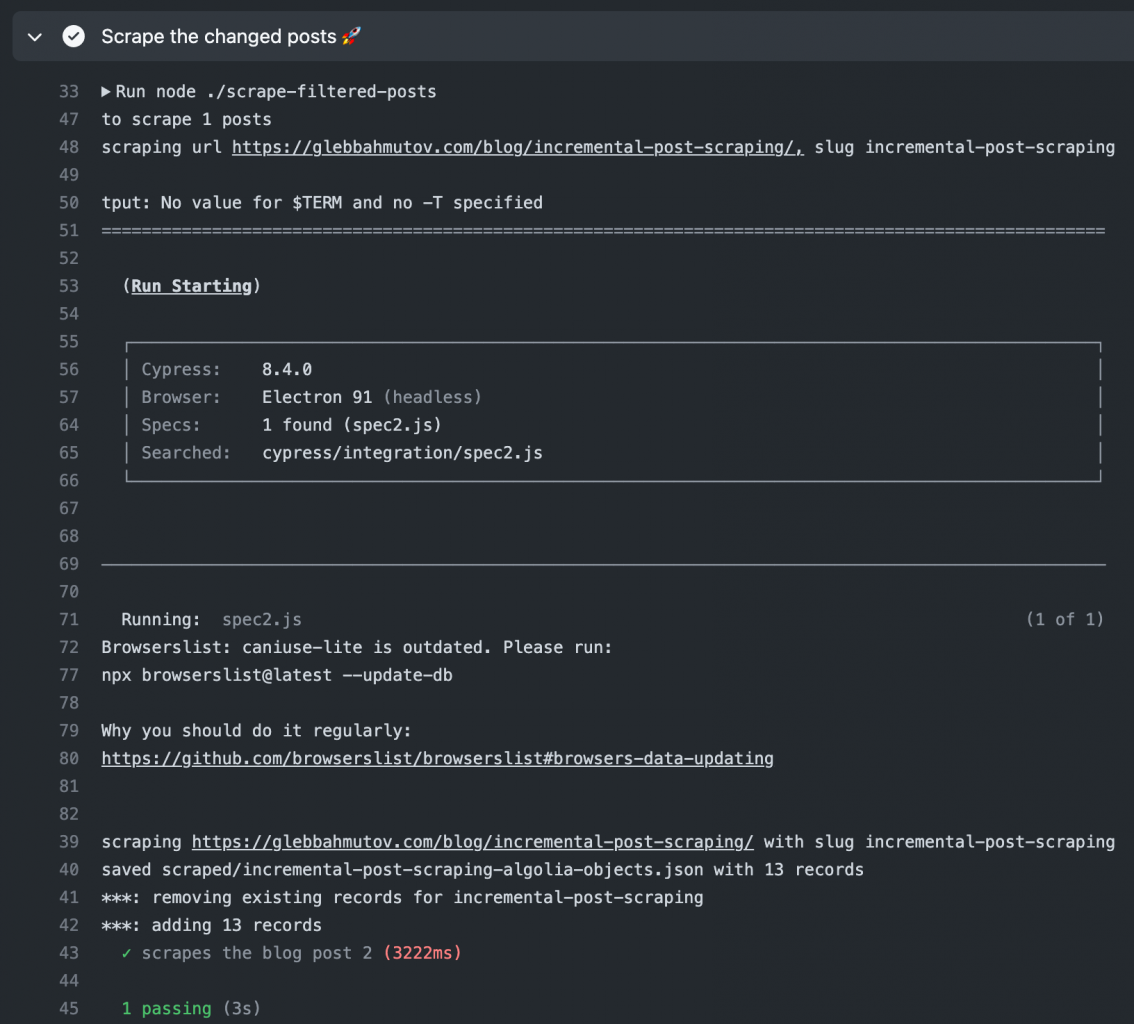
2. 増分データ収集のコードサンプル。
関連記事
参考リンク
https://www.ibm.com/docs/ja/cognos-analytics/11.0.0?topic=data-incremental-updates-aggregate-tables
https://www.ashisuto.co.jp/db_blog/article/20151102_incr_stats.html